
What Is GraphRAG?
Definition, architecture, and enterprise use cases
What Is GraphRAG?
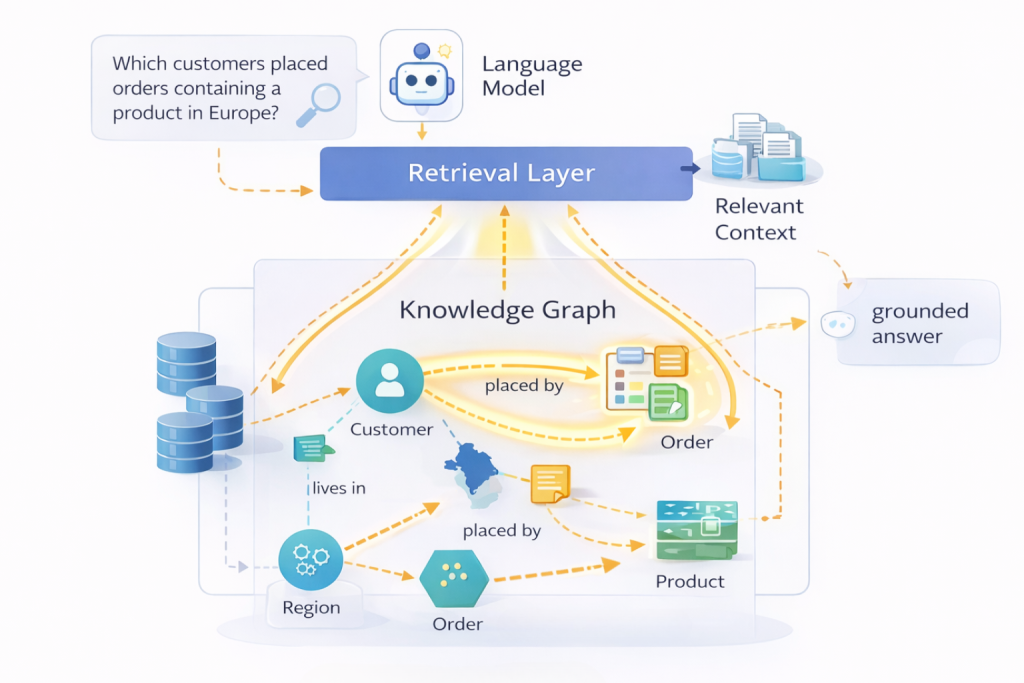
GraphRAG (Graph-based Retrieval-Augmented Generation) improves AI responses by using knowledge graph structure to guide how information is retrieved and assembled for large language models. Rather than relying solely on vector similarity, it uses explicit relationships between entities to assemble context that reflects how data is truly connected. This makes GraphRAG particularly relevant for enterprise use cases where accuracy, traceability, and contextual correctness matter.
Within an AI architecture, GraphRAG sits between enterprise data and the language model. The knowledge graph defines entities and relationships, while the retrieval layer uses that structure to determine which facts, connections, and paths are relevant. The language model then operates on curated context, focusing on reasoning and synthesis rather than inferring meaning from loosely related text. This shifts responsibility for correctness and context away from the model and back toward the data and semantics enterprises already manage.
How GraphRAG Differs From Traditional RAG
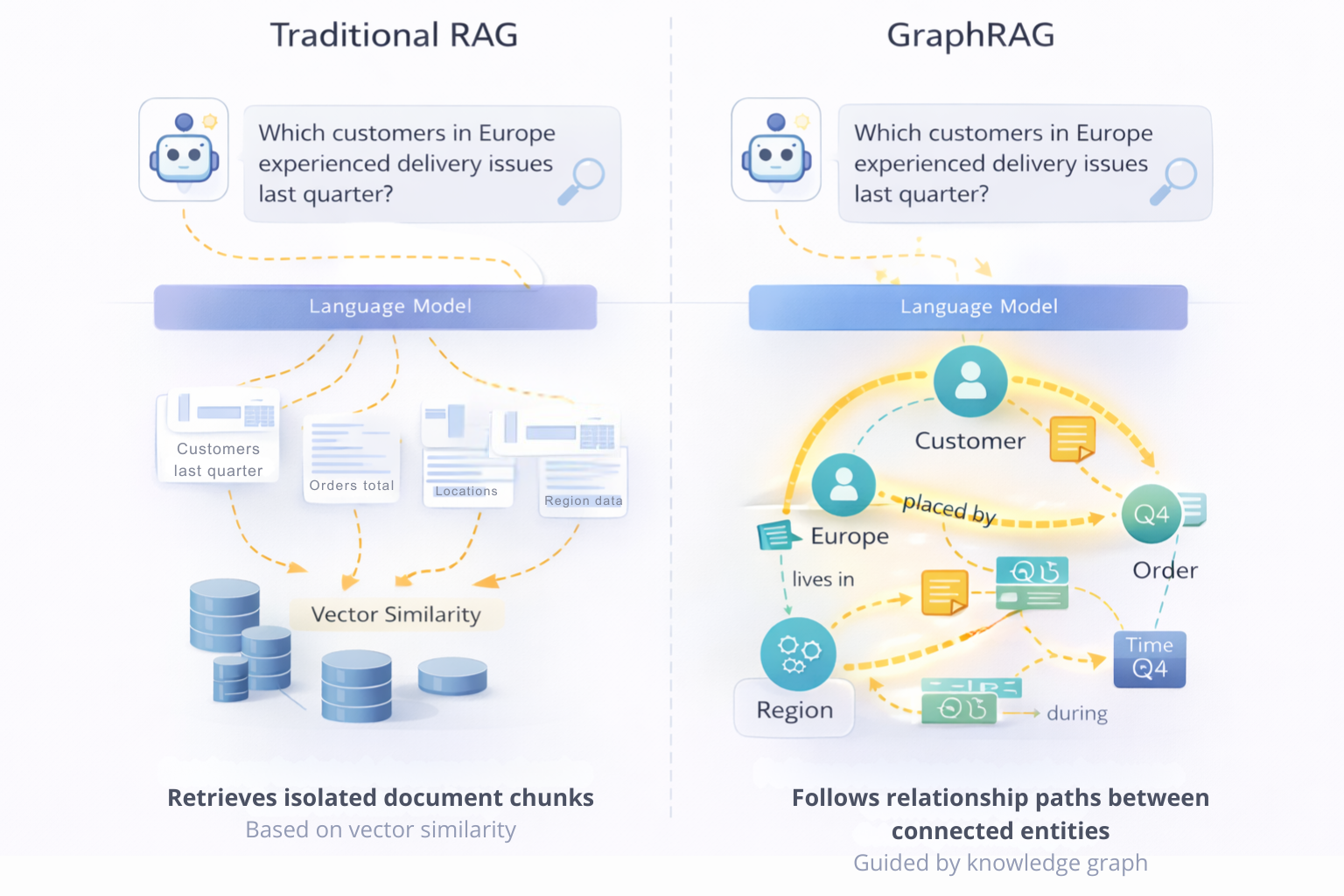
Traditional retrieval-augmented generation (RAG) improves language model responses by retrieving relevant text from external sources and supplying it as context for generation. In most implementations, retrieval is driven by vector similarity, where documents or chunks are embedded and ranked based on query proximity. This approach works well for surface-level questions and loosely structured content, but it treats retrieved information as largely independent fragments.
GraphRAG differs in how it constructs context. Instead of assembling isolated text chunks based solely on semantic similarity, GraphRAG uses the structure of a knowledge graph to determine what information is relevant and how different pieces of information relate. Retrieval is guided by entities and explicit relationships, allowing the system to assemble context that reflects real-world connections rather than coincidental textual overlap.
In a traditional RAG system, a query such as “Which customers in Europe experienced delivery issues last quarter?” may retrieve documents mentioning customers, Europe, delivery, or time periods independently. While semantically similar, these documents are not necessarily connected in ways that support precise reasoning. The language model must infer relationships across loosely related text, and responses may be fluent yet grounded in fragmented context.
With GraphRAG, the same query is interpreted through graph structure. Customer entities, regions, orders, delivery events, and timeframes are explicitly connected. Retrieval follows these relationships to assemble a coherent set of facts that are already meaningfully linked. The resulting context reflects actual customer-order-region-issue relationships, giving the language model a grounded basis for reasoning.
This distinction becomes more important as questions grow more complex. Vector-based RAG is reconstructive, it attempts to infer meaning from similarity across fragments. GraphRAG is navigational, it follows known paths between entities to determine what information should be considered together. The difference is not about better language generation, but about greater control over the context the model reasons over.
GraphRAG does not replace vector search. Many implementations use embeddings to identify starting points, but graph structure governs how retrieval expands and which connections are followed, reducing reliance on the model to infer existing structure.
Core Components of GraphRAG
At a high level, GraphRAG combines structured knowledge with retrieval techniques to control how context is assembled for large language models. While implementations vary, most GraphRAG systems rely on a small set of core components that work together to ensure retrieved information is relevant, connected, and contextually valid.
The foundation of GraphRAG is a knowledge graph. The graph represents key entities such as customers, products, transactions, locations, or regulations, and the explicit relationships between them. These relationships encode how information is connected within a business domain, providing semantic structure that retrieval can rely on. Unlike unstructured documents or flat tables, the graph makes relationships first-class, allowing retrieval to follow meaningful paths rather than infer connections after the fact.
On top of the graph sits an entity-aware retrieval layer. When a user submits a query, the system identifies relevant entities and uses them as entry points into the graph. Retrieval then expands by traversing relationships that are valid for the question being asked, such as ownership links, hierarchies, temporal relationships, or other domain-specific connections. The goal is not to retrieve everything that appears relevant, but to retrieve information that is connected in ways that preserve business meaning.
Many GraphRAG systems use embeddings to identify initial candidate entities or starting points. Vector similarity surfaces semantically related concepts, while graph structure governs how retrieval expands, which paths are followed, and which information is excluded.
The language model consumes the retrieved context. In well-designed GraphRAG systems, it is not responsible for deciding which facts are relevant or how they should be connected.
Instead, it reasons over the curated set of entities, relationships, and facts provided by the retrieval layer. GraphRAG places control over context assembly in the data and retrieval layers, allowing enterprises to govern meaning and correctness independently of language generation.
Together, these components define GraphRAG as a retrieval-first approach, where the graph determines what can be connected and the language model focuses on interpretation and synthesis.
What Is GraphRAG Used For?
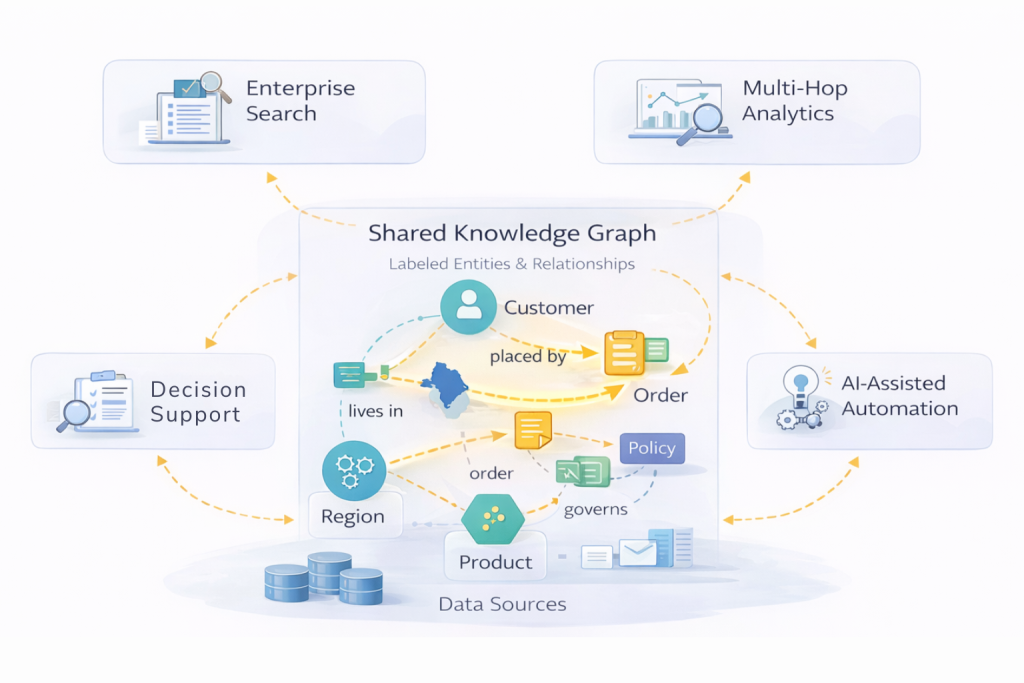
GraphRAG is most useful where accuracy depends on understanding how information is connected, not just what exists. It is typically applied where context must be precise, complete, and traceable, particularly in enterprise environments with complex relationships, ambiguous entities, and multi-step reasoning. GraphRAG reduces risk by assembling context based on validated connections rather than semantic similarity.
Enterprise Search and Question Answering
GraphRAG is commonly used for enterprise search and internal question answering across complex systems. Large organizations store relevant information across contracts, policies, transactional systems, operational databases, and documentation platforms. While traditional search can surface documents that mention relevant terms, it often fails to reflect how those pieces of information relate to one another.
GraphRAG allows questions to be resolved by following explicit relationships in the underlying data model. Determining which customer owns which account, which orders were affected by a specific issue, or how a regulation applies to a product line requires navigating ownership, hierarchy, and applicability relationships that are rarely captured in text alone. GraphRAG enables answers that reflect how the business actually operates, not just how information happens to be written.
Multi-Hop Analytical Questions
GraphRAG handles multi-hop analytical questions that require combining information across multiple domains. Questions such as “Which customers in EMEA experienced delivery delays in Q4 and were covered by premium service agreements?” cannot be answered reliably by retrieving isolated documents.
While vector-based retrieval may surface documents related to customers, regions, delivery issues, or contracts independently, GraphRAG assembles a coherent set of facts by traversing existing relationships between entities. This allows reasoning across customers, regions, orders, time periods, and contractual terms in a controlled and semantically valid way, rather than relying on the language model to infer connections from loosely related text.
Decision Support in Regulated or High-Risk Domains
In regulated or high-risk domains such as finance, healthcare, supply chain, or compliance, answers must be explainable and auditable. Organizations need to understand why conclusions were reached and which facts contributed.
GraphRAG supports this requirement by grounding responses in identifiable entities and relationships. A risk assessment, for example, can be traced to a specific customer being linked to a restricted entity through a defined ownership or transaction path, rather than to documents that merely resemble the query. This traceability makes it easier to audit decisions, justify actions, and align AI outputs with governance expectations.
AI-Assisted Workflows and Automation
GraphRAG is increasingly used as a foundation for AI-assisted workflows and automation. When AI-generated outputs are used to route cases, flag risks, trigger follow-up actions, or support operational decisions, the quality of retrieved context becomes critical.
If retrieval assembles incomplete or invalid context, downstream systems may act on incorrect assumptions. GraphRAG reduces this risk by ensuring automated workflows are driven by context that respects business rules, entity boundaries, and domain constraints.
When GraphRAG Is Not the Right Fit
GraphRAG is not necessary for every retrieval task. Simple queries, exploratory research, or broad discovery can be handled with vector-based RAG. GraphRAG introduces modeling and governance overhead, justified when correctness and control outweigh simplicity.
The Enterprise Reality
In theory, GraphRAG improves AI responses by grounding retrieval in structured relationships. In practice, deploying it in enterprise environments exposes challenges invisible in demos. The difficulty is not the concept, but operating it reliably at scale across domains, sources, and teams while controlling what is retrieved and combined.
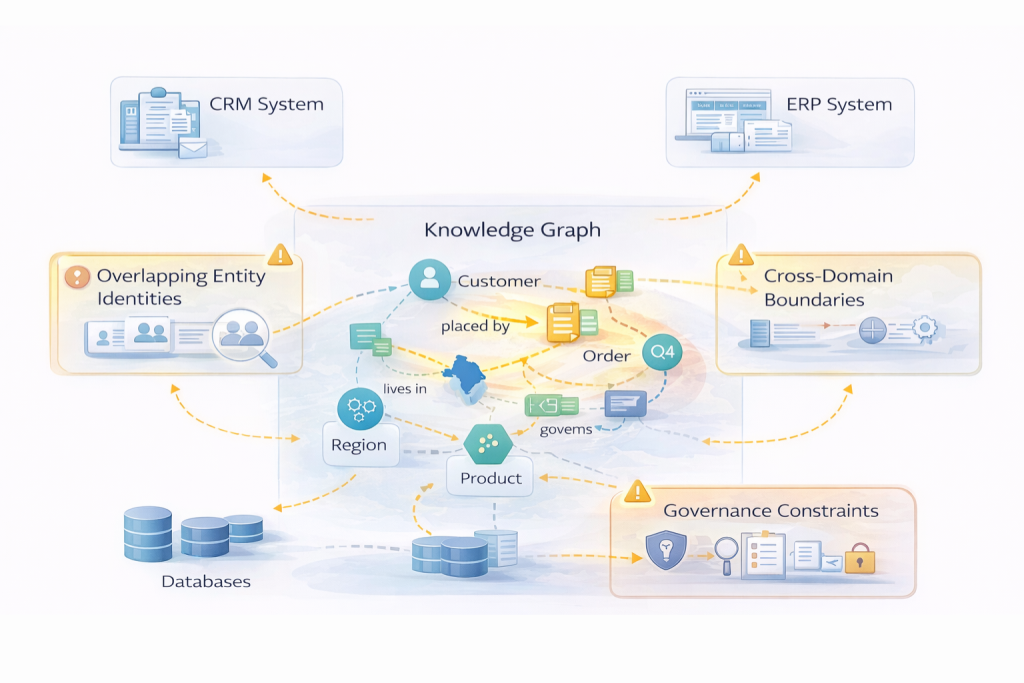
Retrieval Scope Control
Knowledge graphs often contain millions of interconnected entities. Without clear boundaries, traversal can expand too far, pulling in information that is technically connected but contextually irrelevant. Determining which relationships are valid for a given question and when traversal should stop requires explicit rules and domain understanding. Without this control, a query about a customer may traverse to their orders, then expand into unrelated product lines or peer customers that are technically reachable yet contextually irrelevant.
Multi-Domain Context Management
Enterprise knowledge graphs often span multiple business domains such as finance, operations, legal, and customer data. While these domains may be connected at a high level, they are not always relevant to the same questions.
GraphRAG systems must distinguish between legitimate cross-domain connections and accidental data overlaps. Without careful design, retrieval can mix concepts that should remain separate, leading to answers that blur responsibilities, policies, or interpretations, particularly in environments where regulatory, contractual, and operational boundaries matter.
Entity Disambiguation at Scale
Enterprises frequently reuse names, identifiers, and terms across products, regions, and organizational units. A query involving a familiar name may refer to a customer, a subsidiary, a product line, or a legal entity, depending on context.
If the underlying graph does not resolve these identities consistently, GraphRAG may retrieve information about the wrong entity with high confidence. The system returns well-structured, authoritative answers about the wrong entity, making errors harder to detect than simple retrieval failures.
Governance During Traversal
Not all users should retrieve all information, even if it is technically connected. Access controls, data sensitivity, and regulatory constraints must be enforced during retrieval, not after generation.
Applying governance rules to graph traversal, deciding which paths are allowed for which users and use cases, is significantly more complex than filtering documents after the fact. GraphRAG systems must ensure retrieval respects permissions, data classifications, and compliance boundaries while still assembling coherent context.
Adapting to Continuous Change
Knowledge graphs evolve continuously as new data arrives, definitions change, and relationships are refined. GraphRAG systems must adapt without breaking retrieval logic or producing inconsistent results.
Recomputing summaries, embeddings, or derived structures can be costly and slow. Keeping retrieval behavior aligned with the current state of the data becomes an operational challenge, especially when multiple teams depend on consistent behavior over time.
These challenges indicate that GraphRAG shifts responsibility from the language model to enterprise data, semantics, and governance practices. When those foundations are weak or inconsistently applied, GraphRAG exposes the gaps quickly.
In production environments, the question is rarely whether GraphRAG works in principle. The more important question is what breaks when it is applied without sufficient control.
What Breaks in Production
GraphRAG rarely fails loudly. Instead, it fails subtly by producing answers that appear coherent, well-structured, and confident, but are grounded in incomplete, invalid, or improperly scoped context.
What breaks is not the idea of GraphRAG itself. What breaks is the ability to control it consistently as data volume, organizational complexity, and usage patterns grow.
Entity Ambiguity Breaks Retrieval
GraphRAG relies on entities as entry points into the graph. When those entities are ambiguous or inconsistently modeled, retrieval begins from the wrong place.
Multiple entities often share similar names, identifiers, or attributes across regions, business units, or systems. A query referencing a familiar term may resolve to the wrong customer, product, or legal entity, even though the relationships that follow are technically valid.
Because GraphRAG assembles structured context, the resulting answer can be internally consistent yet fundamentally wrong. These errors are more dangerous than obvious failures, because they are difficult to detect without deep domain knowledge.
Unbounded Traversal Produces Invalid Context
Graphs are designed to connect information. Without explicit limits, traversal can expand far beyond what is relevant to the original question.
This produces context that is technically connected but semantically invalid. Traversal may pull in related entities, historical relationships, or parallel business processes that dilute the intent of the query.
Instead of missing information, the system retrieves too much, assembling a context window that looks comprehensive but obscures the signal with irrelevant facts. The language model then reasons over this inflated context, increasing the likelihood of incorrect conclusions.
Vector Signals Override Graph Intent
Many GraphRAG implementations use embeddings to identify candidate entities or starting points. In production, these vector signals can begin to dominate retrieval behavior.
When similarity scores outweigh graph constraints, retrieval drifts toward semantically related but structurally inappropriate content. This reintroduces the same problems GraphRAG is meant to solve, assembling context based on resemblance rather than validated relationships.
Over time, teams may tune embeddings to improve recall, weakening graph-based controls. What begins as a hybrid approach gradually becomes vector-dominated, with graph structure reduced to a secondary filter.
Retrieval Logic Drifts Across Teams
GraphRAG systems are rarely owned by a single team. Different groups adjust traversal rules, entity mappings, or relevance thresholds to support their use cases.
Without centralized governance, retrieval logic diverges. Identical questions may produce different answers depending on enabled paths, applied abstractions, or encoded assumptions.
This drift undermines trust. Stakeholders lose confidence when consistent questions yield inconsistent answers across time, teams, or applications, even when the underlying data has not changed.
Dynamic Recomputations Become Impractical
GraphRAG systems rely on summaries, embeddings, or derived structures to manage scale. In production, keeping these artifacts current becomes increasingly expensive.
Recomputing embeddings or summaries across large graphs introduces latency, operational overhead, or resource strain. Retrieval may then operate on stale representations that no longer reflect the current state of the data.
This gap between live data and derived context introduces inconsistency, particularly for time-sensitive decisions or automated workflows.
Confidence Increases Faster Than Correctness
The most dangerous failure mode is psychological rather than technical. GraphRAG often produces more fluent, structured, and authoritative responses than simpler retrieval approaches.
As confidence grows, scrutiny decreases. Teams trust outputs that look correct despite incomplete or improper context.
This creates a false sense of reliability. Errors propagate quietly, not because the system is broken, but because it appears to be working too well. By the time issues are discovered, they may have already influenced downstream decisions or automated actions.
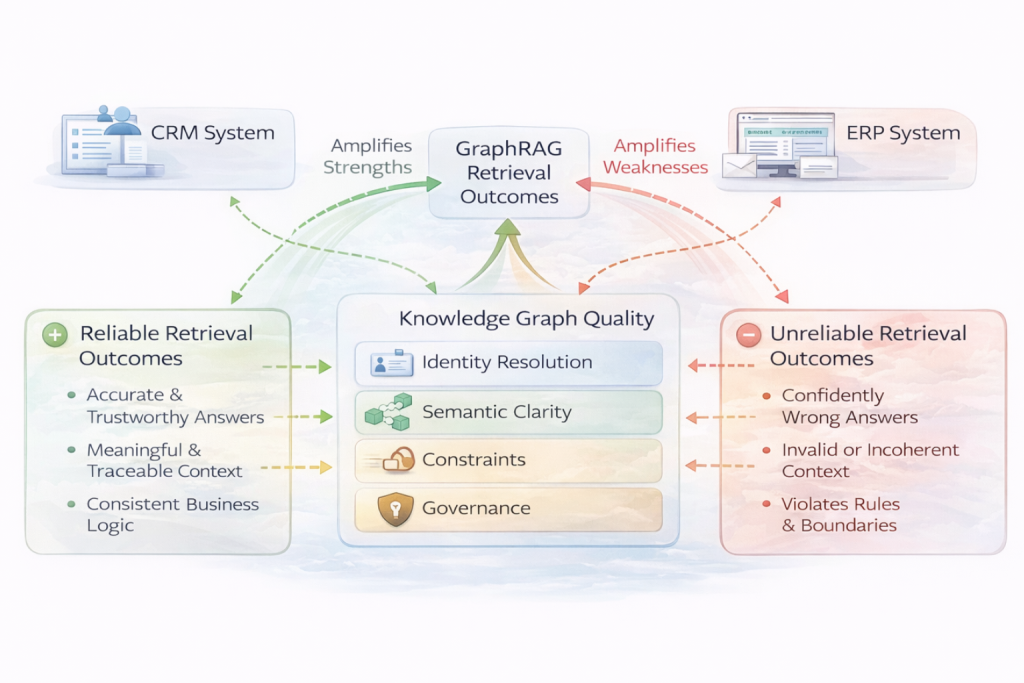
These failures show that GraphRAG amplifies both the strengths and weaknesses of underlying systems.
When identity resolution is inconsistent, traversal rules are unclear, or governance is loosely applied, GraphRAG does not mask those issues. It surfaces them at scale, with confidence.
This is why successful GraphRAG deployments depend less on clever retrieval techniques and more on the strength of the underlying knowledge graph, its definitions, constraints, and governance. That dependency is not incidental. It is fundamental.
Why GraphRAG Depends on the Knowledge Graph
GraphRAG is not a standalone technique. It is a consumer of knowledge graph structure. The quality, consistency, and governance of the underlying graph determine whether GraphRAG produces reliable results or amplifies existing problems.
GraphRAG’s behavior is fundamentally constrained by what the graph makes possible. The graph defines which entities exist, how they relate, and which connections are valid. GraphRAG does not invent meaning; it navigates and assembles what the graph encodes.
Identity Quality Is Inherited
If the same real-world entity appears multiple times in the graph under different identifiers, GraphRAG has no reliable way to reconcile them during retrieval. Traversal paths may appear valid, but they originate from fragmented or incorrect representations.
GraphRAG may retrieve partial, duplicated, or conflicting context while presenting it as coherent. The failure is not retrieval logic, but identity resolution. When identity is inconsistent, GraphRAG retrieves confidently from the wrong starting points.
Semantic Clarity Is Inherited
GraphRAG relies on relationships to determine which information belongs together. If those relationships are loosely defined, overloaded, or ambiguous, traversal becomes semantically unsafe.
For example, if a graph links a customer to a product without specifying whether the relationship represents ownership, eligibility, interest, or history, GraphRAG cannot determine which paths are meaningful for a given question. It may assemble context that is technically connected but semantically invalid.
GraphRAG does not improve semantic clarity. It exposes the absence of it.
Constraints Are Inherited
Knowledge graphs encode relationships and constraints on how they should be used. These constraints may govern time, domain boundaries, applicability, or business rules.
When constraints are weak or unenforced, GraphRAG has no mechanism to prevent inappropriate traversal. It may connect entities across domains, timeframes, or contexts that should remain separate. The resulting context can appear comprehensive while violating business logic or governance boundaries.
GraphRAG follows what the graph permits. It does not decide what should be permitted.
Governance Is Inherited
In enterprise environments, governance is inseparable from meaning. Who is allowed to retrieve which information, under what conditions, and through which paths is part of the system’s semantics.
If governance rules are applied outside the graph or inconsistently enforced, GraphRAG retrieval becomes unpredictable and difficult to audit. When governance is embedded into the graph and retrieval logic, GraphRAG becomes traceable and controllable. When it is not, GraphRAG becomes opaque.
The Amplification Effect
GraphRAG does not correct weaknesses in a knowledge graph. It amplifies them.
A well-governed graph with clear identities, explicit semantics, and enforced constraints enables GraphRAG to assemble context that reflects how the business actually operates. A poorly governed graph produces answers that are internally consistent, confidently expressed, and fundamentally wrong.
This is why GraphRAG success is not primarily a retrieval problem. It is a knowledge graph quality problem. Retrieval determines how information is accessed. The graph determines whether that information should be connected at all.
Understanding this dependency is essential to deploying GraphRAG safely and effectively. It’s also why many teams evaluate GraphRAG platforms based on how they model identity, constrain traversal, and enforce governance.
How Timbr Approaches GraphRAG
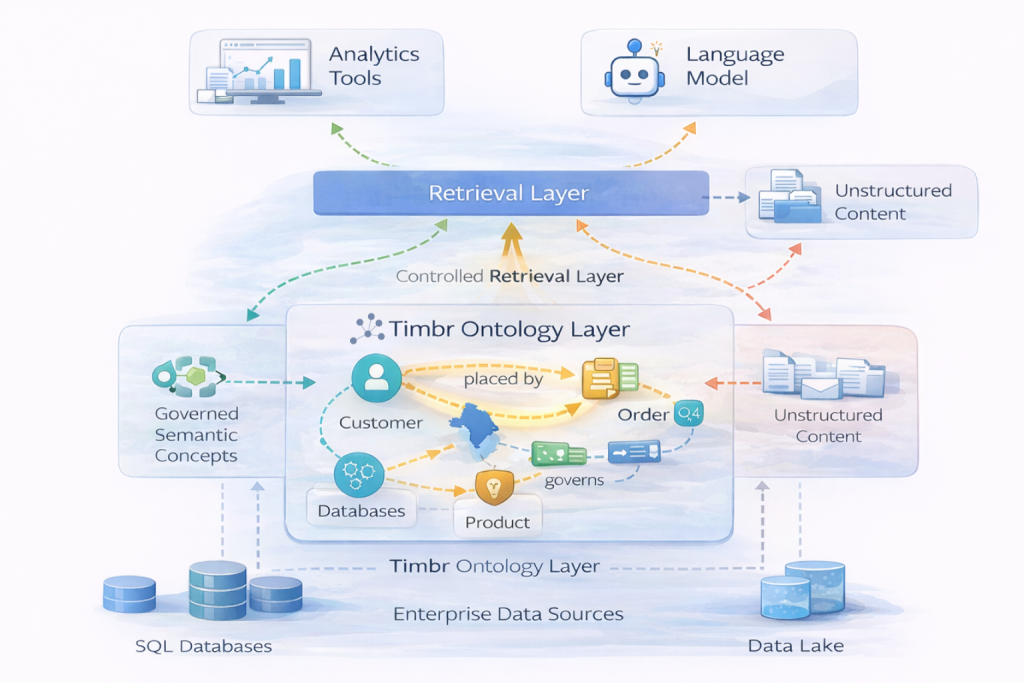
Timbr approaches GraphRAG as a governed retrieval problem over enterprise data, not as a pipeline where a language model infers structure, generates SQL, and interprets schema complexity.
At Timbr’s foundation is an ontology-driven, SQL-native knowledge graph that sits above existing data sources. Instead of forcing data migration into a graph database, Timbr models entities, relationships, hierarchies, and reusable metrics directly on top of relational systems. This turns structured data into graph-addressable context without changing where the data lives.
When a user asks a question, the ontology acts as the primary control plane. Defined concepts serve as units of meaning, explicit relationships define traversal paths, and semantic filters enforce business definitions. The language model handles interpretation and summarization, while meaning and constraints remain governed by the ontology.
Timbr treats structured and unstructured retrieval as complementary. Vector search can surface relevant text evidence, while the ontology supplies governed facts, metrics, and relationship-aware context from structured sources. For hybrid questions, answers can be grounded in structured truth and enriched with documents, without forcing the model to reconcile conflicting fragments or mixed domains.
This approach is designed to reduce the production failure modes that make GraphRAG difficult to trust. Entity ambiguity is addressed through explicit identity modeling, traversal is constrained through defined relationships and semantic scope, and metric consistency is enforced through reusable definitions. Because retrieval is traceable and auditable, teams can inspect how an answer was assembled, not just what the model produced.
In this model, GraphRAG is not more reliable because the language model is more capable. It is more reliable because the graph layer is explicit, governed, and designed to control what the model is allowed to reason over.
Summary
GraphRAG shifts retrieval from text similarity to structure. Instead of assembling context from loosely related passages, it retrieves information through explicit relationships between entities. This allows context to be constrained, navigable, and intentional – which is critical in enterprise environments where correctness, traceability, and clear boundaries matter.
Rather than reducing complexity, GraphRAG exposes it. The approach amplifies both the strengths and weaknesses of the underlying data foundation. When identity is inconsistent, semantics are unclear, or traversal rules are not governed, GraphRAG can produce answers that appear coherent but are fundamentally incorrect.
For this reason, successful GraphRAG implementations depend far more on the quality of the underlying knowledge graph than on retrieval techniques themselves. When business meaning is modeled explicitly and constraints are enforced consistently, GraphRAG supports precise, controlled reasoning over enterprise data. When those foundations are weak, the gaps surface quickly and at scale.
Understanding GraphRAG as a graph-dependent retrieval approach is essential for evaluating where it delivers value, where it introduces risk, and how it should be governed in production environments.
To see how GraphRAG is implemented in practice and how structured graph retrieval is exposed to applications and LLMs, explore the GraphRAG SDK.
