
Timbr Semantic Layer FAQs
Timbr Intelligent Semantic Layer is an ontology-based semantic layer that serves as a semantic context layer for enterprise AI and analytics systems. It sits virtually above existing data sources, modeling business concepts, relationships, and rules directly in SQL, enabling users to query complex multi-source data without writing JOINs.
Learn more: Timbr’s Ontology-Based Semantic Layer
A semantic layer simplifies data modeling by turning raw data into consistent business concepts, relationships, and rules. It reduces SQL complexity, unifies data across sources, and ensures consistent metrics for analytics and AI.
Timbr offers a fast, easy and no-risk implementation of the semantic layer. The main reasons are that there’s no need to move data or learn any proprietary query language.
Modeling in Timbr can be done either manually or automatically from an ERD, OWL ontologies, or from data catalogs.
The mapping of the data to the intelligent semantic layer is also done either manually or semi-automatically.
Conceptual modeling is a representation of the real world. It is the first step of data modeling, a method developed to help with the design of databases and defining a formal vocabulary for the organization.
The process leading to the actual modeling and creation of databases leaves out information that is key to understanding and using data effectively. To make up for this information left behind, enterprises require coding complex queries in complex applications.
Ontologies are an effective means to re-create the information left behind, giving back business meaning to the data, simplifying data access and delivering unique analytical capabilities.
SQL ontologies are virtual ontologies built and queriable in SQL designed for mapping underlying data sources to provide common business meaning to data. SQL ontologies are exposed as virtual schemas with virtual tables (concepts) using any SQL client with JDBC/ODBC.
An ontology is a comprehensive and flexible “super-schema” for your data. Users of relational databases are accustomed to dealing with tables, columns, and relationships defined by foreign keys. An ontology takes these familiar concepts and expands them into a more dynamic and semantically rich framework.
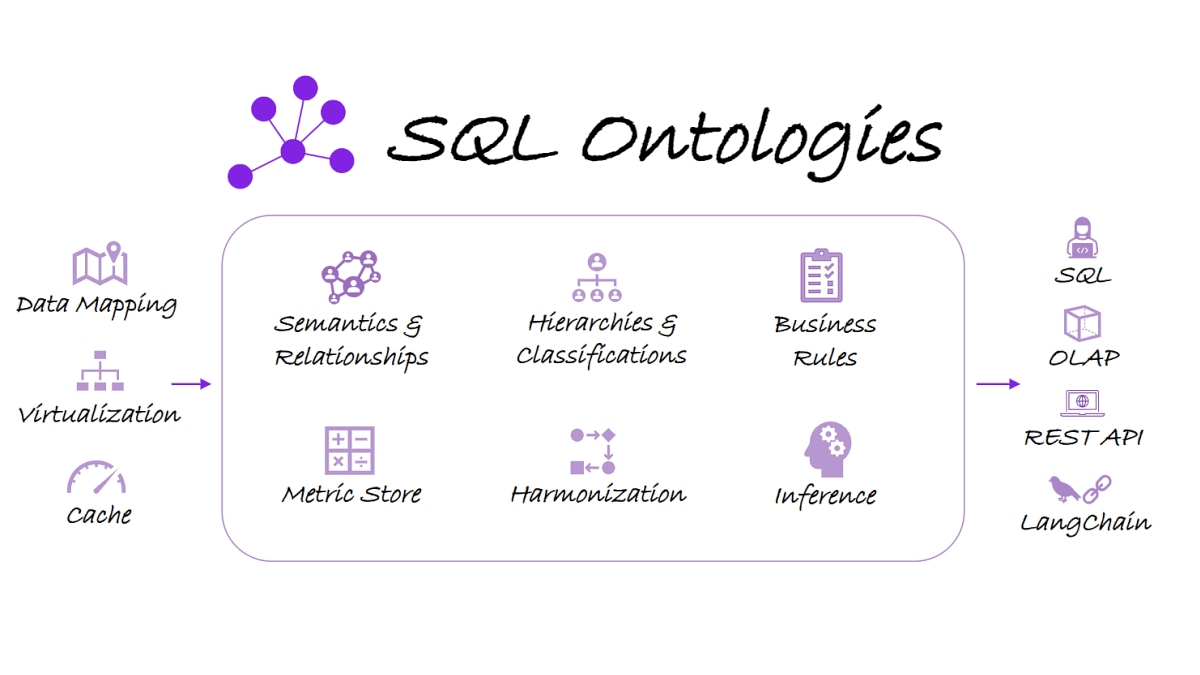
Definitions and Relationships:
-
- Concepts: Just like tables in a database, an ontology defines concepts (or classes) that represent real-world concepts. For instance, “Customer” and “Order” in an RDBMS are similar to concepts in an ontology.
- Properties (Attributes): Attributes of a table (columns) are akin to properties in an ontology. These properties describe various aspects of the concepts, like “CustomerName” or “OrderDate”.
Hierarchical Structure:
-
-
- Inheritance: Ontologies allow concepts to inherit properties from other concepts. This is like having a base table with common columns that other tables can inherit, but with more flexibility. For example, “Employee” could be a subconcept of “Person”, inheriting properties like “Name” and “Address” but also having specific properties like “EmployeeID”.
-
Semantics and Meaning:
-
- Rich Semantics: Ontologies provide a way to define rich semantics and relationships beyond simple foreign keys. They can describe how concepts relate to each other in more complex ways, such as “Customer places Order” or “Product is part of Order”.
- Data Integration: By defining these relationships and semantics, ontologies enable better data integration and interoperability, especially when combining data from different sources.
Query Flexibility:
-
- Advanced Queries: With ontologies, you can perform more advanced and meaningful queries. Instead of just retrieving data based on table joins, you can query based on the relationships and properties defined in the ontology, like “Find all orders placed by customers in California”.
Dynamic and Evolving:
-
- Extensibility: Ontologies are more adaptable to changes. Unlike rigid database schemas, you can extend an ontology by adding new entities and relationships without restructuring your entire database.
- Contextual Understanding: They also provide contextual understanding, enabling systems to reason about the data and infer new knowledge. For instance, if an ontology knows that “Managers” are a type of “Employee”, it can infer that all managers have the properties of employees.
In summary, an SQL ontology is like a supercharged schema for your data. It provides a flexible, semantically rich, and hierarchical structure that enables advanced data integration, querying, and contextual understanding, making it a powerful tool for managing and leveraging complex data relationships.

Data Graph Exploration is a unique feature of Timbr that automatically transforms non-graph data into a virtual graph to allow users to visualize and explore data relationships as a network. Data consumers, business analysts and domain experts can discover insights and answer questions without need of any coding. You can play with a demo here.
Semantic SQL is SQL powered by explicit relationshipsto avoid useof Joins and Union statements. The semantic SQL queries are formulated in standard SQL and query the semantic business model (ontology) mapped to the data, instead of querying the data directly. It is also used to query Views created with the semantic model. Users benefit from a 360° view of data, graph traversals and semantic reasoning features, so SQL queries become easy to understand and query size is reduced significantly. Learn more
The SQL Knowledge Graph implements the semantic web ontologies in standard SQL, described in detail in this blog post. It has three components: (i) a virtual SQL ontology of connected, context-enriched concepts with inference capabilities and graph analytics features; (ii) a mapping of the virtual SQL ontologies to existing databases accessible in SQL and, (iii) a query execution engine that translates SQL queries of the ontology into SQL queries pushed down to the underlying databases. The SQL Knowledge Graph closes the gap between the most advanced technology for knowledge representation and enterprise databases/legacy systems/data warehouses/data lakes, to empower data teams to rapidly and conveniently deploy modern, easily consumable architectures including data fabric, data mesh and many others without need to change DBMS infrastructure.
Creating a SQL Knowledge Graph is a simple process:
1. Connect your databases to the virtual layer using JDBC connectors.
2. Model the SQL ontology visually or using Timbr SQL DDL statements, or import from other sources (data catalogs, OWL ontologies, ERD tools).
3. Map the ontology concepts to the data.
That’s it, your SQL Knowledge Graph is ready for use and can start delivering unique insights via SQL queries, graph data exploration, your BI tools, or using Timbr’s embedded charts and dashboard module.
No, you just need a database, Timbr will guide you through the rest of the simple process.
The SQL Knowledge Graph serves as a virtual graph for all the enterprise data engines to simplify SQL queries, implement graph traversals in SQL and manage the enterprise data conveniently to deliver advanced analytics conveniently and with minimal effort. Organizations use it to integrate, analyze and explore their data sources and silos of information without the need to move or transform data. Data consumers benefit from a 360° access to data to get fast answers to key business questions. By querying concepts instead of the tables, SQL queries are reduced in length and complexity significantly. The SQL Knowledge Graph seamlessly integrates with popular business intelligence tools so business analysts can focus on the business questions and derive deeper insights.
Timbr is named after Tim Berners Lee who, together with Timbr.ai’s advisor Jim Hendler, pioneered the Semantic Web.
Timbr is not a database. Timbr is a platform used for creating virtual SQL Knowledge Graphs that enable semantic (ontology-based) graph capabilities on existing data engines (data warehouses and data lakes). The SQL Knowledge Graphs integrate data sources into a semantic data fabric queryable in SQL. Timbr does not require to copy or transform data (no ETL operations), no new DBMS infrastructure and no new skills as required by graph databases. For more extensive explanation please read this blog.
No, it is not possible. Property graphs use proprietary query languages lacking in semantics (unlike Knowledge Graphs which are based on RDF, SPARQL and OWL). Currently, Timbr works with data engines that support SQL (mainly data warehouses and data lakes).
There’s no community version of Timbr, but any organization with a use-case in mind can rapidly test it with a Timbr Startup Plan.
Timbr enables creation of Knowledge Graphs on top of any data source, without need of a graph database.
Creating a Knowledge Graph in Timbr involves 5 simple steps:
- Name your Knowledge Graph.
- Connect your data source(s) (see https://timbr.ai/db_integrations/).
- Generate your ontology (semantic data model) – this can be done automatically, semi-automaticlly, visually (no-code) or with DDL commands.
- Map data to the ontology – done automatically, semi-automatically or visually (no-code).
- Customize adding concepts and relationships as needed.
That’s it! you can start consuming your data with code (no-JOINS SQL, Phython, Scala R or Java) or by connecting your favorite BI tool, doing graph exploration of data or using Timbr’s unique REST API.
Watch this video that shows how easy it is to create and start using your SQL Knowledge Graph.
Learn about the Timbr data fabric use case.
Gartner describes the data fabric architecture as the means of supporting “frictionless access and sharing of data in a distributed network environment.” To make this architecture work, it is necessary to implement a means to understand and assembly heterogeneous data by providing it with business meaning and flexibly integrating sources of any structural type. This is challenging due to several reasons, starting from the constraints of the architectural alternatives, and ending with the complexity to understand and query the aggregated sources.
The available options haven’t changed much in the last decade: Consolidating data into a data warehouse or graph-structured database, federating reporting, and data federation. Each alternative introduces implementation and operational constraints that involve investments in infrastructure and maintenance and varied skill sets. Moreover, till now there hasn’t been an integrative solution that resolves both the architectural and the “last mile” usability challenges, that is, encapsulating the complexity of the solution so data consumers across the enterprise conveniently gain a 360° view of data and easily generate complex queries to deliver advanced analytics and reporting conveniently and fast.
Data virtualization solutions are a viable solution to this challenge but their use is costly because of the continuous maintenance required to maintain indexes and because of the lack of relationship-rich semantic capabilities which are key to reduce complexity for end users and speed up analytics that make use of dynamic data sources.
The semantic data fabric is a flexible, reusable layer and set of data services used as the single source providing universal meaning and context to data for the entire organization. The data fabric integrates on-premise and cloud data sources in use by the organization, handing them semantic capabilities to provide answers to complex queries and to facilitate understanding and use of data. It provides consistent capabilities across on-premises and multiple cloud environments to accelerate digital transformation. Timbr enables the fastest and most convenient implementation of semantic data fabric connected to your cloud and on-premise databases and business intelligence tools. Contact us to schedule a demo.
Timbr enables knowledge representation and reasoning – a field of artificial intelligence, in SQL.
Timbr’s AI features include:
- Logical concept/object compositions combining objects or data types into more complex ones.
- Contextual modeling that enables contextual adaptation required to construct models for classes of real-world phenomena.
- Composition of semantic relationships.
- A semantic reasoner that infers knowledge from semantic relationships.
Knowledge representation is the field of artificial intelligence (AI) dedicated to representing information about the world in a form that a computer system can utilize to solve complex tasks such as diagnosing a medical condition or having a dialog in a natural language. Knowledge representation incorporates findings from psychology about how humans solve problems and represent knowledge in order to design formalisms that will make complex systems easier to design and build. Knowledge representation and reasoning also incorporates findings from logic to automate various kinds of reasoning, such as the application of rules or the relations of sets and subsets (Wikipedia).
Translated for the use of enterprises, knowledge representation provides the most efficient means for non-technical data consumers to access and retrieve data stored in databases (in the form of tables and columns for example), using abstract concepts that represent the real world (known as semantics in knowledge representation), such as “customer”, “product”, “employee”, “asset”, etc. This need arises from the fact that databases do not provide a means to use such concepts to give uniform meaning to data, because real world concepts such as “customer”, “product”, etc. are usually contained in several tables and columns or even multiple databases which are inaccessible to non-technical data consumers.
A virtual semantic layer virtually integrates heterogeneous data from many sources and provides a common meaning to linked datasets. The semantic layer acts as an intermediary between data consumers and enterprise data sources, simplifying the underlying data architecture. When users or their analytics tools submit SQL queries, the semantic layer processes these queries across all data sources, regardless of their location, without necessitating any data movement.
By providing end users with a single source of truth, the semantic layer eliminates data silos, offering a comprehensive view of data across the enterprise and empowering data-driven decision-making.
Timbr’s Master Data Management is stored in a git. Users can connect their own git, or instead use the git server that comes with Timbr. All the different tables will be stored in the git. When querying the data later users don’t need to query the git each time, instead, they can cache the data in Timbr.
SQL access to graph based solutions means that queries are created in SQL and then converted into SPARQL or other graph query language. For the most part, this means that there’s a need to create in advance a set of SPARQL queries or components which relate to SQL query statements, so constant maintenance and availability of SPARQL skilled personnel is required. In addition, the data is stored in a graph database so there’s a constant need to ETL data from the source to graph format.
In the case of a SQL knowledge graph, semantic SQL queries use the standard SQL commands and are not transalated into a separate graph query language. The data itself remains on site without need to be transformed.
A knowledge graph is a knowledge base that uses a graph-structured data model or topology to integrate data. Knowledge graphs are often used to store interlinked descriptions of objects, events or concepts with free-form semantics. Knowledge graphs use ontologies to put data in context via linking and semantic metadata providing a framework for data integration, unification, analytics and sharing.
They are also prominently associated with and used by Google, Bing, and Yahoo, and with question-answering services such as Google Assistant, Siri and Alexa. All these examples were developed with proprietary tools.
For organizations that look to benefit from knowledge graphs, the available solutions in the market require significant changes in their IT departments. This is due to the fact that most of the data in the world is stored in formats that are not compatible with the format in which data is stored in knowledge graphs, so data needs to be extracted from its current DBMS, transformed to a new format and loaded into a separate, suitable DBMS. Another reason being is that to use knowledge graphs, data engineers and consumers need to acquire news skills to model in OWL and query in SPARQL.
Different from most other solutions, the Timbr SQL Knowledge Graph platform creates a virtual layer that works in standard SQL to seamlessly connect to existing databases and is implemented without requiring new skills.
Contact us to learn how Timbr can help your organization join the knowledge revolution.
No. With Timbr a user can map multiple tables from multiple data sources to the same concept. Therefore, users can leave their data wherever it is and just use Timbr’s data mapping tool to conveniently map data from the various data sources to the ontology model.
Yes. Timbr’s default implementation for graph algorithms is networkX and it happens automatically, meaning that when a user writes an SQL query Timbr automatically runs the algorithm behind the scenes. Timbr also supports Nvidia’s Cugraph (GPU) enabling graph algorithms with advanced performance.
Yes, any tool that can create an ERD from a JDBC connection can also create an ERD from a Timbr ontology.
- Computing power depending on the application size:
Small-Medium: 4 CPU 16 GB RAM server.
Large : 8 CPU 32 GB RAM server. - Deployment options (Docker or Kubernetes):
Docker/Linux: Linux image or automatic deployment via docker-compose can be installed on any Linux server (you can extend our YAML to add your security protocols, configurations, and customizations. - Platform requirements:
List of databases with type and version information to validate connectors.
Timbr MySQL metadata DB (mandatory – configurable as a container or managed externally).
Traditional Semantic Web ontologies provide a structured framework for representing knowledge, enabling interoperability and reasoning. Key features include:
- Conceptual Framework: Defines entities, attributes, and hierarchical relationships.
- Rich Relationships: Links concepts (e.g., “is-a,” “part-of”) for advanced reasoning.
- Interoperability: Integrates heterogeneous data with a shared semantic model.
- Machine Readability: Encodes data in standards like RDF/OWL for AI and automation.
- Reasoning and Inference: Enables discovery of implicit knowledge.
- Scalability: Supports large, complex datasets with extensible, modular designs.
Integrating Semantic Web ontologies with relational or SQL-based systems poses several challenges:
- Data Model Mismatch: Relational models use tables and schema, while ontologies focus on graphs and flexible hierarchies.
- Performance Overhead: Querying ontologies (e.g., SPARQL) can be slower than optimized SQL queries.
- Complexity of Integration: Bridging RDF/OWL with SQL storage requires specialized middleware or mapping frameworks (e.g., R2RML).
- Skill Gap: Teams often lack expertise in semantic technologies.
- Legacy System Constraints: Traditional systems may resist the flexibility needed for ontology-based integration.
- Data Governance: Aligning ontology standards with existing enterprise policies can be challenging.
To address these issues, enterprises often adopt hybrid approaches, leveraging tools like graph databases, ontology mappings, and semantic layers to bridge the gap between traditional and semantic models.
Timbr Modeling FAQs
A semantic layer simplifies data modeling by turning raw data into consistent business concepts, relationships, and rules. It reduces SQL complexity, unifies data across sources, and ensures consistent metrics for analytics and AI.
Timbr offers a fast, easy and no-risk implementation of the semantic layer. The main reasons are that there’s no need to move data or learn any proprietary query language.
Modeling in Timbr can be done either manually or automatically from an ERD, OWL ontologies, or from data catalogs.
The mapping of the data to the intelligent semantic layer is also done either manually or semi-automatically.
Timbr offers a visual ontology modeler as well as a SQL DDL editor to easily model the ontology. Timbr allows to conveniently generate concepts from the database schema, data catalogs or through importing existing OWL ontologies.
Timbr offers a visual data mapper to manually or semi-automatically select tables and columns from the database, as well as the option for coders to conveniently use SQL DDL statements. Timbr can filter, clean and transfer the data that is been mapped to the ontology. No need for ETL operations.
Timbr supports applying rules to concepts to classify the data or embed business logic in the ontology.
For Example:
Adult: Person where age > 21
ExpensiveProduct: Product where price > 1000.
Timbr implements the Semantic Web in SQL. For this reason there’s a correspondence between OWL ontologies and SQL ontologies that is used by Timbr to make the transformation. Timbr.ai provides professional services to translate OWL ontologies into SQL ontologies for seamless integration with the existing enterprise SQL ecosystem. Contact us.
Yes, Timbr is transparent to the SQL user and uses the same dialect and syntax as the underlying database. You can add hints and use all the underlying database functionality.
Timbr allows creating virtual PKs for concepts (used as unique identifiers), and FK to PKs in the ontology (used as relationships between concepts). As long as the ontology author maps the physical tables PKs to the ontology PKs, client join will follow these declarations. In the ontology, you can create relationships between concepts using FK statements. In each relationship, you specify the properties in the ontology that represent the relationship (used for the JOIN).
Yes, Timbr is accessible in JDBC/ODBC and the ontology can be created programmatically using Timbr SQL DDL statements:
CREATE CONCEPT (extension of CREATE TABLE statement)
CREATE MAPPING (extension of CREATE VIEW statement)
In many cases, we build small scripts to generate parts of the ontology programmatically.
The ontology definition is in SQL DDL statements and it is stored in Timbr’s internal metadata DB.
You can access the ontology definitions using Timbr system tables: SYS_CONCEPTS, SYS_RELATIONSHIPS, SYS_PROPERTIES, SYS_ONTOLOGY, SYS_MAPPINGS, etc.
Timbr enables creation of Knowledge Graphs on top of any data source, without need of a graph database.
Creating a Knowledge Graph in Timbr involves 5 simple steps:
- Name your Knowledge Graph.
- Connect your data source(s) (see https://timbr.ai/db_integrations/).
- Generate your ontology (semantic data model) – this can be done automatically, semi-automaticlly, visually (no-code) or with DDL commands.
- Map data to the ontology – done automatically, semi-automatically or visually (no-code).
- Customize adding concepts and relationships as needed.
That’s it! you can start consuming your data with code (no-JOINS SQL, Phython, Scala R or Java) or by connecting your favorite BI tool, doing graph exploration of data or using Timbr’s unique REST API.
Watch this video that shows how easy it is to create and start using your SQL Knowledge Graph.
No, any change to the ontology is immediately reflected to all the users. This means no downtime.
We plan to support GIT-like behavior, so ontologies can be deployed in a similar way to code.
Knowledge representation is the field of artificial intelligence (AI) dedicated to representing information about the world in a form that a computer system can utilize to solve complex tasks such as diagnosing a medical condition or having a dialog in a natural language. Knowledge representation incorporates findings from psychology about how humans solve problems and represent knowledge in order to design formalisms that will make complex systems easier to design and build. Knowledge representation and reasoning also incorporates findings from logic to automate various kinds of reasoning, such as the application of rules or the relations of sets and subsets (Wikipedia).
Translated for the use of enterprises, knowledge representation provides the most efficient means for non-technical data consumers to access and retrieve data stored in databases (in the form of tables and columns for example), using abstract concepts that represent the real world (known as semantics in knowledge representation), such as “customer”, “product”, “employee”, “asset”, etc. This need arises from the fact that databases do not provide a means to use such concepts to give uniform meaning to data, because real world concepts such as “customer”, “product”, etc. are usually contained in several tables and columns or even multiple databases which are inaccessible to non-technical data consumers.
Timbr fully complies with OWL DL (the computable closed world version of OWL). Timbr’s SQL re-write engine is an inference engine that automatically generates queries based on inference rules, including inheritance, transitivity clause and others. Defining inference in Timbr can be done through Timbr’s visual interface or via SQL statements. In addition, Timbr adds capabilities that can’t be found in OWL only in extensions such as SWRL or in Spin-Rules. In Timbr users simply add business logic using SQL. Timbr can also express aggregations as ontology concepts, which cannot be done in OWL.
Timbr semantic graph relationships enable users to define inheritance in SQL to simplify data consumption. An inheritance is a relationship between two or more hierarchies of concepts in which the attributes and relationships of the parent concepts are inherited to the lower hierarchy. This is very similar to inheritance in OODBs and PLs such as C++.
Example of inheritance relationship:
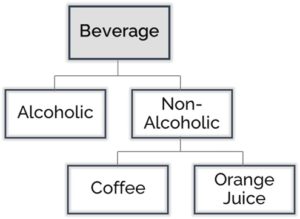
Alcoholic and Non-Alcoholic Drinks inherit from Beverage, since (necessarily) anything that is a member of the Drinks class is a member of the Beverage class. The inheritance relationship is used to create a hierarchy of classes, typically with a maximally general class named thing at the top, and very specific classes like Orange Juice at the bottom. The critically important consequence of the inheritance relation is the inheritance of properties from the parent (inheriting) class to the child (inherited) class. Thus, anything that is necessarily true of a parent class such as Beverage is also necessarily true of all of its inherited child classes, one of them being Orange Juice.
Timbr semantic graph relationships enable users to define transitive relationships in SQL to simplify data consumption.
A transitive relationship enables inference by chaining of properties (or definition of logic) between the model’s concepts.
Example of transitive relationship and reasoning:
![]()
We define relationships located at between: (i) tourist attractions Louvre and Eiffel Tower, and the city of Paris; (ii) between cities Marseille and Paris, and the country France, and (iii) between countries Italy and France, and the continent Europe. Transitivity of the relationship located at allows us to infer that the Eiffel Tower is located in Europe without need of explicitly express the intermediate relationships.
Relationships are the established associations between two or more tables in one or more databases. Relationships are based on common fields from more than one table, often involving primary and foreign keys. SQL JOIN statements are used in queries to combine data or rows from two or more tables based on foreign keys common between them.
Timbr relationships substitute complex JOIN statements so SQL queries become significantly shorter and easier to understand. They represent relationships between two concepts that are matched by the properties of each concept.
In Timbr you can define two types of relationships:
• One-to-Many Relationships – Represented by a relationship between two concepts when in one instance of a concept may be linked to many instances of another concept. One-to-Many relationship can also be represented this way when only one instance of a concept corresponds to only one other instance of a concept.
• Many-to-Many Relationships – Represented by a relationship between two concepts where many instances of one concept may be linked to many instances of another concept. Many-to-Many relationships is formed from a linked table with two foreign keys to two different concepts linking them together.
Both One-to-Many and Many-to-Many relationships can be defined as a Transitive Relationship.
Timbr Integrations FAQs
Timbr supports both JDBC and ODBC. We reuse the thrift-server protocol of Apache Hive and Spark. This means you can connect to Timbr semantic model using Hive/Spark JDBC/ODBC drivers (in most BI tools they already come embedded, so no installation needed). Read more
Yes, but why use GraphQL when you can use Timbr REST API with GraphQL capabilities, so that you get the best of both worlds?
To answer the question: GraphQL is supported by integrating external open source projects that support the translation of GraphQL to SQL,
Yes, this could be generated easily (creating the SQL DDL statements of Timbr directly from the XML hierarchy/relationships).
Yes, Timbr works extensively with SQLAlchemy. Another valid option for python users is DataFrames.
Yes, Timbr is compatible with OWL-DL and some OWL-2 inferences.
If there is a clear business value to add more OWL-2 inferences, we can support them as well. Timbr’s inference engine is based on query-rewriting techniques. If Timbr encounters slow queries/performance, Timbr can specifically materialize the part of knowledge that is required.
Timbr can leverage any data catalogs into a knowledge catalog of the business, automatically generating the semantic model. Timbr can also work with the data catalog’s business glossary and the data mappings.
Yes. Timbr provides a comprehensive solution to integrate multiple databases located in varied locations. In terms of deployment, Timbr is deployed in Kubernetes or Docker at the user’s choices. Timbr also supports multi-cluster deployments so users can deploy Timbr on Azure, GC or AWS. In general, Timbr recommends cloud because of the managed services, though Timbr can also run-on premise. The user can decide whether to run the queries locally on-premise or on the cloud to benefit from Timbr’s multi-cluster deployment.
Timbr connects to all popular data lakes, databases, BI tools, data science tools and notebooks, as well as various applications (APIs).
Once connected, the data can be queried in SQL, Python/R, dataframes, and natively in Apache Spark (SQL, Python, R, Java, Scala). GraphQL can be supported by integrating external open source projects that support the translation of GraphQL to SQL.
Yes, any tool that can create an ERD from a JDBC connection can also create an ERD from a Timbr ontology.
Timbr Use Cases FAQs
A semantic data catalog is an intelligent catalog/inventory of data assets that automatizes sharing common meanings of data across data silos and provides a means to define hierarchies and relationships featuring semantic reasoning. It serves as a queryable, AI-enabled knowledge encyclopedia of the organization. Timbr enables the fastest and most convenient implementation of semantic data catalogs connected to your databases and business intelligence tools, and can leverage existing data catalog solutions such as Collibra or Informatica. Contact us to schedule a demo.
The semantic data fabric is a flexible, reusable layer and set of data services used as the single source providing universal meaning and context to data for the entire organization. The data fabric integrates on-premise and cloud data sources in use by the organization, handing them semantic capabilities to provide answers to complex queries and to facilitate understanding and use of data. It provides consistent capabilities across on-premises and multiple cloud environments to accelerate digital transformation. Timbr enables the fastest and most convenient implementation of semantic data fabric connected to your cloud and on-premise databases and business intelligence tools. Learn more about the data fabric use case.
A digital twin refers to a digital replica of potential and actual physical assets, processes, people, places, systems and devices that can be used for various purposes. The digital representation provides both the elements and the dynamics of how an Internet of things (IoT) device operates and lives throughout its life cycle.
Digital twins have two important characteristics.
1. each definition emphasizes the connection between the physical model and the corresponding virtual model or virtual counterpart.
2. this connection is established by generating real-time data using sensors.
Timbr helps enterprises create digital twins by enabling the definition of the virtual model using SQL ontologies and by connecting the virtual model to data lakes that contain the sensor’s data. Contact us to schedule a demo to see why Timbr facilitates the fastest and most convenient implementation of digital twins.
Learn about the Timbr data fabric use case.
Gartner describes the data fabric architecture as the means of supporting “frictionless access and sharing of data in a distributed network environment.” To make this architecture work, it is necessary to implement a means to understand and assembly heterogeneous data by providing it with business meaning and flexibly integrating sources of any structural type. This is challenging due to several reasons, starting from the constraints of the architectural alternatives, and ending with the complexity to understand and query the aggregated sources.
The available options haven’t changed much in the last decade: Consolidating data into a data warehouse or graph-structured database, federating reporting, and data federation. Each alternative introduces implementation and operational constraints that involve investments in infrastructure and maintenance and varied skill sets. Moreover, till now there hasn’t been an integrative solution that resolves both the architectural and the “last mile” usability challenges, that is, encapsulating the complexity of the solution so data consumers across the enterprise conveniently gain a 360° view of data and easily generate complex queries to deliver advanced analytics and reporting conveniently and fast.
Data virtualization solutions are a viable solution to this challenge but their use is costly because of the continuous maintenance required to maintain indexes and because of the lack of relationship-rich semantic capabilities which are key to reduce complexity for end users and speed up analytics that make use of dynamic data sources.
The semantic data fabric is a flexible, reusable layer and set of data services used as the single source providing universal meaning and context to data for the entire organization. The data fabric integrates on-premise and cloud data sources in use by the organization, handing them semantic capabilities to provide answers to complex queries and to facilitate understanding and use of data. It provides consistent capabilities across on-premises and multiple cloud environments to accelerate digital transformation. Timbr enables the fastest and most convenient implementation of semantic data fabric connected to your cloud and on-premise databases and business intelligence tools. Contact us to schedule a demo.
A knowledge graph is a knowledge base that uses a graph-structured data model or topology to integrate data. Knowledge graphs are often used to store interlinked descriptions of objects, events or concepts with free-form semantics. Knowledge graphs use ontologies to put data in context via linking and semantic metadata providing a framework for data integration, unification, analytics and sharing.
They are also prominently associated with and used by Google, Bing, and Yahoo, and with question-answering services such as Google Assistant, Siri and Alexa. All these examples were developed with proprietary tools.
For organizations that look to benefit from knowledge graphs, the available solutions in the market require significant changes in their IT departments. This is due to the fact that most of the data in the world is stored in formats that are not compatible with the format in which data is stored in knowledge graphs, so data needs to be extracted from its current DBMS, transformed to a new format and loaded into a separate, suitable DBMS. Another reason being is that to use knowledge graphs, data engineers and consumers need to acquire news skills to model in OWL and query in SPARQL.
Different from most other solutions, the Timbr SQL Knowledge Graph platform creates a virtual layer that works in standard SQL to seamlessly connect to existing databases and is implemented without requiring new skills.
Contact us to learn how Timbr can help your organization join the knowledge revolution.
Timbr can leverage any data catalogs into a knowledge catalog of the business, automatically generating the semantic model. Timbr can also work with the data catalog’s business glossary and the data mappings.
No. With Timbr a user can map multiple tables from multiple data sources to the same concept. Therefore, users can leave their data wherever it is and just use Timbr’s data mapping tool to conveniently map data from the various data sources to the ontology model.
Yes. Timbr’s default implementation for graph algorithms is networkX and it happens automatically, meaning that when a user writes an SQL query Timbr automatically runs the algorithm behind the scenes. Timbr also supports Nvidia’s Cugraph (GPU) enabling graph algorithms with advanced performance.
Data mesh tries to solve three challenges with a centralized data lake/warehouse:
- Lack of ownership: who owns the data – the data source team or the infrastructure team?
- Lack of quality: the infrastructure team is responsible for quality but does not know the data well
- Organizational scaling: the central team becomes the bottleneck, such as with an enterprise data lake/warehouse
While a data mesh aims to solve many of the same problems as a data fabric–namely, the difficulty of managing data in a heterogeneous data environment–it tackles the problem in a fundamentally different manner. In short, while the data fabric seeks to build a single, virtual management layer atop distributed data, the data mesh encourages distributed groups of teams to manage data as they see fit, albeit with some common governance provisions.
Its goal is to treat data as a product, with each source having its own data product manager/owner (who are part of a cross-functional team of data engineers) and being its own clearly-focused domain that has an autonomous offering, becoming the fundamental building blocks of a mesh, leading to a domain-driven distributed architecture.
Another component in a data mesh is data infrastructure as a platform, which provides storage, pipeline, data catalog, and access control to the domains. The main idea is to avoid duplicating effort. This will allow each data product team to build its data products quickly. Note this data infrastructure platform should not become a data platform (it stays domain agnostic).
Timbr provides all the features required to successfully implement the enterprise data mesh. Contact us to learn more.
Timbr Performance FAQs
By querying the ontology using explicit relationships or Timbr generated views instead of the data itself, SQL queries are reduced in length and complexity. Learn more.
In Timbr there is no need to write JOINs as Timbr enables modeling of explicit relationships exposed in the ontology in a denormalized virtual schema. In the denormalized schema, Timbr enables graph traversals leveraging virtual columns that eliminate the need for writing JOINs.
