
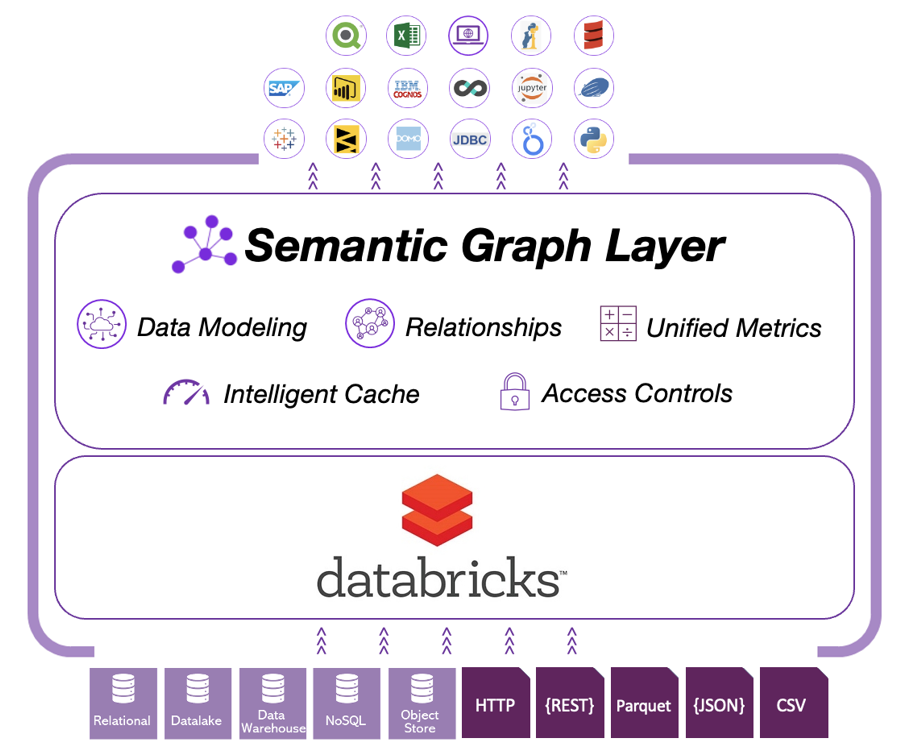
Introduction
Organizations are dealing with increasingly large and complex datasets in today’s data-driven world. The necessity to efficiently use data and drive business decisions requires tools that can handle the never-ending amounts of data while maintaining a clear structure and adaptable frameworks to support the changing business demands. The Apache Foundation has introduced Spark as a robust framework for distributed data processing and analytics, providing speed, scalability, and ease of use.
While data complexity grows, a powerful engine is not enough to manage the ocean of data organizations store. There’s a clear gap for a system to keep data in order, maintain a clear business context associated with the datasets, and simplify discovery to help engineers and analysts avoid getting lost in the big blue sea of data.
The Timbr Platform, combined with Databricks, offers a powerful solution for creating and utilizing scalable semantic graph data models in big data environments to efficiently integrate, manage, and share data across teams and business functions.
In this article, we will explore the capabilities of combining Databricks with the Timbr platform and how it revolutionizes how we work with data.
The Power of Databricks
Databricks has gained popularity due to its ability to process large-scale datasets in a distributed and fault-tolerant manner. Its in-memory computing capabilities, combined with a rich set of libraries for data manipulation, machine learning, and graph processing, make it a preferred choice for big data analytics. However, Databricks primarily operates on raw data structures, such as RDDs (Resilient Distributed Datasets) and DataFrames, which lack inherent semantic context, like other powerful engines.
Databricks users access ERD models of connected databases, such as in the PostgreSQL example below. As tables and metadata multiply, making sense of big data becomes a time-consuming and complicated task.
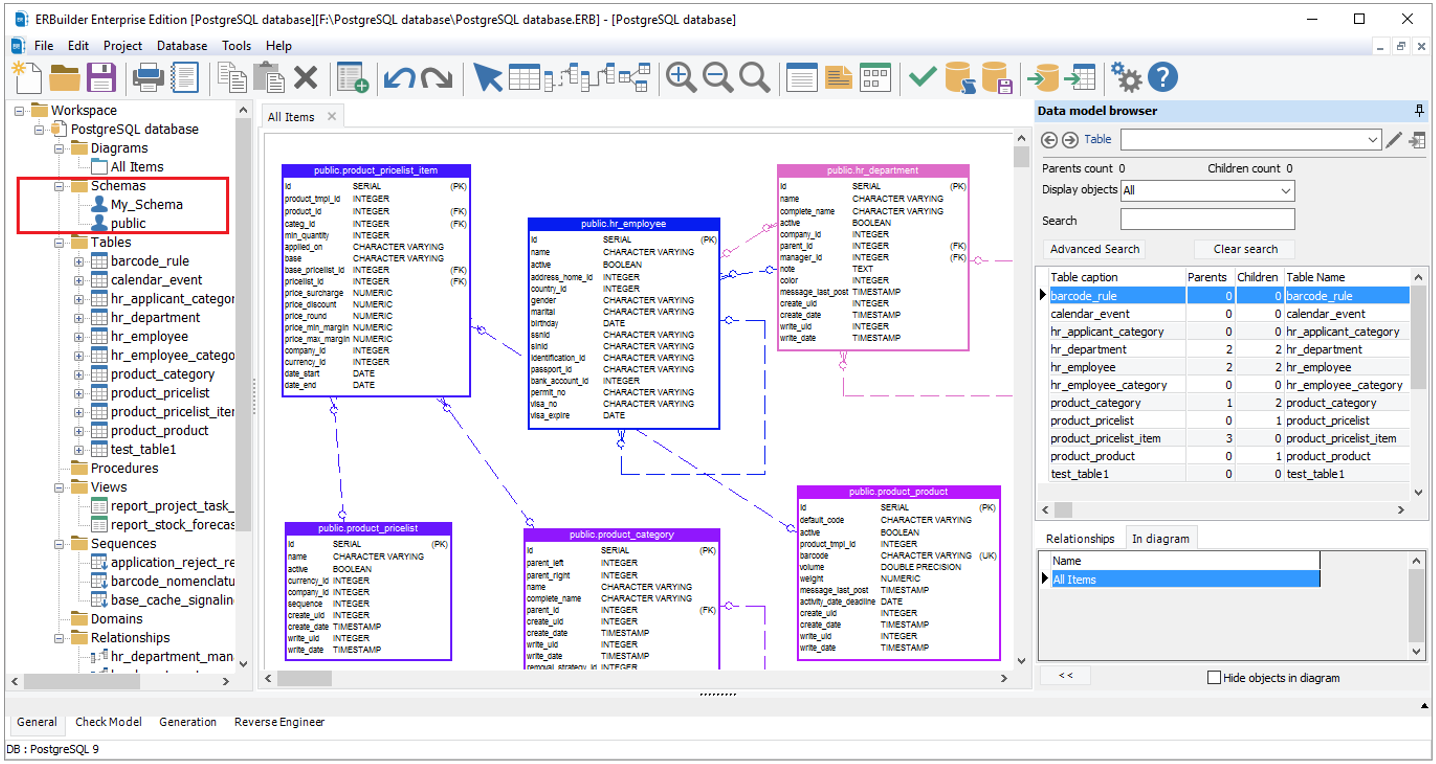
Timbr – The Intelligent Semantic Layer
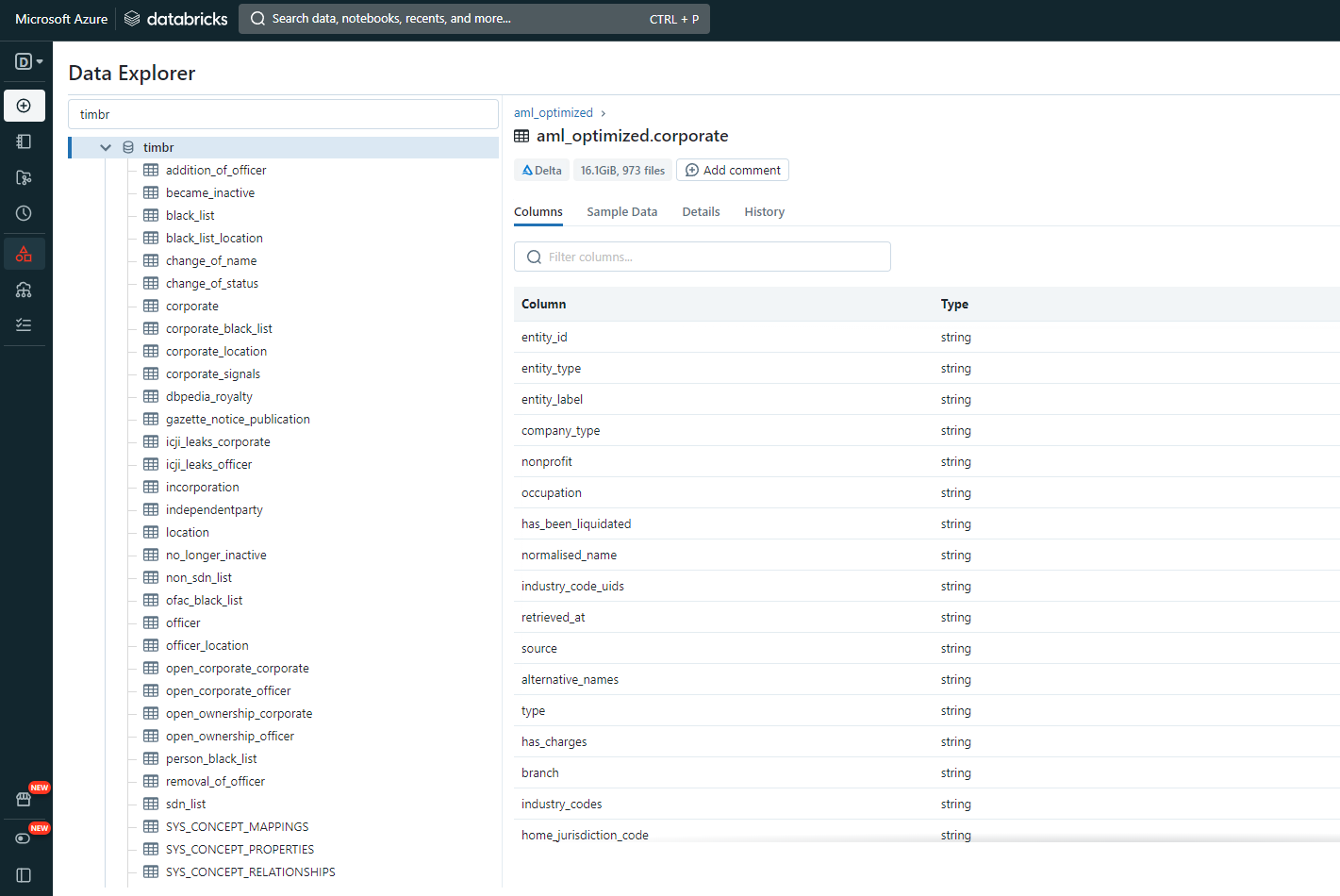
Timbr enables users to create virtual data models that present datasets as business concepts enriched with semantic relationships and explicit business context. The virtual data models are connected to the underlying databases and can connect to any tool or application the organization uses for data consumption.
A virtual data model in Timbr is presented as a hierarchy of business concepts (Ontology) which entails logical business definitions and metrics, semantic relationships that replace JOIN statements, and the ability to integrate data from multiple sources into a contextual data model that lives within the organization.
The models are versioned and controlled, fully supporting any access level to enable meta-data management and intuitive data discovery. The data models in Timbr can be directly imported from an existing data model or by using standard SQL create statements. When mapping data to the model, users can apply any transformation or function that the connected database supports to continue and support the exact requirements.
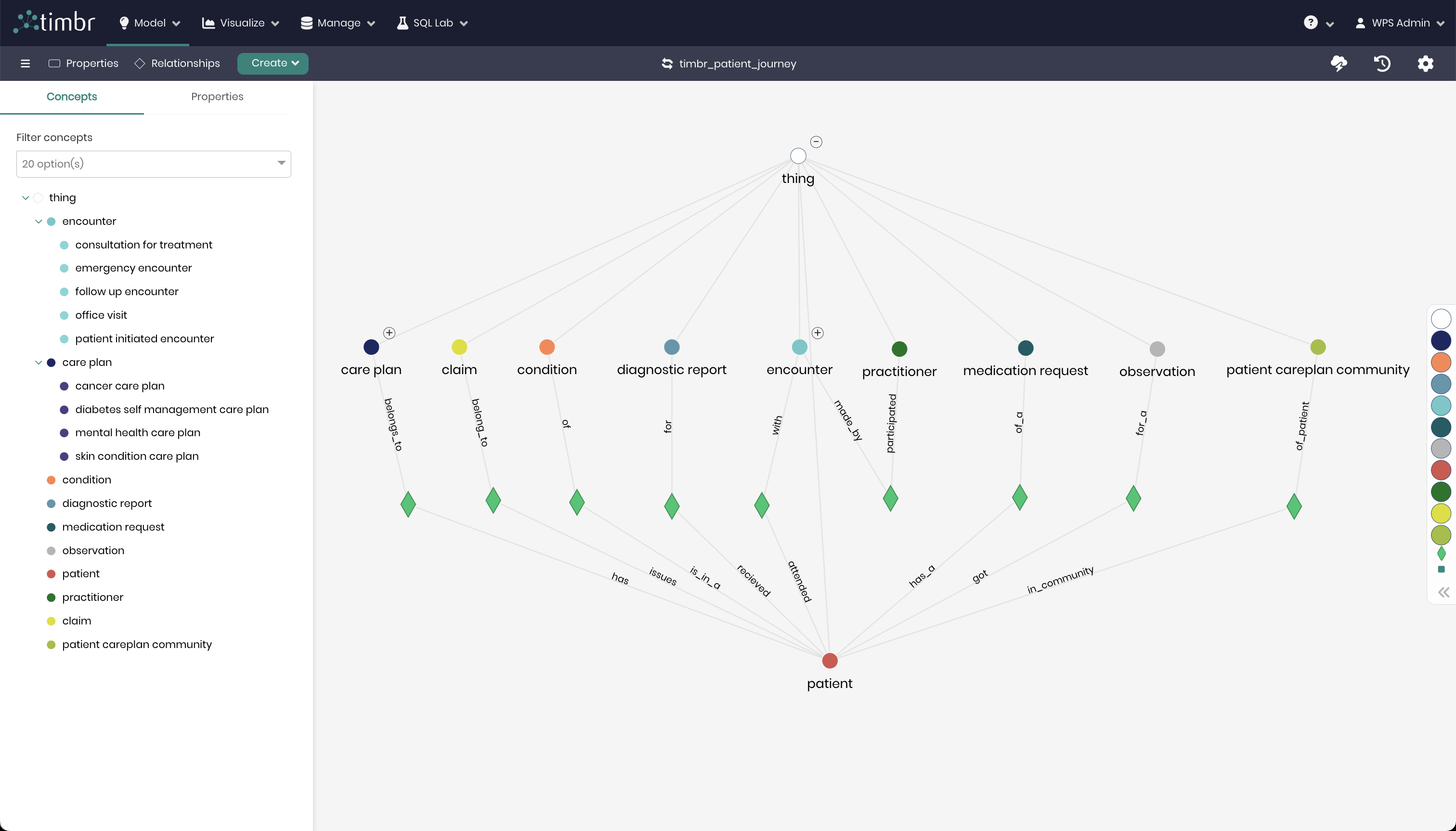
Unleash the power of Data
Relationships
The secret sauce of Timbr data models is the relationships. Relationships between datasets don’t exist in databases and can’t represent the contextual relation between two tables, nevertheless, between two business entities the data represents. Users can connect datasets once a relationship is defined using the explicit relation required in their scenario.
There are multiple types of relationships in the Timbr data model. There are one-to-many relationships, many-to-many relationships, and transitive (recursive) relationships. When leveraging these relationships in a query, behind the scenes, the Timbr platform translates the relationships into JOINs and UNION statements while optimizing the query and reducing the query length by up to 90% to allow any analyst to execute complex queries in a simple and elegant manner.
Centralized Access Controls
Access controls become a crucial feature in maintaining a safe and secure workplace when using a single location to access multiple data sources. Timbr includes enterprise-grade security controls allowing administrators or data owners to provide access on any level of granularity, including RBAC, Data Masking, Policy Controls, and even synchronizing with AD Groups for automated access control. The platform also includes an end-to-end version control to support rollbacks and log reviews.
Decoupling the data model from the sources and target tools
Another valuable aspect organizations get when applying a semantic graph data management platform like Timbr is decoupling the data model from the source databases or the consumption tools. Database administrators can now easily monitor which datasets and views are being used by the organization and can quickly identify risks of removing or changing the underlying sources. The same applies to the consumption tools where most modeling tasks occur. Teams using different applications can now share the same metrics and datasets while working on completely different projects with their dedicated tools.
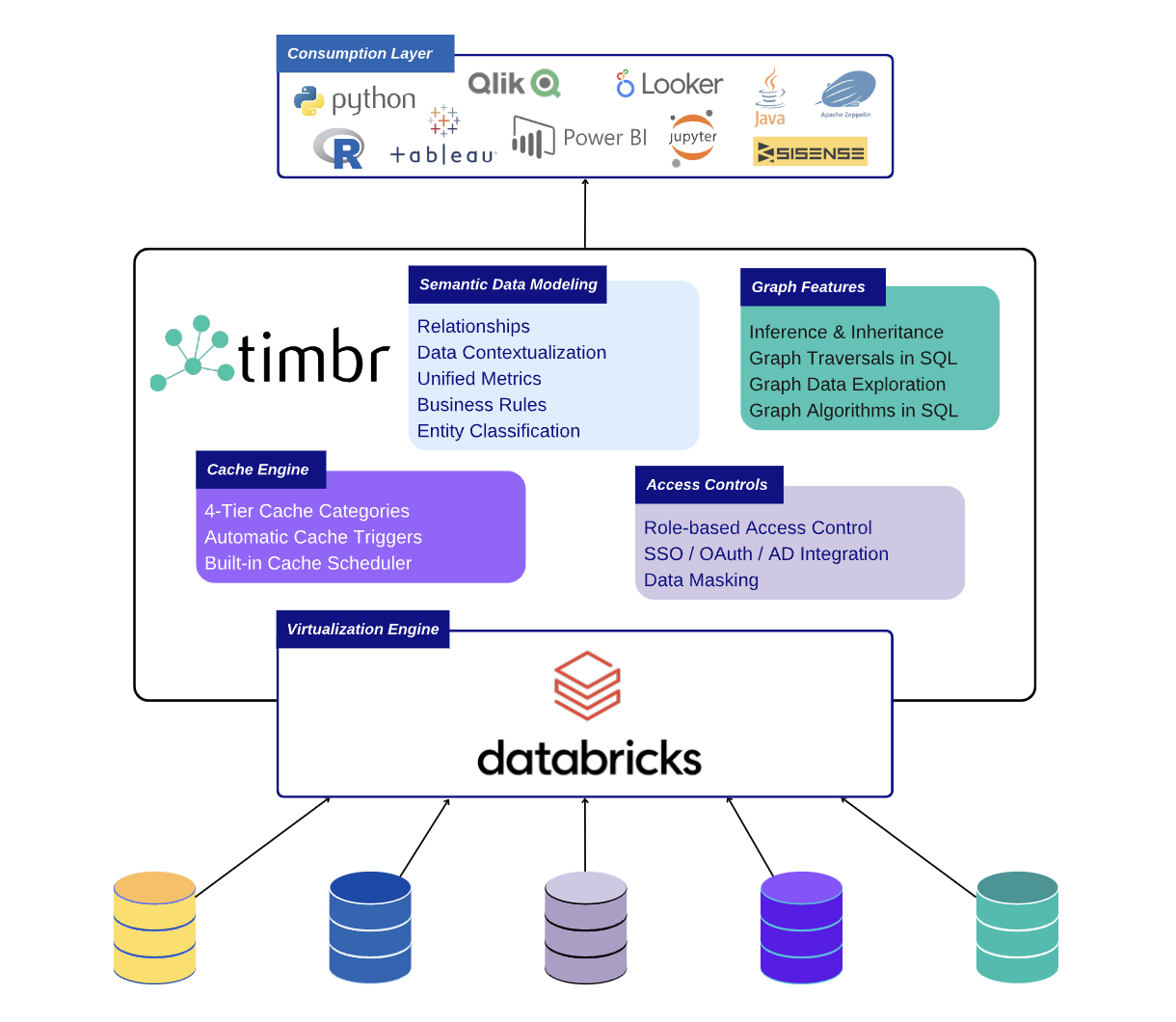
Semantic Data Virtualization: a Timbr-Databricks love story
Timbr combines with Databricks to deliver a powerful virtualization engine, enabling ultra-fast processing of large-scale data scattered across multiple databases. Users can conveniently consume distributed or siloed data and join the information using a Databricks cluster as the execution engine.
This combination of a semantic graph data model, together with powerful execution engines, opens a new world of possibilities for organizations. The acceleration of analytics with 90% less code, using unified semantic data models while querying across multiple sources and data types, not only helps companies accomplish data strategies but also introduces a new era of data-driven initiatives in a cost-effective approach.
These core capabilities alone are a great addition to any architecture on any cloud or on-prem instance. To enable access to data in a simple and explicit method for new or experienced data practitioners while using a data platform that entails and maintains all the business context related to the data eliminates most of the technical difficulties and constraints data users face when approaching a task or a project.
Time-to-value of data projects decreases dramatically as data discovery and sharing becomes a natural and easy task for any user. Users can now focus on extracting insight from the data instead of dealing with siloed in-app modeling or transformations.
Data Consumption from any tool in any format
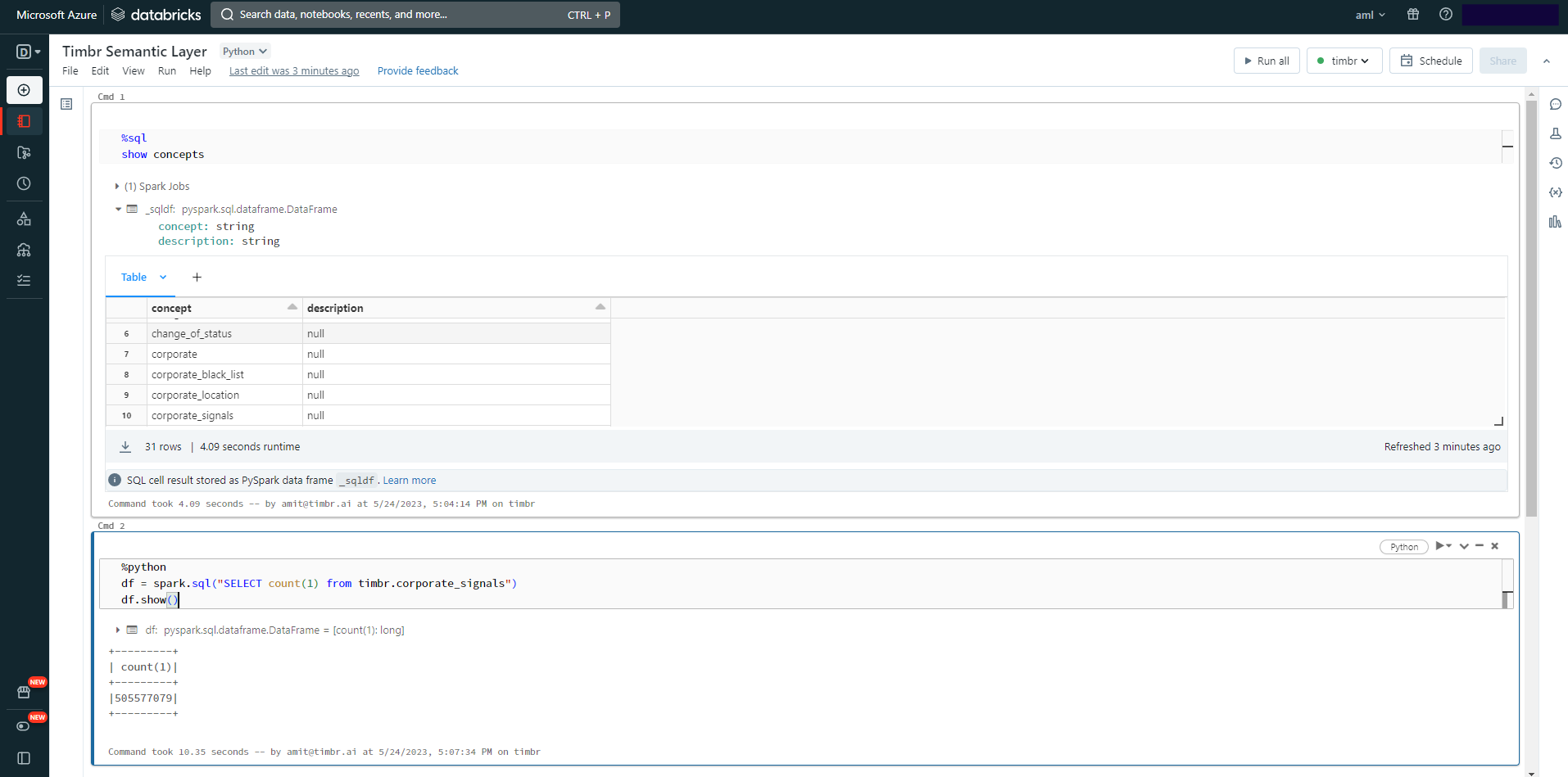
Leveraging the connectors of Databricks, Timbr exposes data in any format to every tool. Connecting Business Intelligence applications or Data Science tools is seamless. The semantic data model is exposed to the tools with the relationships and metrics, so users can query and use the model directly from their tools. The semantic model can be queried in SQL, Java, Scala, R, and Python so users can leverage the intelligent data model for every data project.
An intelligent Cache to improve the performance
Using a data virtualization tool always comes at a cost since not all the connected data sources provide the same performance. To address this challenge, the Timbr platform also includes an intelligent 4-tier cache engine that allows users to cache in the Local Database, in a Datalake, on SSD, or In-memory. Depending on the data project’s speed requirements, users can promote or demote the cache between the tiers and maintain a cost-effective approach to improving performance. The cache has automated triggers for users to materialize according to a specific time or CRON job and can refresh the cache incrementally based on a partition. When caching into the Datalake, Timbr uses delta format allowing organizations to essentially move into a “Lakehouse Architecture”.
Timbr & Databricks native integration
Databricks users? You will love this native integration feature! Now you can get the virtual data model directly in Databricks to query the business concepts instantly from the notebook. Besides querying, Timbr also exposes the metadata in the Unity Catalog for convenient governance, and users can enable SSO from Databricks to Timbr to align security and access controls.
Conclusion
In times when data is the most valuable commodity, solutions that allow fast, intuitive, and accurate work are essential for any data-driven organization. Scalable data models are vital for maintaining a holistic business view of the data to extract meaningful insights from big data. Timbr’s integration with Databricks offers just that, introducing a powerful combination to harness the benefits of semantics and connected data for lightning-fast unified analytics engines.
By leveraging Timbr’s native integration with Databricks and its transformation capabilities, organizations can create scalable semantic graph models and maximize the utilization of their data. The integration allows organizations to query across all data sources, use contextual relationships, accelerate complex analytics, and make data-driven decisions with confidence.
Contact us today to create your Semantic Layer with Databricks.

