
Why haven’t you implemented a knowledge-graph-powered semantic layer to manage your data?
Now you have no excuses.
CIOs and CTOs are exposed to risky decisions with high impact and visibility across their companies. On one hand, their organization depends on IT to support operations, remain competitive and enable daily and strategic decision making. On the other, adopting a new technology, no matter how promising it is, usually entails significant challenges.
The gap between the “SQL world” and knowledge graphs
Implementing knowledge graphs is a tremendous challenge for any organization since most of the enterprise data is stored in Relational Databases (RDBMS) and accessible in SQL, while knowledge graphs’ data is stored according to the Semantic Web standards1 in RDF format, modeled into ontologies using RDFS/OWL and queried in SPARQL.
To create knowledge graphs that can deliver value across the organization, CIOs/CTOs are confronted with a risky decision requiring changes in database infrastructure, changes in database management, learning programming languages, training employees to query data and finding ways to connect the graph to the everyday, SQL-based tools employed by business analysts and data scientists.
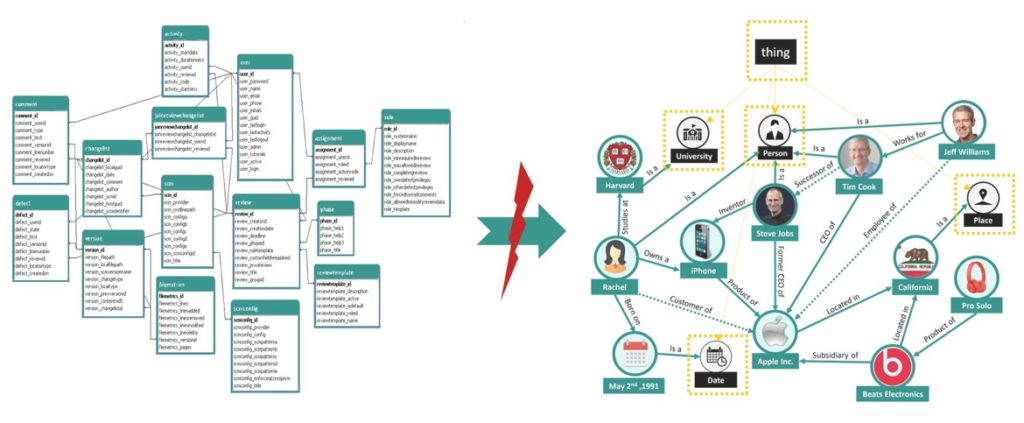
So, despite their proven value, knowledge graphs have so far remained mainly a niche for large organizations that can afford custom solutions.
The Value of Knowledge Graphs
Popularized by Google’s infobox displayed at the right side of search results, knowledge graphs are “thinking databases” that organize data to represent knowledge in a form similar to how human knowledge is organized2. They provide a universal solution for linking disassociated business content into a larger web of cohesive concepts and data values.
Companies such as Amazon, Facebook, Microsoft, Apple, JPMorgan and Bank of America have made large investments to develop their own proprietary knowledge graphs to use data strategically, gain competitive advantages, expand business boundaries and discover business opportunities hidden in the data.
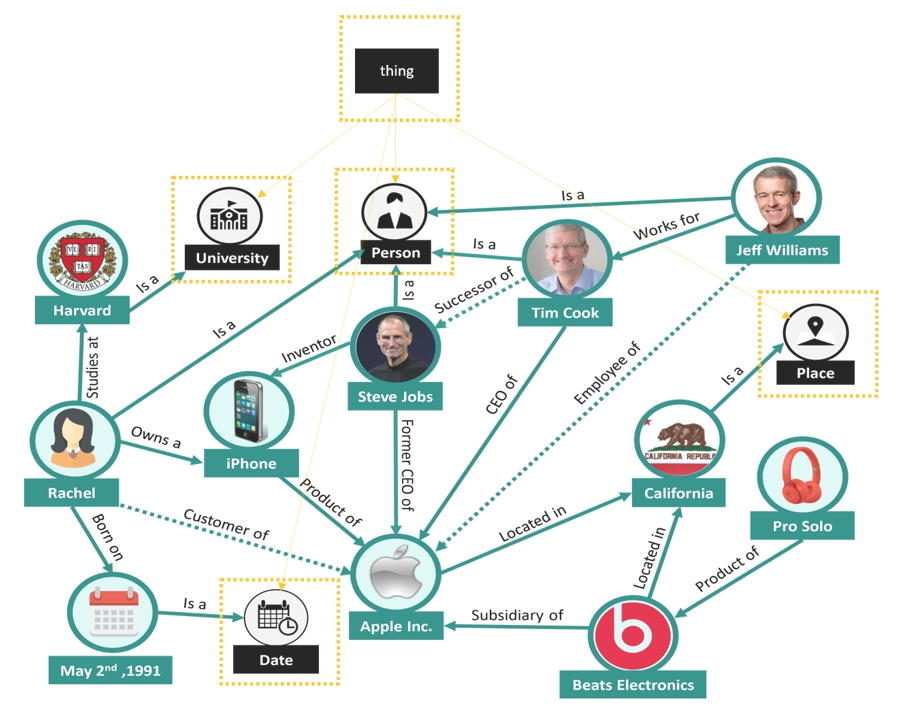
Not to be confused with the popular “property” and “labeled” graph databases used for ad-hoc representation of networked data, knowledge graphs use abstract concepts to represent data and are built upon the Semantic Web principles, a set of standards that ensure powerful capabilities such as abstractions and inference: the ability to create new information from existing information.
Bridging the gap:
timbr - the SQL Knowledge Graph™ platform
The timbr SQL Knowledge Graph platform bridges the gap between SQL-fluent databases and the modern knowledge graph ecosystem.
The platform installs on top of existing databases to enable creation of virtual knowledge graphs3 mapped to the underlying data, to deliver the powerful characteristics and benefits of knowledge graphs.
timbr eliminates the risks associated with the adoption and enterprise use of knowledge graphs: no need to add database infrastructure, no need to move data, no ETL operations4, no retraining of IT personnel, no need to learn new programming languages and no need to modify or change BI tools.
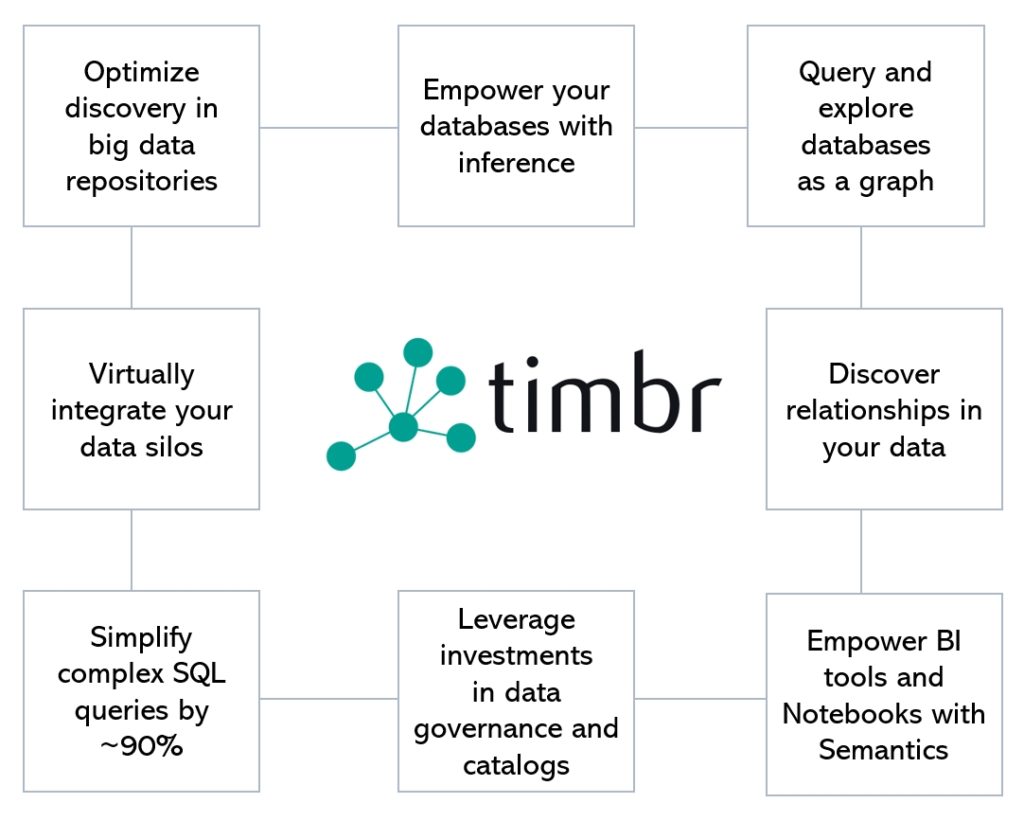
Using timbr, organizations can boost their existing IT investments by:
• Extending the relational schema and table definitions with abstractions that facilitate standardization of data meaning across the organization and make data understandable to both business users and machines.
• Representing and exploring relationships directly over RDBMS.
• Virtually integrating heterogeneous data sources.
• Having any SQL-fluent user learn to model, integrate and query the knowledge graph in a matter of days.
• Reducing SQL query complexity by up to 90%.
• Reusing, sharing and preventing loss of knowledge generated by analytical models.
• Empowering data warehouses and data lakes with inferencing capabilities that facilitate and dramatically reduce delivery time of complex analytics and ML algorithms.
Timbr's Main Capabilities
The timbr platform harnesses state of the art technologies to deliver all the tools and features to conveniently create and use knowledge graphs.
• Visual modeling of knowledge graph ontologies5 (also using extended SQL DDL statements).
• Visual mapping databases and tables to KG ontologies (also using extended SQL DDL statements).
• Reasoning capabilities using logical inferences.
• KG ontologies representation as virtual schemas accessible in standard SQL.
• Scalability to whatever the underlying database scales.
• Supporting loading of, and integrating with existing OWL ontologies.
• Graph traversals in SQL queries without the need to explicitly write joins.
• Visually exploring the data as a Graph
• Native integration with Apache Spark SQL, R, Python, Java and Scala.
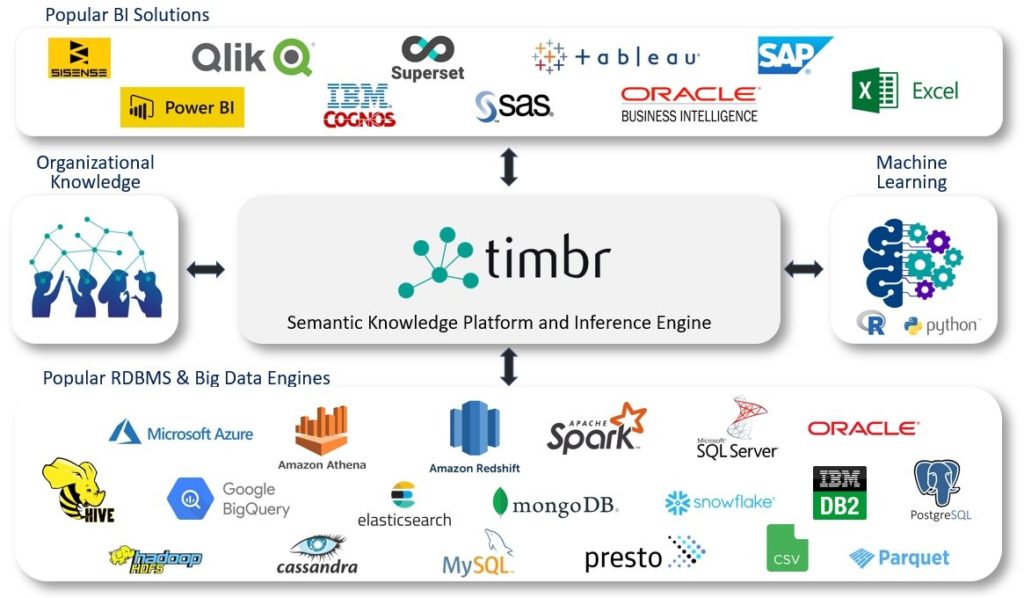
Timbr's large Ecosystem
timbr seamlessly connects to the SQL ecosystem to integrate the existing organizational knowledge repositories used in enterprise software and modern data warehouses and data lakes.
Downstream, timbr connects to all popular BI solutions using JDBC and ODBC connectors, and empowers data scientists by enabling the popular Zeppelin and Jupyter notebooks’ query of the knowledge graph in SQL, Apache Spark, Python and R.
So, what’s your excuse for not implementing the SQL knowledge graph in your organization?
With timbr, your organization can benefit for the first time from the tremendous power of knowledge graphs without incurring any risks.
Go ahead, contact us now to test-drive timbr. We will implement a POC for you, using your own data in just a matter of days.
Notes:
1. Semantic Web
2. In its most simple form, a knowledge graph acquires, organizes and integrates information into a network of concepts and applies a reasoner to derive new knowledge. See.
3. Consistent with the Semantic Web standards
4. ETL – Extract, transform and load data operations performed to transfer data from tables to RDF format
5. A knowledge graph ontology is “the schema of a knowledge graph”. This kind of ontology is a simple model of the business, using existing business concepts and a schema-like description of how they are related to each other. A concept may encapsulate an explanation of the underlying data and what it represents and is mapped to a column in a table of a database or to a series of tables, each in a separate database.
How do you make your data smart?
Timbr virtually transforms existing databases into semantic SQL knowledge graphs with inference and graph capabilities, so data consumers can deliver fast answers and unique insights with minimum effort.
