

Introduction
Databricks has established itself as one of the most capable data platforms available today. Built on Apache Spark, powered by Delta Lake, and governed through Unity Catalog, it gives organizations the infrastructure to store, process, and manage data at enterprise scale. Teams use it to run pipelines, power analytics, and increasingly, to serve as the foundation for AI initiatives.
That last use case is where things get complicated.
As organizations move toward AI agents, natural language querying, graph-based retrieval, and digital twin modeling, Databricks is becoming the foundation these systems run on. The question is no longer whether you can run AI on your data. It’s whether the data carries enough meaning for that AI to work correctly.
That gap matters more than most organizations realize until they are already deep into an AI project.
The Problem with Tables and AI
In a typical Databricks environment, data is well-organized but not well-understood. Tables represent systems, not business concepts. Relationships between entities exist as JOIN logic written into queries, not as reusable definitions that carry meaning across the organization. Business rules are embedded in pipelines. Metrics are defined independently across notebooks, dashboards, and applications, sometimes consistently, often not.
For an analyst who knows the data well, this works. The knowledge lives in their head and in the SQL they write. For an AI system, it is a fundamental obstacle.
When a large language model or an AI agent attempts to interact with Databricks data directly, it has no access to that implicit knowledge. It sees column names and table schemas. It tries to guess relationships from naming conventions. It generates SQL that may execute without errors but does not reflect the intended business logic. The result is SQL that runs but doesn’t answer the question.
The problem is not Databricks. The problem is that the data layer alone does not carry enough meaning for AI to reason over reliably.
What AI Actually Requires
To answer even a straightforward question like “What is total revenue by customer segment this quarter?”, an AI system needs more than access to the right tables. It needs to know what revenue means in this organization, how customers relate to transactions, which joins are valid, which filters define a segment, and which metric definition is the authoritative one.
In most Databricks environments, all of that exists somewhere. It is in views, in pipeline code, in dashboard definitions, and in documentation that may or may not be updated. It is distributed, inconsistent, and entirely implicit. There is no single layer where business logic is formally defined and consistently available to every consumer, whether human or AI.
That is the gap. And it is not a gap that more data or faster processing closes. It is a semantic gap, and it requires a semantic solution.
What Databricks Already Offers, and Where the Gap Remains
Databricks has made major investments in agentic AI. Mosaic AI Agent Framework enables teams to build and deploy custom agents directly on the lakehouse. Agent Bricks handles orchestration, optimization, and evaluation. Genie Code turns natural language into pipelines, dashboards, and workflows. Together, these capabilities give organizations a powerful platform for building and scaling AI agents on top of Databricks.
The challenge is not what these tools do. It is what they work with.
Every agent, regardless of how advanced the orchestration, ultimately queries the underlying data. And that data is still stored as tables, with implicit relationships, scattered metric definitions, and business logic buried in pipelines or tribal knowledge.
When an agent is asked something like “revenue by customer segment this quarter,” it still has to interpret what “revenue” means, reconstruct which joins are valid, and decide which definition to use. There is no governed layer telling it the answer. It reasons from schema, not from meaning.
That is the gap. And it is not one that Databricks’ agentic tools, powerful as they are, are designed to fill.
The Semantic Layer Databricks Is Missing
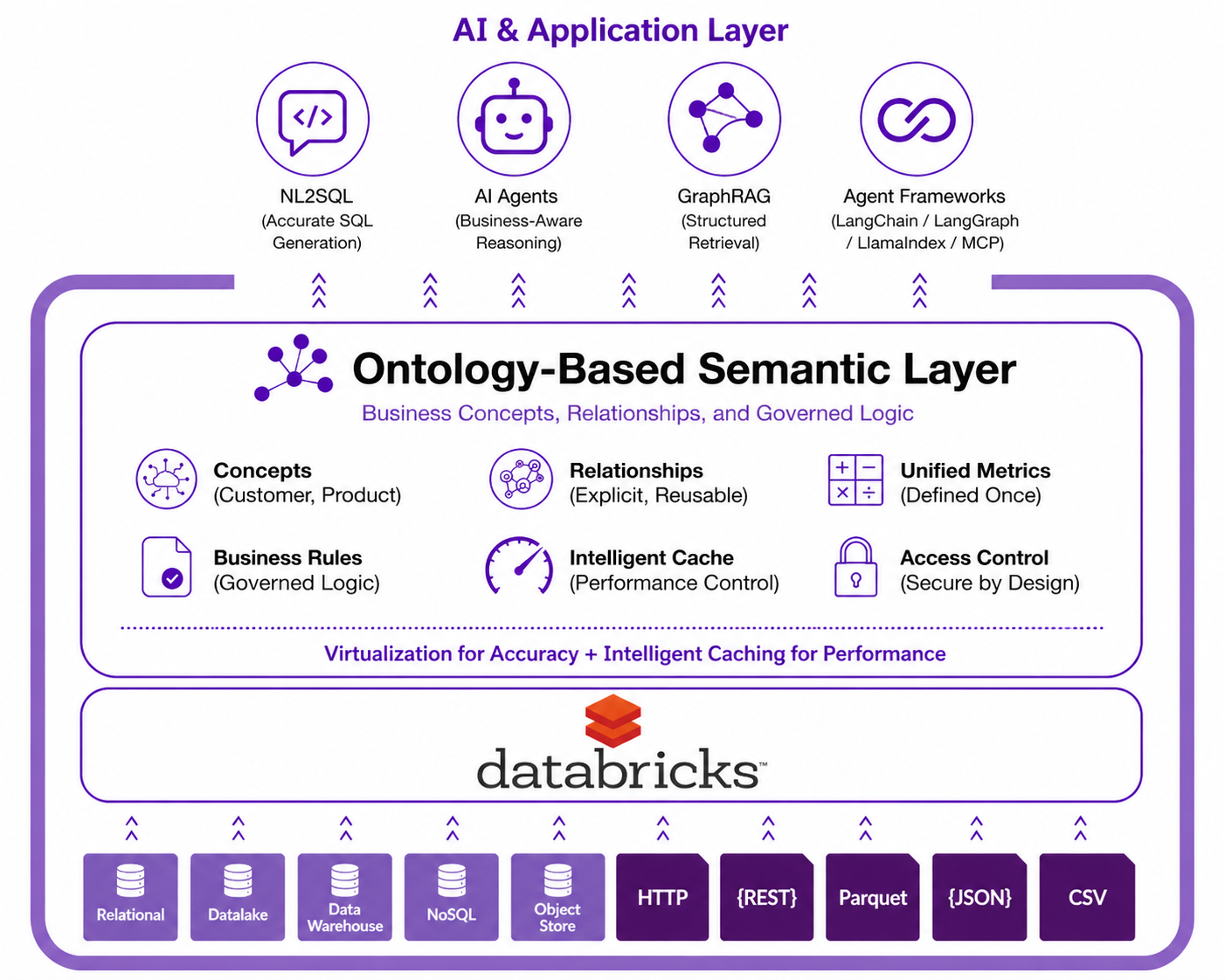
That semantic foundation is what Timbr provides, by embedding an ontology-based semantic layer directly into the Databricks Lakehouse. Rather than replacing Databricks or duplicating data, Timbr sits above the existing infrastructure, connecting to Unity Catalog, executing queries on Databricks clusters, and exposing a governed, queryable model of business concepts, relationships, and metrics. And critically, that model is not limited to the Lakehouse. Timbr connects across data sources, meaning organizations can incorporate and relate data from systems like SAP, Snowflake, or Oracle into the same semantic model, giving AI a unified view of the business rather than an isolated view of a single platform.
The shift this creates is significant. Instead of tables with implicit relationships, data engineers define explicit business concepts such as Customer, Product, Transaction, and Contract, and connect them through formal relationships that replace JOIN statements entirely. Instead of metrics scattered across notebooks, measures are defined once in the semantic model and inherited across concept hierarchies, ensuring consistency whether the data is being accessed from a Databricks notebook, a BI tool, or an AI interface.
Getting there does not require a manual migration. Timbr uses LLM-powered auto-mapping to scan existing Unity Catalog tables, generate ontology definitions, and establish data source connections automatically. What would otherwise be weeks of modeling work becomes a starting point that teams can refine rather than build from scratch.
Once the semantic model is in place, Timbr queries it through virtualization by default. This means data stays in its original location inside the Lakehouse, queries are executed live against Databricks clusters, and there is no risk of working from a stale copy. The semantic layer reflects the current state of the data at all times.
For workloads where live querying is not fast enough, Timbr also includes a four-tier caching engine that allows specific semantic views to be materialized, stored in memory, on SSD, in a data lake, or in a local database, depending on performance requirements. The important distinction is that this is not a forced trade-off. Teams are not required to choose between keeping data fresh and keeping queries fast. Virtualization handles accuracy. Materialization handles performance. Both operate within the same governed semantic model, and teams decide where each workload sits based on what it actually needs.
What This Enables for AI
A governed semantic layer makes the difference between AI use cases that work reliably and ones that don’t, and it directly affects the outcomes that matter most to enterprise data teams right now.
Natural language querying becomes reliable when AI systems have access to explicit business concepts and defined relationships. Instead of attempting to infer meaning from schema, a language model can query the semantic model with confidence that the concepts it references, such as revenue, customer, and segment, are consistently defined and correctly connected. Hallucinated joins and inconsistent metric calculations stop being an accepted risk. Timbr exposes the semantic model through standard interfaces, including LangChain, LangGraph, LlamaIndex, and MCP, allowing AI agents to interact with governed business data directly rather than working against raw tables and schema.
GraphRAG and graph-based retrieval benefit from the same foundation. When data is organized into a formal ontology with typed relationships and inherited properties, retrieval systems can navigate the knowledge graph with precision, following relationships rather than guessing connections. The structure that Timbr creates is not incidental to AI retrieval. It is the structure that makes retrieval meaningful.
Digital twin use cases, which require an accurate model of how real-world systems relate to one another, depend on exactly the kind of formal relationship modeling that an ontology-based semantic layer provides. Timbr allows organizations to model complex domains such as assets, processes, organizational structures, and supply chains as interconnected business concepts that mirror real-world relationships rather than database schemas.
LLM benchmarking gives organizations a way to validate how well their AI is actually performing. Timbr’s benchmarking framework allows teams to test different language models against their specific business ontology, comparing how accurately each one interprets enterprise logic, generates correct queries, and returns consistent answers. Instead of assuming an AI agent is working correctly, organizations can measure it against a defined semantic standard and make informed decisions about which models are fit for production use.
The common thread across all of these is simple. AI does not fail because of insufficient data. It fails because the data it has access to does not carry enough explicit meaning to reason over consistently. The semantic layer is what changes that.
Governance That Scales with the Model
One of the practical advantages of embedding the semantic layer within the Databricks ecosystem is that governance does not have to be rebuilt from scratch. Timbr integrates natively with Unity Catalog, exposing semantic concepts as Databricks catalogs and schemas, applying row-level security and permissions harmoniously with existing governance policies, and enabling SSO so that access controls remain aligned across both environments.
This matters for AI use cases in particular. As AI agents and automated systems gain access to enterprise data, the question of what they can access and under what conditions becomes critical. A semantic layer that enforces governance at the model level, rather than relying on downstream enforcement alone, provides a much stronger foundation for responsible AI deployment.
Conclusion
Databricks gives organizations a powerful platform for processing data, governing it, and increasingly, running AI on top of it. But running AI and running AI correctly are two different things. As AI becomes central to how enterprises operate, that distinction becomes the difference between an AI strategy that works and one that keeps falling short.
Timbr provides that meaning. By transforming Databricks tables into governed business concepts with explicit relationships and reusable logic, Timbr turns the Lakehouse into a system that AI can actually reason over, accurately, consistently, and at scale.
Want to see what this looks like in practice? Explore how Timbr integrates with the Databricks Lakehouse, how ontologies are surfaced through Unity Catalog, or the Databricks Semantic Layer use case.
