
Introduction
Timbr is the intelligent semantic layer based on SQL knowledge graph technology.
What are the differences between Timbr and graph databases?
Google introduced its Knowledge Graph project in 2012 in order to enhance their search result quality. It also sparked a market for enterprise use of knowledge graphs. Timbr.ai disrupted the knowledge graph skyline in 2020 by introducing SQL ontologies as the basis of semantic layer modeling.
So, what makes Timbr so special?
About Structures
What are the ways one can understand and learn about a new structure?
Structures can be material (man-maid objects such as buildings, natural ones such as animals), or abstract (scientific or social theory, software, music, games). They define the relationships and arrangements between their constituting elements.
One way to understand a structure is to learn of its function or purpose; another is to dismantle it and look at the different parts and their interactions. Yet another way to understand a structure is to learn about its constraints (or limitations). In other words, what the structure is by what it cannot be.
These are the set of fundamental “rules” the structure is adhering to which cannot be violated, the backbone upon which it is built. The constraints of any material structure (at least macro structures) are at the very least Newton’s laws. The structure called “soccer game” has a basic constraint: “no hands”. Understanding this limitation will reveal the most apparent part of the game in action. A deeper understanding is gained when one masters the “offside” constraint (which results in a more dynamic progressive offensive and defensive maneuvers). To appreciate the architecture of a building, one must learn the various constraints (topography, urban, environment, culture, architecture style) in effect upon its construction. In many cases, a structure’s constraint is also the source of its beauty.
Timbr Intelligent Semantic Layer
To understand Timbr, a virtual knowledge base (KB) for the relational world, a major self-imposed constraint of the product must be comprehended:
Support standard SQL as the querying language interface.[1]
Our mission is to bring the gospels of ontologies to the classic (and conservative) world of vanilla SQL clients and backends. This means that when querying the KB, standard SQL with no modifications (albeit including support for various backend dialects) is used. This constraint opens up great possibilities but limits others.
Ontologies
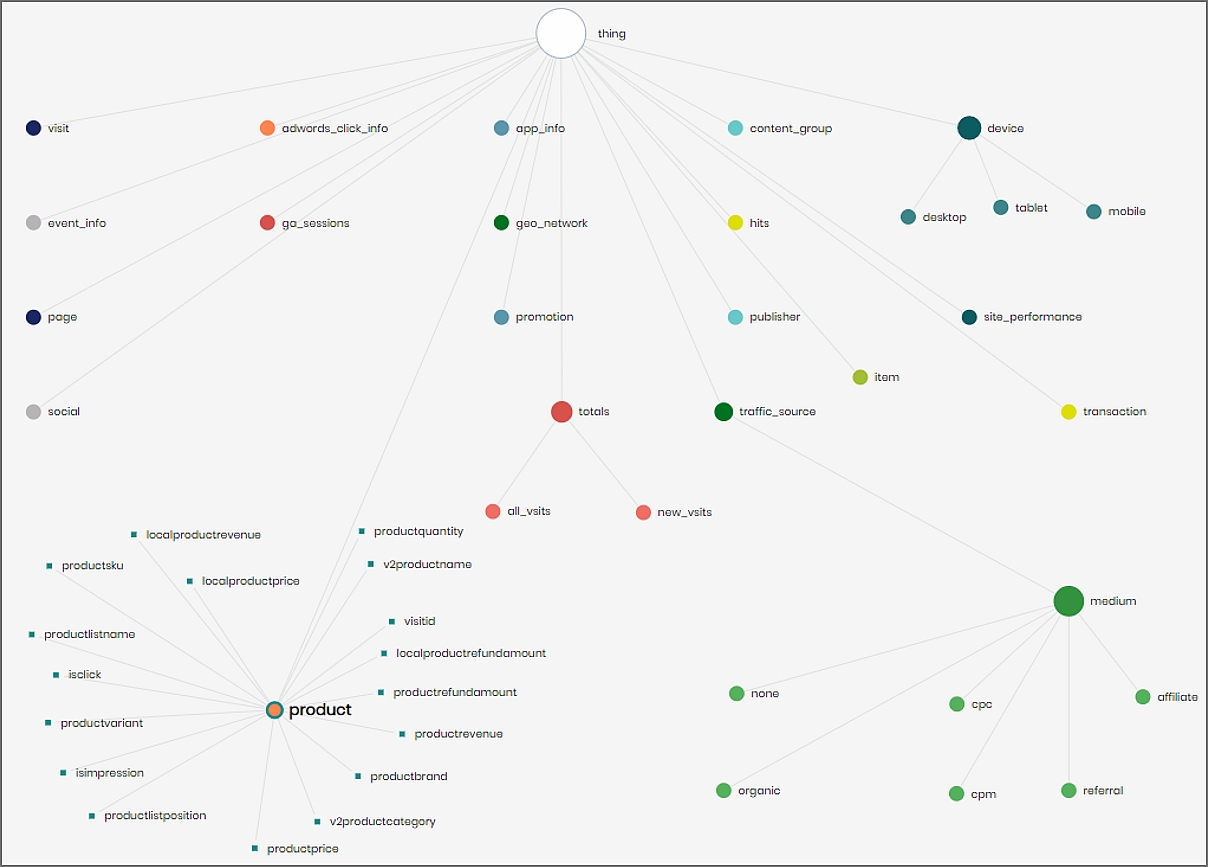
Basically, ontologies are graph + inference rules (or formulas). The inference rules contribute to the graph in two main areas:
- Implicitly add vertices and/or edges to the graph
- Limit the valid structure of the graph.
Inferencing rules govern the abstract structure of our knowledge base, while the underlining graph is comprised of “facts”: depicting individuals, their data values and their relationships. Not surprisingly, this is a pretty good imitation of the way we think about things in general, i.e., the structure of thought.
For example, we can define a “Person” class (an abstract entity), as well as some properties (also abstract entities): “id” of type string, “age” of type int (in OWL 2.0, they are called data properties) and “friend” of type “Person” (in OWL 2.0, object properties).
Notice how these rules contribute to (2) above. We declared some abstract entities and limited the structure of a valid graph. Technically, property “id” range are strings, property “age” range are integer values of 0 to 120 and property “friend” range are individuals of type “Person”. Note these are all in fact inferencing rules. The last one states:
a. friend(x,y)->Person(y)[2]
Hence, every target of a “friend” relationship (y above) is a member of the “Person” class.
We can further declare an “Animal” class, and add the rule:
b. Person(x)->Animal(x)
The above states that every individual that belongs to the “Person” class, also belongs to the “Animal” class. In other words: Person is a subclass of Animal.
We can then define a known characteristic of friendship:
c. friend(x,y)->friend(y,x)
The above rule states that the “friend” property is symmetrical.
Now, if we explicitly add 2 untyped individuals to the graph:
- Alice, age = 30
- Bob, age = 28, friend = Alice
The above inference rules (a, b and c) implicitly add “new” (inferred) facts, such as: Alice is a “Person”[3], Alice has a friend named Bob, and Bob is an “Animal” (exercise: try to trace these inference steps).
In summation, an ontology is a deduction system comprised of two main parts:
- graphs of individuals, i.e. concrete entities, with data properties and their relationships
- inferencing rules governing the relationship and characteristics of abstract entities.[4]
Graph databases
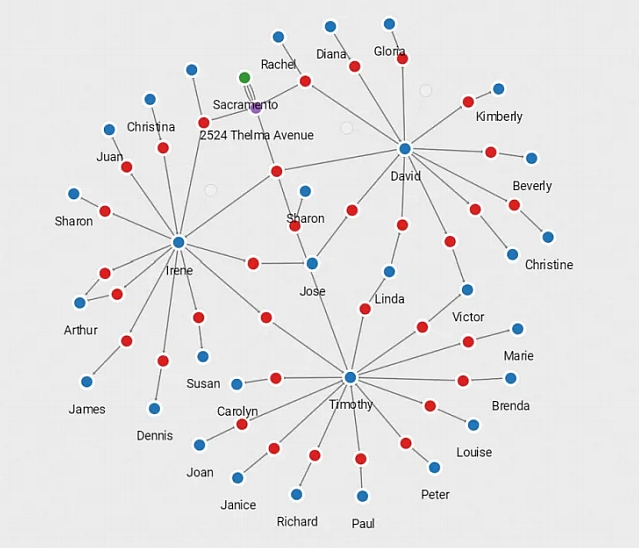
Graph databases, for the most part, are the medium by which “facts” can be stated as interconnected sets of vertices and edges without support for inferencing rules. For Alice and Bob above, their friendship will remain one sided, and a query for all vertices who are people (i.e., of type “Person”), will return zero vertices, since no explicit indication exist as to either Alice or Bob’s type.
Now, graph databases specialize of course in graph traversals. Their query language (Cypher, Gremlin, Sparql or a multitude of others) are largely built around the notion of graph patterns for selection. We can easily ask for all the friends of Bob, up to the third degree (or infinite degrees), who’s “age” is less than 20.[5]
Timbr is mainly focused on enhancing Big data and enterprise relational backends with ontological capabilities, queryable in a standard SQL. Its graph traversal capabilities are therefore more limited since there is no support for graph “pattern” filtering in SQL.
We do support “basic” traversal through our dereferenced schema (dtimbr), which allows querying individuals not just by their intrinsic properties, such as “age” above, but also their neighbors’ properties. So, in “dtimbr.Person” we will have, in addition to “id”, “age” and “friend”, having “friend.age” and even “friend.friend.age”[6] columns.
You can then filter based on these columns, but this is not as powerful as the pattern capability of graph db.[7] We do claim, arguably, that our support is good enough for an extensive set of requirements.
Why Timbr does it differently?
Because of the fundamental constraint of our product structure, as stated above, Timbr essentially maps the 3D world of ontologies (graph + inference) into the 2D world of relational model, queryable by standard SQL. We devise multiple technics and optimizations to enable this, and while remaining bounded by the language itself, we attain our objective of compatibility with the SQL ecosystem.
We could have added a MATCH pattern filter statement to our SQL language, but then it becomes our SQL language. Once we’d done that, we would not have had the same product we set out to build. Fundamentally, we want you to be able to use whatever querying tool (and existing SQL knowledge) you already have to query data, with Timbr transparently adding ontology capabilities to an existing schema.
Existing tools (BI and other client tools) use JDBC/ODBC interfaces and generate, for the most part, standard SQL. The above imaginary MATCH construct will be opaque to them. dtimbr schema thus allows some basic graph traversal operations which we believe are useful in most cases[8].
The SQL Ecosystem empowered by SQL Ontologies:
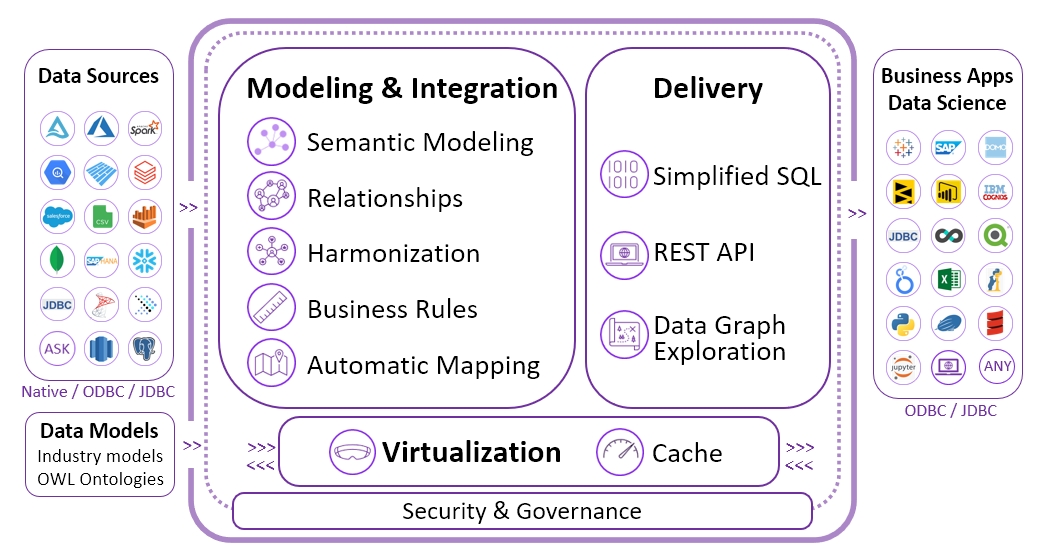
Head to Head
The following are the main differences between Timbr and graph DBs such as neo4j, SQL Server Graph DB, Amazon Neptune, DataStax Graph, Orient DB and others:
They are all “bottom-up” graph db implementations. Some of them are built on top of a relational backend, and some have propriety execution engine and file format. But none are built fundamentally to be a virtual layer, rather as a physical implementation. This means ETL is needed to move data from its original, most likely relational, source.
Notice some consequences of that:
a. Data staleness is a necessary side effect, as well as complex ETL processes which are time consuming and hard to maintain.
b. Big Data limitation: loading all your data lake to a single graph DB may prove unfeasible.
c. No unified model across data sources: Timbr supports running over a virtualization layer (by default Spark, but any JDBC complained virtualization engine would do). This allows declaring an enterprise level, overarching ontology that integrates data from multiple data sources. So “Person” class above can encompass customers from the CRM DB, company employees from SAP system, and suppliers from some external source.
d. Schema evolution: Most graph engines above are considered “No-SQL” and therefore “schema-free”. In reality, most client implementations use strict schemas, and for good reasons. At any case, a schema change might entail a possibly huge rewrite of data. In Timbr, since the ontology layer is virtual, schema changes are done in the blink of an eye.
They have no ontology support, rather a simple graph schema (vertices and edges depicting “facts”). Therefore, no class inheritance or other inference rules.
They do support complex path and/or pattern operations over the graph. As stated, Timbr has a much more basic support for graph traversals. Moreover, graph traversals, especially more complex ones, are likely to run faster in a graph DB.
Most have no support for standard SQL query. Some have variations of proprietary SQL extensions, but generally, SQL is frowned upon in this niche market. As we believe SQL is Lingua-franca for most frontends/backends, Timbr is 100% SQL compatible.
Of course, some graph DBs (many of which are dubbed triple stores), do have built-in support for inferencing rules, with different strategies for implementing them. These are “true” knowledge bases, but Timbr is still differentiated from most of them as per points (1,3,4) above.
Concise Queries Comparison
Graph DBs appeal to users because of the short queries required to explore relationships in comparison to standard SQL queries. Timbr’s introduction of SQL ontologies that encapsulate relationships, allow users to enjoy the same concise queries, but in a more familiar SQL language (semantic SQL).
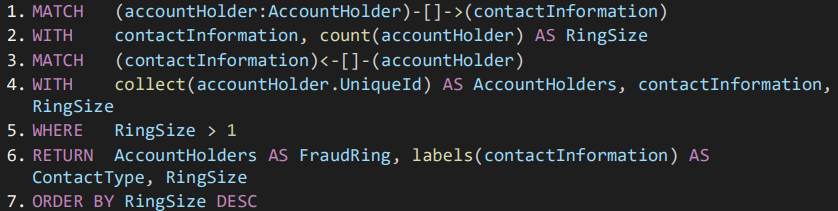
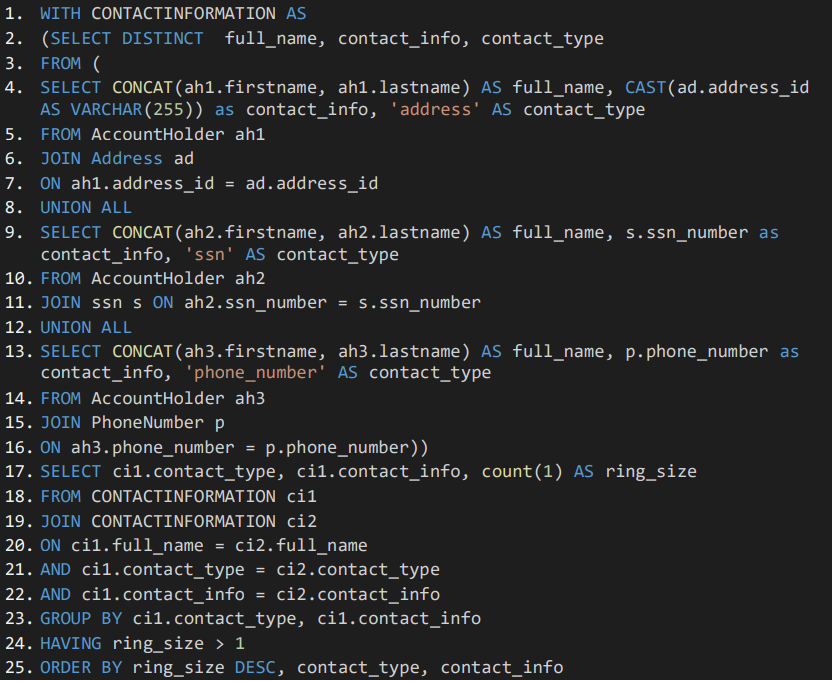
To illustrate the power of Timbr’s semantic SQL, let’s look at a query comparison between Neo4j, standard SQL and Timbr’s Semantic SQL, answering the following question from Neo4j’s Fraud Detection Use-case: Which account holders share more than one piece of legitimate contact information?
Query in Neo4j’s Cypher:
Query in standard SQL:
Query in Timbr’s semantic SQL:

From the above example we can appreciate that Timbr’s SQL queries are of similar size as those made in Cypher.
Conclusion
Timbr virtual SQL ontologies introduce a new paradigm that leverages the huge SQL ecosystem, modernizes databases without adding to, or changing the organization’s IT infrastructure and delivers a universal solution for linking heterogeneous data sources and enabling smart data.
Compared to GraphDBs, Timbr features provide the vast majority of needs for advanced analytics while offering the convenience of SQL, so data consumers do not need to learn new skills.
Notes:
[1] Note this is not “SQL-like”, or “SQL+extentions” or “SQLish” language. Our DML querying (i.e., SELECT statements) are 100% standard SQL. Our DDL (ontology authoring such as CREATE CONCEPT/PROPERTY/MAPPING) does include extensions to SQL but these statements are consumed completely by the virtual layer and are not “seen” by the backend.
[2] This notation uses the implication connective (->), “friend” is binary predicate (designating a relationship), and “Person” a unary predicate designating a class.
[3] Notice there is no explicit indication as to Alice or Bob’s type.
[4] Other examples of inferencing rules allow us to define classes based on set operation. For example: “Mother” as an intersection of “Woman” and “Parent” classes. formally: Woman(x),Parent(x)->Mother(x) . The above is possible in OWL 2 but we can’t define more elaborate definitions. Conversely in Timbr, we can define “Adult” class to be a subclass of “Person” such that “age” > 18.
[5] Some also have strong support for global graph algorithms such as shortest path, page rank and other centrality and community detection algorithms.
[6] The traversal depth is configuration dependent.
[7] Timbr does have support for some global graph algorithms, but these are advanced capabilities and outside the scope of this post. Also note that many graph pattern operations can be translated to SQL, which the client can execute directly (using combination of UNION and JOIN operations), but this may not be a straightforward task.
[8] Though, it may not be a full replacement for complex graph pattern matching.
Are you using your data strategically?
Timbr virtually transforms existing databases into semantic SQL knowledge graphs with inference and graph capabilities, so data consumers can deliver fast answers and unique insights with less effort.
With Timbr, your organization can join the knowledge revolution.

