

Business users ask questions in business terms. Formulating the SQL queries that answer these questions require discovery and understanding of the data stored in the physical model. This is a painstaking process when data is stored in multiple tables and or databases. Semantic SQL is SQL used for querying SQL Ontologies that represent the business model and encapsulate the complexity of relationships and hierarchies, so queries become much simpler and shorter.
Advanced, and even everyday analytics require coding of complex SQL queries that are difficult to create, understand, maintain and re-use. This is a result of the physical model implemented in the database that is greatly removed from the business model it is supposed to represent. Semantic SQL is SQL used for querying SQL Ontologies that represent the business model and encapsulate the complexity of relationships and hierarchies, so queries become much simpler and shorter.
Introduction
Anyone who has worked with SQL and relational databases is aware of the complexity of expressing business questions to deliver insights.
Datalakes, data warehouses, data bases, MPP engines and streaming engines, all default back to SQL as the way to enable users to express their query needs.
SQL is great, everybody knows it, it is based on SET operations and has been extended with analytical capabilities such as window functions, complex aggregation functions and other literals.
One thing that is painfully missing is the mapping of the physical data model to the business model. To re-create this mapping in the relational model, we specify logic, join tables and filter them to refer to business objects.
Re-creating the Business Model
There are several ways used to somewhat express the business model from the physical data model:
- Referential integrity used in databases (excepting data lakes, which make the problem more severe), in the form of primary and foreign keys, etc.
- Views that persist the data model representing it in a way that is closer to the user question. Views are created for two main purposes:
- Create a business-friendly name for columns.
- Represent combined and aggregated data objects in a way closer to the business.
- Layered reporting architecture used in reporting tools to create user-friendly names and models that are easier to understand.
The problem with using any of the above options to express the business model is that, at the end, we still need to create highly technical queries in relational SQL which is closely coupled to the way that data is laid out.
Some key features missing from the relational model that would enable it to express the business model more effortlessly include:
- Hierarchies
- Classification
- Inheritance
- Relationships
- Transitive Relationships
Graph databases and semantic knowledge graphs provide some or all of the above features, but to benefit from them, data needs to be moved and transformed into new database structures and the implementation requires learning new skills and programming languages.
There’s one alternative that provides all the above features without need to invest in new infrastructures and skills: Semantic SQL enabled by SQL ontologies created and mapped to the data with the timbr SQL Knowledge Graph Platform.
Semantic SQL
Semantic SQL is standard SQL used for querying SQL ontologies mapped to the data instead of directly querying the database. By querying the ontology’s concepts, users benefit from semantic graph and reasoning features: hierarchies, classification, inheritance, relationships and transitivity. Semantic SQL queries are considerably less complex and query size is reduced significantly.
The beauty of Semantic SQL is that the coder of a query still uses SQL capabilities to express the business questions from the analytical point of view, so coders can join elements and perform calculations, but they don’t need to write and debug the part of the query that is handling connections and expression of relations between the tables.
Semantic SQL enables users to express more with fewer logic, because the logic is implicit in the semantic model. For coders and tools that write/generate queries there is no major change, it is just easier and more intuitive.
Expressing and Querying a Sample Business Model using Semantic SQL
Let’s show how Semantic SQL enables acceleration of analytical workflows and time to value. For our example we use the Crunchbase open dataset. Crunchbase is a platform for finding information about private and public companies. Crunchbase information includes investments, mergers, acquisitions and funding information, founding members and individuals in leadership positions. We downloaded a 2013 dump composed of 11 tables and stored it in MySQL.
The Crunchbase ontology was modeled and mapped to the 11 tables following a simple process that can be done visually. The resulting highest hierarchy of concepts that represent the data in business terms is shown below.
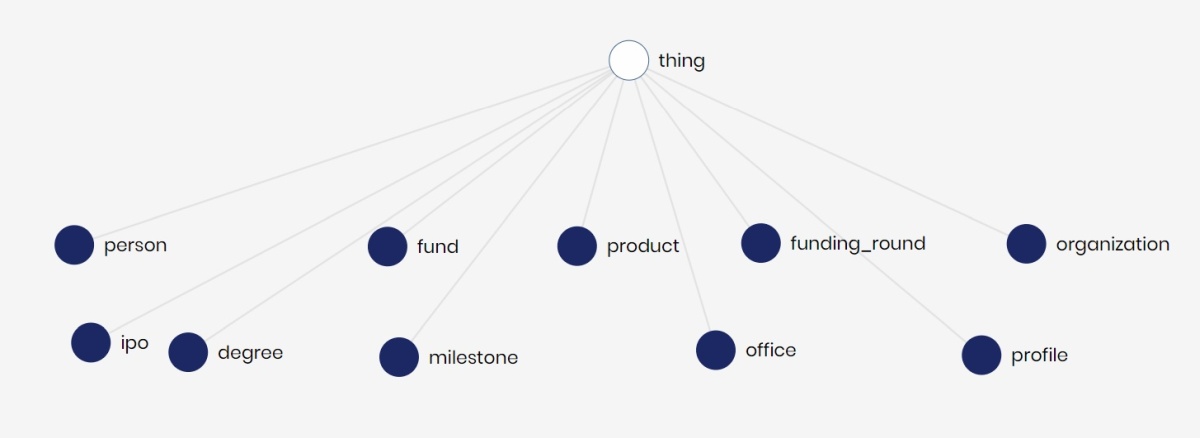

Inheritance
To explain the benefit of using “inheritance” and how it works we need some explanation of the underlying model logic.
Our business model or ontology uses abstract concepts (things) to represent the mapped data (the “real world”). An inheritance is a relationship between two or more hierarchies of concepts in which the attributes and relationships of the parent concepts are inherited to the lower hierarchy. This is very similar to inheritance in OODBs and PLs such as C++.
Example of inheritance relationship
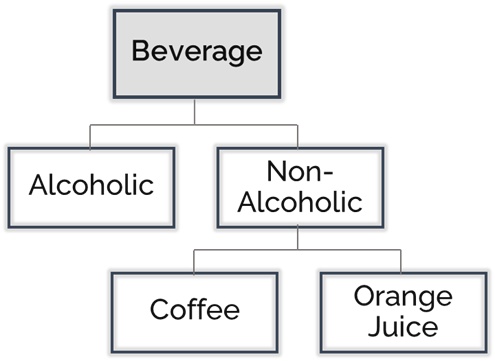
Alcoholic and Non-Alcoholic Drinks inherit from Beverage, since (necessarily) anything that is a member of the Drinks class is a member of the Beverage class. The inheritance relationship is used to create a hierarchy of classes, typically with a maximally general class named thing at the top, and very specific classes like Orange Juice at the bottom. The critically important consequence of the inheritance relation is the inheritance of properties from the parent (inheriting) class to the child (inherited) class. Thus, anything that is necessarily true of a parent class such as Beverage is also necessarily true of all of its inherited child classes, one of them being Orange Juice.
In our model, the ontology hierarchy starts with concept thing. Continuing the hierarchy tree, we have organizations that can be companies (investee companies such as startups) or financial organizations (investors such as VCs funds).
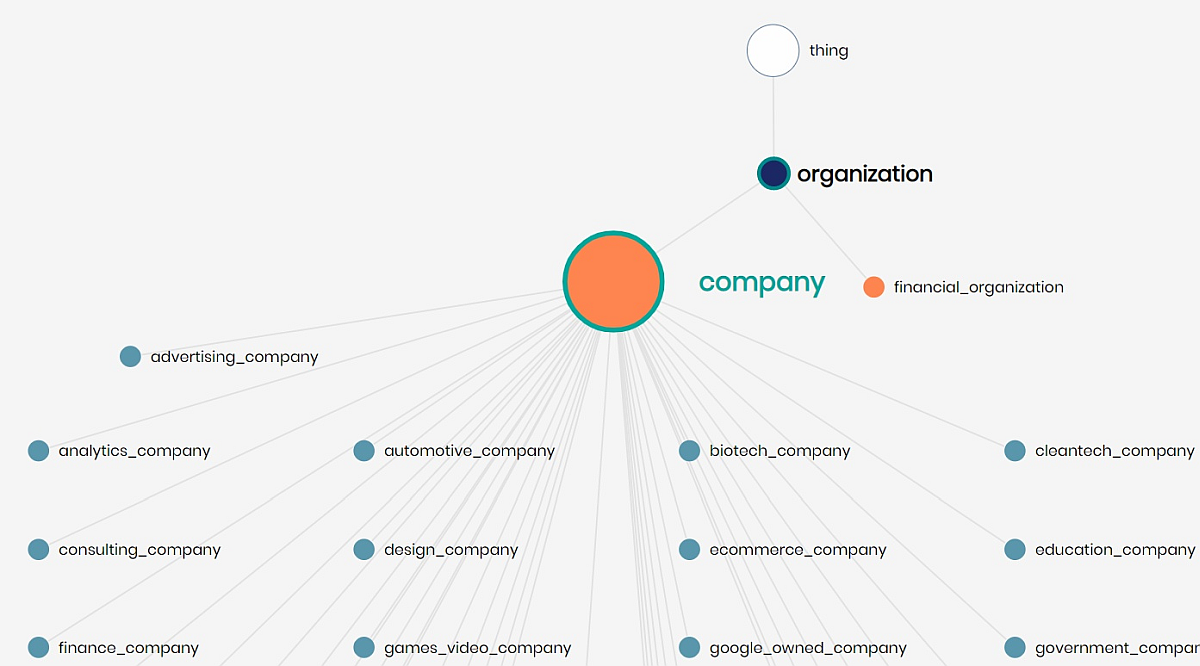
Let’s define an inheritance relationship in our model:
Using our ontology modeler, we use a SQL CREATE command to define an inheritance relationship (using the semantic SQL INHERITS command) such that: advertising company: thing -> organization -> company -> advertising_company (the blue labeled inheritance relationships were already in our model)
CREATE OR REPLACE CONCEPT `advertising_company`
INHERITS (`company`) FROM `timbr`.`company` WHERE `category_code` = 'advertising';
By defining this inheritance, we no longer need to specify characteristics of advertising_company besides a new category code: advertising. The rest of the characteristics are already implicit because of the previously defined relationships (organization->company). There can be numerous levels of hierarchy, and the inheritance of characteristics is implicit in the hierarchy.
Now, let’s see the benefits of inheritance when we create a query.
Query Example:
Our model includes the relationship between concept person and concept organization (has employee / works at). Since company inherits the characteristics of organization, it also inherits the relationships of organization with concept person.
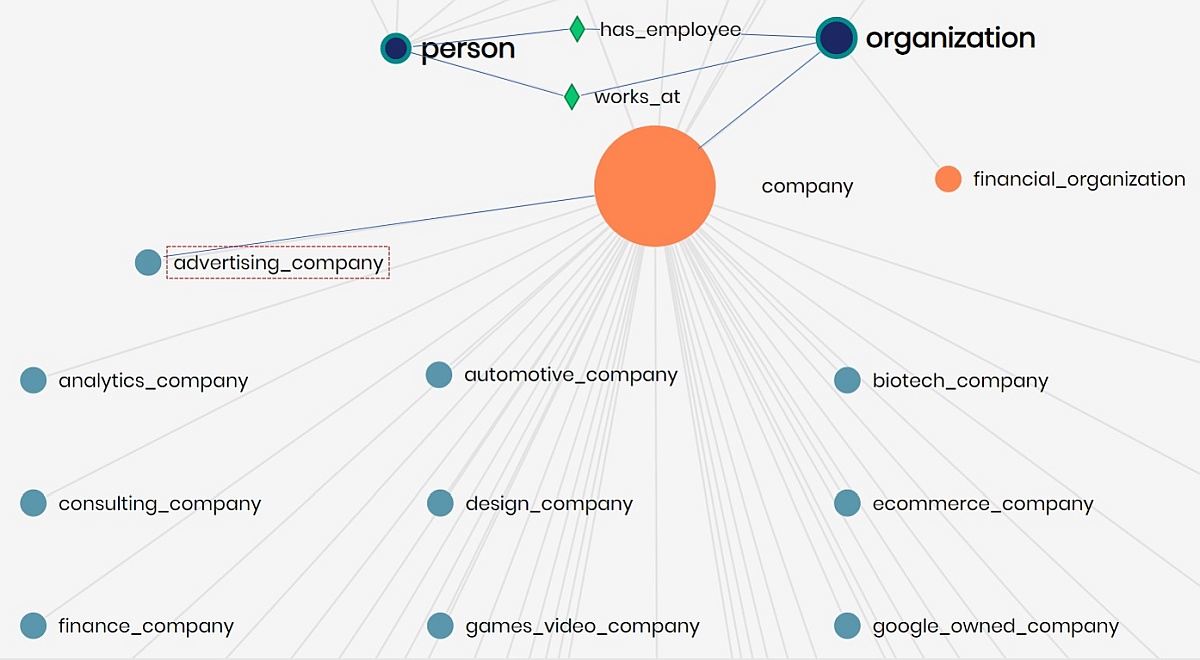
Our query: we want to find all the persons that work in advertising companies.
We make use of the implicit hierarchy to query the advertising_company concept directly, and use the relationship has_employee to find the company’s employees:
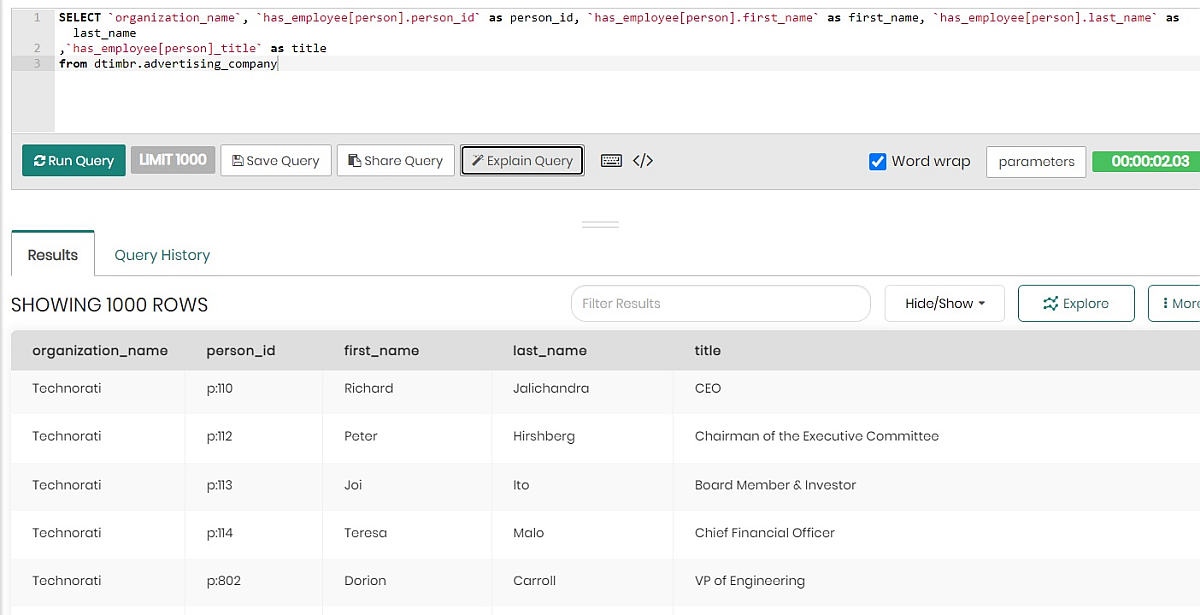
SELECT `organization_name`,
`has_employee[person].person_id` AS person_id,
`has_employee[person].first_name` AS first_name,
`has_employee[person].last_name` AS last_name,
`has_employee[person]_title` AS title
FROM dtimbr.advertising_company
The (partially displayed) results:
If we would query using relational SQL (query of the database), we can see the complexity of the inheritance that we would need to express:
SELECT `organization_name`, `has_employee[person].person_id` AS `person_id`, `has_employee[person].first_name` AS `first_name`, `has_employee[person].last_name` AS `last_name`, `has_employee[person]_title` AS `title`
FROM (SELECT `advertising_company`.`entity_id`, `advertising_company`.`entity_type`, `advertising_company`.`organization_name`, `advertising_company`.`organization_id`, `has_employee[person]`.`first_name` AS `has_employee[person].first_name`, `has_employee[person]`.`last_name` AS `has_employee[person].last_name`, `has_employee[person]`.`person_id` AS `has_employee[person].person_id`, `works_at_1`.`title` AS `has_employee[person]_title`
FROM (SELECT CAST(`organization_id` AS CHAR) AS `entity_id`, 'company' AS `entity_type`, `organization_name`, `organization_id`
FROM (SELECT `last_milestone_at`, `short_description`, `city`, `logo_url`, `last_funding_at`, `homepage_url`, `twitter_username`, `description`, `normalized_name`, `first_investment_at`, CAST(NULL AS SIGNED) AS `relationships`, `tag_list`, `first_funding_at`, `logo_height`, `logo_width`, `overview`, `closed_at`, `category_code`, `invested_companies`, `organization_name`, `created_by`, `first_milestone_at`, `country_code`, `funding_rounds`, `domain`, `organization_id`, `founded_at`, `organization_type`, `investment_rounds`, `milestones`, `permalink`, `region`, `state_code`, `last_investment_at`, `funding_total_usd`, `status`
FROM (SELECT `category_code` AS `category_code`, `closed_at` AS `closed_at`, `first_funding_at` AS `first_funding_at`, `funding_rounds` AS `funding_rounds`, `funding_total_usd` AS `funding_total_usd`, `last_funding_at` AS `last_funding_at`, `city` AS `city`, `country_code` AS `country_code`, `created_by` AS `created_by`, `description` AS `description`, `domain` AS `domain`, `first_investment_at` AS `first_investment_at`, `first_milestone_at` AS `first_milestone_at`, `founded_at` AS `founded_at`, `homepage_url` AS `homepage_url`, `invested_companies` AS `invested_companies`, `investment_rounds` AS `investment_rounds`, `last_investment_at` AS `last_investment_at`, `last_milestone_at` AS `last_milestone_at`, `logo_height` AS `logo_height`, `logo_url` AS `logo_url`, `logo_width` AS `logo_width`, `milestones` AS `milestones`, `normalized_name` AS `normalized_name`, `id` AS `organization_id`, `name` AS `organization_name`, `entity_type` AS `organization_type`, `overview` AS `overview`, `permalink` AS `permalink`, `region` AS `region`, `relationships` AS `relationships`, `short_description` AS `short_description`, `state_code` AS `state_code`, `status` AS `status`, `tag_list` AS `tag_list`, `twitter_username` AS `twitter_username`
FROM `crunchbase`.`cb_objects`
WHERE `entity_type` = 'Company') AS `map_logic_map_company_1_77`) AS `map_logic_concept_map_company_1_78`
WHERE `category_code` = 'advertising') AS `advertising_company`
LEFT JOIN (SELECT `person_object_id`, `relationship_object_id`, `start_at`, `end_at`, `is_past`, `sequence`, `title`
FROM `crunchbase`.`cb_relationships`) AS `works_at_1` ON `advertising_company`.`organization_id` = `works_at_1`.`relationship_object_id`
LEFT JOIN (SELECT CAST(`person_id` AS CHAR) AS `entity_id`, 'person' AS `entity_type`, `last_name`, `first_name`, `person_id`
FROM (SELECT `affiliation_name` AS `affiliation_name`, `birthplace` AS `birthplace`, `first_name` AS `first_name`, `last_name` AS `last_name`, `object_id` AS `person_id`
FROM `crunchbase`.`cb_people`) AS `map_map_person_1_46`) AS `has_employee[person]` ON `works_at_1`.`person_object_id` = `has_employee[person]`.`person_id`) AS `dtimbr_advertising_company_1`
So, we can clearly see that by querying the business model we reduce the complexity of the query and more importantly: this complexity is saved not only from the person doing this query but from all other persons that require to do queries that express the inheritance.
Transitive Relationship
Transitivity reasoning corresponds to relationships chained by a property.
Example of transitive relationship
We define relationships located at between: (i) tourist attractions Louvre and Eiffel Tower, and the city of Paris; (ii) between cities Marseille and Paris, and the country France, and (iii) between countries Italy and France, and the continent Europe. Transitivity of the relationship located at allows us to infer that the Eiffel Tower is located in Europe without need of explicitly express the intermediate relationships.
In our model we created transitive relationships that enable simplification of ownership detection.
Query example:
We want to find all the companies (direct or not) that were acquired by Microsoft up to a 3 level (a company purchased by a company purchased by Microsoft).
Since a company can be acquired and/or purchased, we use it in a transitive way. We can traverse the tree in levels using the * sign, and then the number of levels we want to search in the hierarchy.
SELECT `organization_name`,
`has_acquired[company*3].organization_name`,
`has_acquired[company*3]_transitivity_level`,
`has_acquired[company*3].has_product[product].entity_label` AS product
FROM dtimbr.company
WHERE `organization_name` = 'Microsoft' AND `has_acquired[company*3].organization_name` IS NOT NULL
ORDER BY `has_acquired[company*3]_transitivity_level` ASC
LIMIT 1000
The (partially displayed) results:
If we would query using relational SQL (query of the database), we can see the complexity of the transitivity that we would need to express:
SELECT `organization_name`, `has_acquired[company*3].organization_name`, `has_acquired[company*3]_transitivity_level`, `has_acquired[company*3].has_product[product].entity_label` AS `product`
FROM (SELECT `company`.`entity_id`, `company`.`entity_type`, `company`.`entity_label`, `company`.`organization_name`, `company`.`organization_id`, `has_acquired[company*3].has_product[product]`.`entity_label` AS `has_acquired[company*3].has_product[product].entity_label`, `has_acquired[company*3]`.`_transitivity_level` AS `has_acquired[company*3]_transitivity_level`, `has_acquired[company*3]`.`organization_name` AS `has_acquired[company*3].organization_name`
FROM (SELECT CAST(`organization_id` AS CHAR) AS `entity_id`, 'company' AS `entity_type`, CAST(`organization_name` AS CHAR) AS `entity_label`, `organization_name`, `organization_id`
FROM (SELECT `category_code` AS `category_code`, `closed_at` AS `closed_at`, `first_funding_at` AS `first_funding_at`, `funding_rounds` AS `funding_rounds`, `funding_total_usd` AS `funding_total_usd`, `last_funding_at` AS `last_funding_at`, `city` AS `city`, `country_code` AS `country_code`, `created_by` AS `created_by`, `description` AS `description`, `domain` AS `domain`, `first_investment_at` AS `first_investment_at`, `first_milestone_at` AS `first_milestone_at`, `founded_at` AS `founded_at`, `homepage_url` AS `homepage_url`, `invested_companies` AS `invested_companies`, `investment_rounds` AS `investment_rounds`, `last_investment_at` AS `last_investment_at`, `last_milestone_at` AS `last_milestone_at`, `logo_height` AS `logo_height`, `logo_url` AS `logo_url`, `logo_width` AS `logo_width`, `milestones` AS `milestones`, `normalized_name` AS `normalized_name`, `id` AS `organization_id`, `name` AS `organization_name`, `entity_type` AS `organization_type`, `overview` AS `overview`, `permalink` AS `permalink`, `region` AS `region`, `relationships` AS `relationships`, `short_description` AS `short_description`, `state_code` AS `state_code`, `status` AS `status`, `tag_list` AS `tag_list`, `twitter_username` AS `twitter_username`
FROM `crunchbase`.`cb_objects`
WHERE `entity_type` = 'Company') AS `map_map_company_1_74`) AS `company`
LEFT JOIN (SELECT `acquiring_object_id` AS `acquiring_object_id`, `acquired_object_id` AS `acquired_object_id`, `price_amount` AS `price_amount`, `term_code` AS `term_code`, `acquired_at` AS `acquired_at`, `price_currency_code` AS `price_currency_code`
FROM `crunchbase`.`cb_acquisitions`) AS `map_company_has_acquired_1` ON `company`.`organization_id` = `map_company_has_acquired_1`.`acquiring_object_id`
LEFT JOIN (SELECT 1 AS `_transitivity_level`, `has_acquired[company*3]_0_2`.`organization_id` AS `organization_id_tmp_1st`, `has_acquired[company*3]_0_2`.*
FROM (SELECT CAST(`organization_id` AS CHAR) AS `entity_id`, 'company' AS `entity_type`, CAST(`organization_name` AS CHAR) AS `entity_label`, `organization_name`, `organization_id`
FROM (SELECT `category_code` AS `category_code`, `closed_at` AS `closed_at`, `first_funding_at` AS `first_funding_at`, `funding_rounds` AS `funding_rounds`, `funding_total_usd` AS `funding_total_usd`, `last_funding_at` AS `last_funding_at`, `city` AS `city`, `country_code` AS `country_code`, `created_by` AS `created_by`, `description` AS `description`, `domain` AS `domain`, `first_investment_at` AS `first_investment_at`, `first_milestone_at` AS `first_milestone_at`, `founded_at` AS `founded_at`, `homepage_url` AS `homepage_url`, `invested_companies` AS `invested_companies`, `investment_rounds` AS `investment_rounds`, `last_investment_at` AS `last_investment_at`, `last_milestone_at` AS `last_milestone_at`, `logo_height` AS `logo_height`, `logo_url` AS `logo_url`, `logo_width` AS `logo_width`, `milestones` AS `milestones`, `normalized_name` AS `normalized_name`, `id` AS `organization_id`, `name` AS `organization_name`, `entity_type` AS `organization_type`, `overview` AS `overview`, `permalink` AS `permalink`, `region` AS `region`, `relationships` AS `relationships`, `short_description` AS `short_description`, `state_code` AS `state_code`, `status` AS `status`, `tag_list` AS `tag_list`, `twitter_username` AS `twitter_username`
FROM `crunchbase`.`cb_objects`
WHERE `entity_type` = 'Company') AS `map_map_company_1_74`) AS `has_acquired[company*3]_0_2`
UNION ALL
SELECT 2 AS `_transitivity_level`, `has_acquired[company*3]_1_3`.`organization_id` AS `organization_id_tmp_1st`, `has_acquired[company*3]_0_2`.*
FROM (SELECT CAST(`organization_id` AS CHAR) AS `entity_id`, 'company' AS `entity_type`, CAST(`organization_name` AS CHAR) AS `entity_label`, `organization_name`, `organization_id`
FROM (SELECT `category_code` AS `category_code`, `closed_at` AS `closed_at`, `first_funding_at` AS `first_funding_at`, `funding_rounds` AS `funding_rounds`, `funding_total_usd` AS `funding_total_usd`, `last_funding_at` AS `last_funding_at`, `city` AS `city`, `country_code` AS `country_code`, `created_by` AS `created_by`, `description` AS `description`, `domain` AS `domain`, `first_investment_at` AS `first_investment_at`, `first_milestone_at` AS `first_milestone_at`, `founded_at` AS `founded_at`, `homepage_url` AS `homepage_url`, `invested_companies` AS `invested_companies`, `investment_rounds` AS `investment_rounds`, `last_investment_at` AS `last_investment_at`, `last_milestone_at` AS `last_milestone_at`, `logo_height` AS `logo_height`, `logo_url` AS `logo_url`, `logo_width` AS `logo_width`, `milestones` AS `milestones`, `normalized_name` AS `normalized_name`, `id` AS `organization_id`, `name` AS `organization_name`, `entity_type` AS `organization_type`, `overview` AS `overview`, `permalink` AS `permalink`, `region` AS `region`, `relationships` AS `relationships`, `short_description` AS `short_description`, `state_code` AS `state_code`, `status` AS `status`, `tag_list` AS `tag_list`, `twitter_username` AS `twitter_username`
FROM `crunchbase`.`cb_objects`
WHERE `entity_type` = 'Company') AS `map_map_company_1_74`) AS `has_acquired[company*3]_1_3`
INNER JOIN (SELECT `acquiring_object_id` AS `acquiring_object_id`, `acquired_object_id` AS `acquired_object_id`, `price_amount` AS `price_amount`, `term_code` AS `term_code`, `acquired_at` AS `acquired_at`, `price_currency_code` AS `price_currency_code`
FROM `crunchbase`.`cb_acquisitions`) AS `has_acquired[company*3]_0_2_mapping` ON `has_acquired[company*3]_1_3`.`organization_id` = `has_acquired[company*3]_0_2_mapping`.`acquiring_object_id`
INNER JOIN (SELECT CAST(`organization_id` AS CHAR) AS `entity_id`, 'company' AS `entity_type`, CAST(`organization_name` AS CHAR) AS `entity_label`, `organization_name`, `organization_id`
FROM (SELECT `category_code` AS `category_code`, `closed_at` AS `closed_at`, `first_funding_at` AS `first_funding_at`, `funding_rounds` AS `funding_rounds`, `funding_total_usd` AS `funding_total_usd`, `last_funding_at` AS `last_funding_at`, `city` AS `city`, `country_code` AS `country_code`, `created_by` AS `created_by`, `description` AS `description`, `domain` AS `domain`, `first_investment_at` AS `first_investment_at`, `first_milestone_at` AS `first_milestone_at`, `founded_at` AS `founded_at`, `homepage_url` AS `homepage_url`, `invested_companies` AS `invested_companies`, `investment_rounds` AS `investment_rounds`, `last_investment_at` AS `last_investment_at`, `last_milestone_at` AS `last_milestone_at`, `logo_height` AS `logo_height`, `logo_url` AS `logo_url`, `logo_width` AS `logo_width`, `milestones` AS `milestones`, `normalized_name` AS `normalized_name`, `id` AS `organization_id`, `name` AS `organization_name`, `entity_type` AS `organization_type`, `overview` AS `overview`, `permalink` AS `permalink`, `region` AS `region`, `relationships` AS `relationships`, `short_description` AS `short_description`, `state_code` AS `state_code`, `status` AS `status`, `tag_list` AS `tag_list`, `twitter_username` AS `twitter_username`
FROM `crunchbase`.`cb_objects`
WHERE `entity_type` = 'Company') AS `map_map_company_1_74`) AS `has_acquired[company*3]_0_2` ON `has_acquired[company*3]_0_2_mapping`.`acquired_object_id` = `has_acquired[company*3]_0_2`.`organization_id`
UNION ALL
SELECT 3 AS `_transitivity_level`, `has_acquired[company*3]_2_4`.`organization_id` AS `organization_id_tmp_1st`, `has_acquired[company*3]_1_3`.*
FROM (SELECT CAST(`organization_id` AS CHAR) AS `entity_id`, 'company' AS `entity_type`, CAST(`organization_name` AS CHAR) AS `entity_label`, `organization_name`, `organization_id`
FROM (SELECT `category_code` AS `category_code`, `closed_at` AS `closed_at`, `first_funding_at` AS `first_funding_at`, `funding_rounds` AS `funding_rounds`, `funding_total_usd` AS `funding_total_usd`, `last_funding_at` AS `last_funding_at`, `city` AS `city`, `country_code` AS `country_code`, `created_by` AS `created_by`, `description` AS `description`, `domain` AS `domain`, `first_investment_at` AS `first_investment_at`, `first_milestone_at` AS `first_milestone_at`, `founded_at` AS `founded_at`, `homepage_url` AS `homepage_url`, `invested_companies` AS `invested_companies`, `investment_rounds` AS `investment_rounds`, `last_investment_at` AS `last_investment_at`, `last_milestone_at` AS `last_milestone_at`, `logo_height` AS `logo_height`, `logo_url` AS `logo_url`, `logo_width` AS `logo_width`, `milestones` AS `milestones`, `normalized_name` AS `normalized_name`, `id` AS `organization_id`, `name` AS `organization_name`, `entity_type` AS `organization_type`, `overview` AS `overview`, `permalink` AS `permalink`, `region` AS `region`, `relationships` AS `relationships`, `short_description` AS `short_description`, `state_code` AS `state_code`, `status` AS `status`, `tag_list` AS `tag_list`, `twitter_username` AS `twitter_username`
FROM `crunchbase`.`cb_objects`
WHERE `entity_type` = 'Company') AS `map_map_company_1_74`) AS `has_acquired[company*3]_2_4`
INNER JOIN (SELECT `acquiring_object_id` AS `acquiring_object_id`, `acquired_object_id` AS `acquired_object_id`, `price_amount` AS `price_amount`, `term_code` AS `term_code`, `acquired_at` AS `acquired_at`, `price_currency_code` AS `price_currency_code`
FROM `crunchbase`.`cb_acquisitions`) AS `has_acquired[company*3]_0_2_mapping` ON `has_acquired[company*3]_2_4`.`organization_id` = `has_acquired[company*3]_0_2_mapping`.`acquiring_object_id`
INNER JOIN (SELECT CAST(`organization_id` AS CHAR) AS `entity_id`, 'company' AS `entity_type`, CAST(`organization_name` AS CHAR) AS `entity_label`, `organization_name`, `organization_id`
FROM (SELECT `category_code` AS `category_code`, `closed_at` AS `closed_at`, `first_funding_at` AS `first_funding_at`, `funding_rounds` AS `funding_rounds`, `funding_total_usd` AS `funding_total_usd`, `last_funding_at` AS `last_funding_at`, `city` AS `city`, `country_code` AS `country_code`, `created_by` AS `created_by`, `description` AS `description`, `domain` AS `domain`, `first_investment_at` AS `first_investment_at`, `first_milestone_at` AS `first_milestone_at`, `founded_at` AS `founded_at`, `homepage_url` AS `homepage_url`, `invested_companies` AS `invested_companies`, `investment_rounds` AS `investment_rounds`, `last_investment_at` AS `last_investment_at`, `last_milestone_at` AS `last_milestone_at`, `logo_height` AS `logo_height`, `logo_url` AS `logo_url`, `logo_width` AS `logo_width`, `milestones` AS `milestones`, `normalized_name` AS `normalized_name`, `id` AS `organization_id`, `name` AS `organization_name`, `entity_type` AS `organization_type`, `overview` AS `overview`, `permalink` AS `permalink`, `region` AS `region`, `relationships` AS `relationships`, `short_description` AS `short_description`, `state_code` AS `state_code`, `status` AS `status`, `tag_list` AS `tag_list`, `twitter_username` AS `twitter_username`
FROM `crunchbase`.`cb_objects`
WHERE `entity_type` = 'Company') AS `map_map_company_1_74`) AS `has_acquired[company*3]_0_2` ON `has_acquired[company*3]_0_2_mapping`.`acquired_object_id` = `has_acquired[company*3]_0_2`.`organization_id`
INNER JOIN (SELECT `acquiring_object_id` AS `acquiring_object_id`, `acquired_object_id` AS `acquired_object_id`, `price_amount` AS `price_amount`, `term_code` AS `term_code`, `acquired_at` AS `acquired_at`, `price_currency_code` AS `price_currency_code`
FROM `crunchbase`.`cb_acquisitions`) AS `has_acquired[company*3]_1_3_mapping` ON `has_acquired[company*3]_0_2`.`organization_id` = `has_acquired[company*3]_1_3_mapping`.`acquiring_object_id`
INNER JOIN (SELECT CAST(`organization_id` AS CHAR) AS `entity_id`, 'company' AS `entity_type`, CAST(`organization_name` AS CHAR) AS `entity_label`, `organization_name`, `organization_id`
FROM (SELECT `category_code` AS `category_code`, `closed_at` AS `closed_at`, `first_funding_at` AS `first_funding_at`, `funding_rounds` AS `funding_rounds`, `funding_total_usd` AS `funding_total_usd`, `last_funding_at` AS `last_funding_at`, `city` AS `city`, `country_code` AS `country_code`, `created_by` AS `created_by`, `description` AS `description`, `domain` AS `domain`, `first_investment_at` AS `first_investment_at`, `first_milestone_at` AS `first_milestone_at`, `founded_at` AS `founded_at`, `homepage_url` AS `homepage_url`, `invested_companies` AS `invested_companies`, `investment_rounds` AS `investment_rounds`, `last_investment_at` AS `last_investment_at`, `last_milestone_at` AS `last_milestone_at`, `logo_height` AS `logo_height`, `logo_url` AS `logo_url`, `logo_width` AS `logo_width`, `milestones` AS `milestones`, `normalized_name` AS `normalized_name`, `id` AS `organization_id`, `name` AS `organization_name`, `entity_type` AS `organization_type`, `overview` AS `overview`, `permalink` AS `permalink`, `region` AS `region`, `relationships` AS `relationships`, `short_description` AS `short_description`, `state_code` AS `state_code`, `status` AS `status`, `tag_list` AS `tag_list`, `twitter_username` AS `twitter_username`
FROM `crunchbase`.`cb_objects`
WHERE `entity_type` = 'Company') AS `map_map_company_1_74`) AS `has_acquired[company*3]_1_3` ON `has_acquired[company*3]_1_3_mapping`.`acquired_object_id` = `has_acquired[company*3]_1_3`.`organization_id`) AS `has_acquired[company*3]` ON `map_company_has_acquired_1`.`acquired_object_id` = `has_acquired[company*3]`.`organization_id_tmp_1st`
LEFT JOIN (SELECT CAST(`product_id` AS CHAR) AS `entity_id`, 'product' AS `entity_type`, CAST(`product_name` AS CHAR) AS `entity_label`, `parent_id`
FROM (SELECT `closed_at` AS `closed_at`, `domain` AS `domain`, `first_milestone_at` AS `first_milestone_at`, `founded_at` AS `founded_at`, `homepage_url` AS `homepage_url`, `last_milestone_at` AS `last_milestone_at`, `logo_height` AS `logo_height`, `logo_url` AS `logo_url`, `logo_width` AS `logo_width`, `milestones` AS `milestones`, `normalized_name` AS `normalized_name`, `overview` AS `overview`, `parent_id` AS `parent_id`, `permalink` AS `permalink`, `id` AS `product_id`, `name` AS `product_name`, `region` AS `region`, `status` AS `status`, `tag_list` AS `tag_list`, `twitter_username` AS `twitter_username`
FROM `crunchbase`.`cb_objects`
WHERE `entity_type` = 'Product') AS `map_map_product_1_89`) AS `has_acquired[company*3].has_product[product]` ON `has_acquired[company*3]`.`organization_id` = `has_acquired[company*3].has_product[product]`.`parent_id`) AS `dtimbr_company_1`
WHERE `organization_name` = 'microsoft' AND `has_acquired[company*3].organization_name` IS NOT NULL
ORDER BY `has_acquired[company*3]_transitivity_level`
LIMIT 1000
Creating queries that require transitivity relationships is increasingly difficult as the chain of relationships is extended. The timbr platform offers the best alternative to eliminate this complexity and does so in standard SQL, without need of transforming data or acquiring new skills.
Conclusion
Semantic SQL is standard SQL used to query “semantically enhanced” datasets. Semantics encapsulates the complexity of relationships, so the user who writes the query can ask complex, deeper questions with simpler logic.
As data analytics becomes a cornerstone of any business, timbr delivers the features and tools to enable doing so with virtual semantic layers on top of existing federated data sources
How do you make your data smart?
timbr virtually transforms existing databases into semantic SQL knowledge graphs with inference and graph capabilities, so data consumers can deliver fast answers and unique insights with minimum effort.
