
Introduction
Data lakes provide organizations with a robust solution for storing vast volumes of structured, semi-structured, and unstructured data in a highly flexible and scalable environment. Technologies such as Apache Hadoop, Databricks, Azure Data Lake Storage Gen2, Amazon S3, and Google Cloud Storage are leading this revolution, offering cost-effective ways to manage diverse data types at scale.
Modern data lake architectures, such as the Lakehouse architecture, integrate open data formats like Delta Lake, Apache Parquet, and Apache Iceberg to deliver the reliability and performance of data warehouses while maintaining the scalability of data lakes. Metadata management tools, including Apache Hive Metastore, Databricks Unity Catalog, and Snowflake Polaris, offer a unified view of data assets, streamlining the management and governance of metadata across diverse data sources.
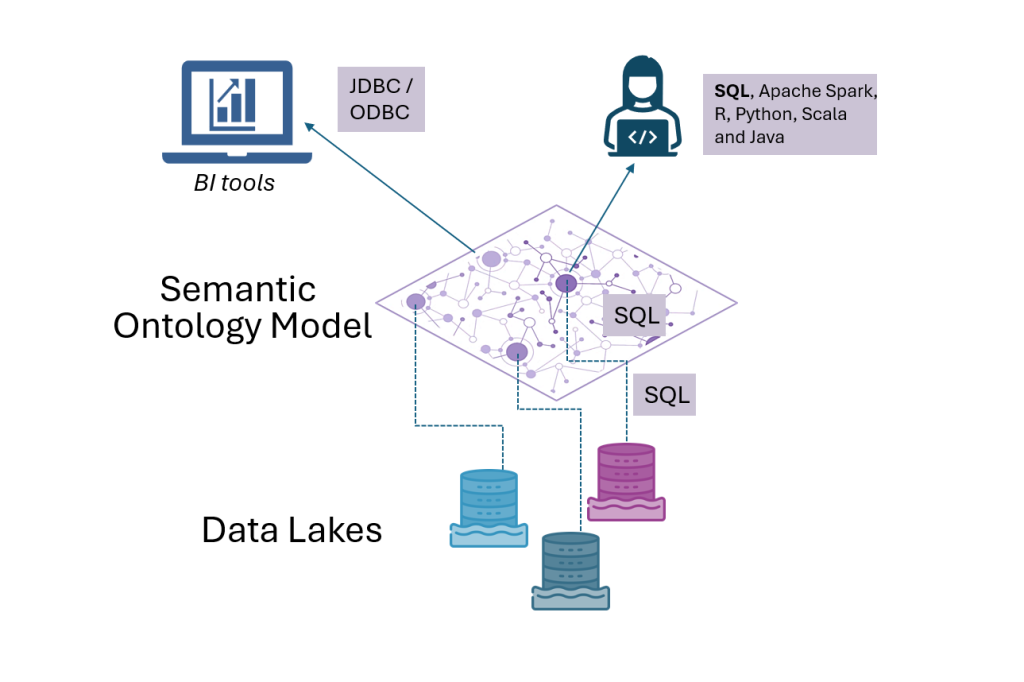
Despite these advancements, data lakes often lack the structured relationships required for meaningful analysis due to the variety of stored data. This is where Timbr’s SQL-based ontology semantic layer becomes crucial, introducing an intelligent framework that organizes and adds meaning to the data within data lakes, enabling more powerful and efficient querying.

The Challenge of Structure and Relationships in Data Lakes
While current metadata systems play a critical role in making data stored in these environments easier to find, they often lack the ability to manage, explore, and query data based on meaningful relationships. This limits discovery, complicates queries, and reduces the overall usability of the data.
They also come with several key challenges that knowledge graphs are well-suited to solve:
Poor Discoverability and Search: Data lakes can store enormous amounts of data, but finding the right data can be like searching for a needle in a haystack. Without clear relationships between different data elements, users struggle to discover relevant information quickly, slowing down decision-making and increasing frustration.
Complex and Inefficient Queries: When data lacks defined relationships, users often have to create complicated queries to connect different pieces of information. This makes data analysis slow and cumbersome, requiring significant effort to extract basic insights. Establishing clear relationships simplifies queries, making them faster and more direct, saving time and resources.
Risk of Data Swamps: Without proper management and organization, data lakes can turn into “data swamps”—disorganized collections where data is hard to understand or trust. When the connections and meanings of the data are unclear, it becomes less valuable and more challenging to use effectively. Managing relationships within the data helps maintain order and clarity, preventing the data lake from becoming chaotic and unusable.
Add rich context and interconnectedness to Datalakes:
Timbr ontology-based semantic layer seamlessly maps intricate relationships within your Datalake.
This integration enhances data understanding, breaks down silos, and facilitates comprehensive, insightful analytics. It enables intuitive data exploration and advanced query capabilities, making complex data relationships easily understandable and navigable.
Intelligent Semantic Modeling for Data Lakes
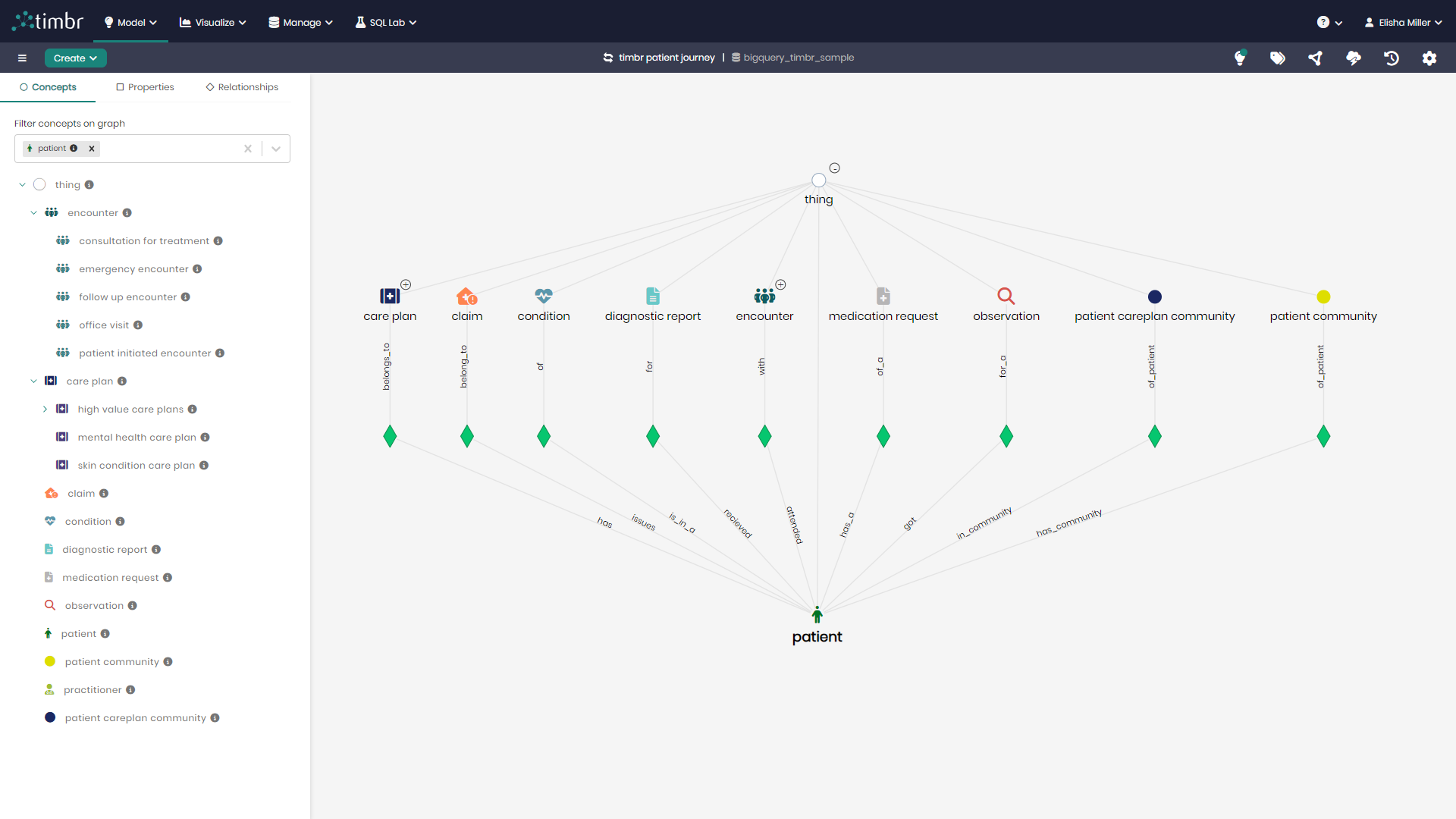
Ontology-based semantic technologies are particularly valuable in the context of data lakes. Here’s how:
Logical Data Modeling: Semantic ontologies allow organizations to create logical data models that represent the relationships between different entities in their data. This provides a coherent view of the data, even when the underlying physical storage doesn’t enforce these relationships.
Simplified Querying: By defining explicit relationships, SQL ontology models enable users to write simpler, more intuitive queries. In Timbr, we are the only ones who do this in standard SQL, translating high-level queries into complex joins and operations on the underlying data lake.
Data Discovery and Understanding: Explicit relationships make it easier for users to understand the context and connections within the data. This is crucial for data discovery and can significantly reduce the time spent on data exploration.
Flexibility with Structure: While data lakes are known for their flexibility, virtual SQL ontologies add a layer of structure without compromising the underlying flexibility of the data lake. This strikes a balance between the need for organization and the desire for adaptability.
Timbr Relationships in Action
To illustrate the power of Timbr’s explicit relationships, let’s consider the following business question based on the TPCH dataset stored in Databricks’ sample datasets:
“Find which supplier should be selected to place an order for a given part in a given region.”
In a traditional SQL environment, this query would involve multiple JOIN operations to relate the necessary tables from the TPCH benchmark, such as the supplier, parts, and region tables.
However, Timbr simplifies this process by using explicit relationships defined in the ontology, eliminating the need for complex joins (for an in-depth comparison of query complexity take a look at our TPCH benchmark).
The comparison below illustrates how the Timbr query leverages semantic relationships, while the TPC-H query requires multiple manual JOINs. This side-by-side comparison highlights how Timbr’s approach reduces complexity and streamlines querying.
With Timbr's Semantic Relationships
SELECT DISTINCT `supplier_account_balance`,
`supplier_name`,
`has_nation[nation].nation_name` AS nation_name,
`from_supplier[brass_product].part_key` AS part_key,
`from_supplier[brass_product].manufacturer` AS manufacturer,
`supplier_address`,
`supplier_phone`,
`supplier_comment`
FROM `dtimbr`.`european_supplier`
WHERE `from_supplier[brass_product].size` = 15
AND ps_supplycost = `from_supplier[brass_product].min_supplycost_europe`
ORDER BY `supplier_account_balance` DESC, `nation_name`, `supplier_name`, `part_key`
Without Timbr's Semantic Relationships
SELECT s_acctbal,
s_name,
n_name,
p_partkey,
p_mfgr,
s_address,
s_phone,
s_comment
FROM tpc.part
INNER JOIN tpc.partsupp ON p_partkey = ps_partkey
INNER JOIN tpc.supplier ON s_suppkey = ps_suppkey
INNER JOIN tpc.nation ON s_nationkey = n_nationkey
INNER JOIN tpc.region ON n_regionkey = r_regionkey
WHERE p_size = 15
AND p_type like '%BRASS'
AND r_name = 'EUROPE'
AND ps_supplycost = (
SELECT min(ps_supplycost)
FROM tpc.partsupp
INNER JOIN tpc.supplier ON s_suppkey = ps_suppkey
INNER JOIN tpc.nation ON s_nationkey = n_nationkey
INNER JOIN tpc.region ON n_regionkey = r_regionkey
WHERE p_partkey = ps_partkey
AND r_name = 'EUROPE'
)
ORDER BY s_acctbal DESC, n_name, s_name, p_partkey
Timbr’s runtime engine automatically translates queries into the necessary SQL commands, including the required JOINs:
In our example, Timbr eliminated the need for manual JOINs by using relationships such as from_supplier and has_nation. This significantly simplifies the user query process and reduces the potential for errors, especially in complex queries involving multiple datasets.
How Timbr Unlocks the Full Potential of Data Lakes
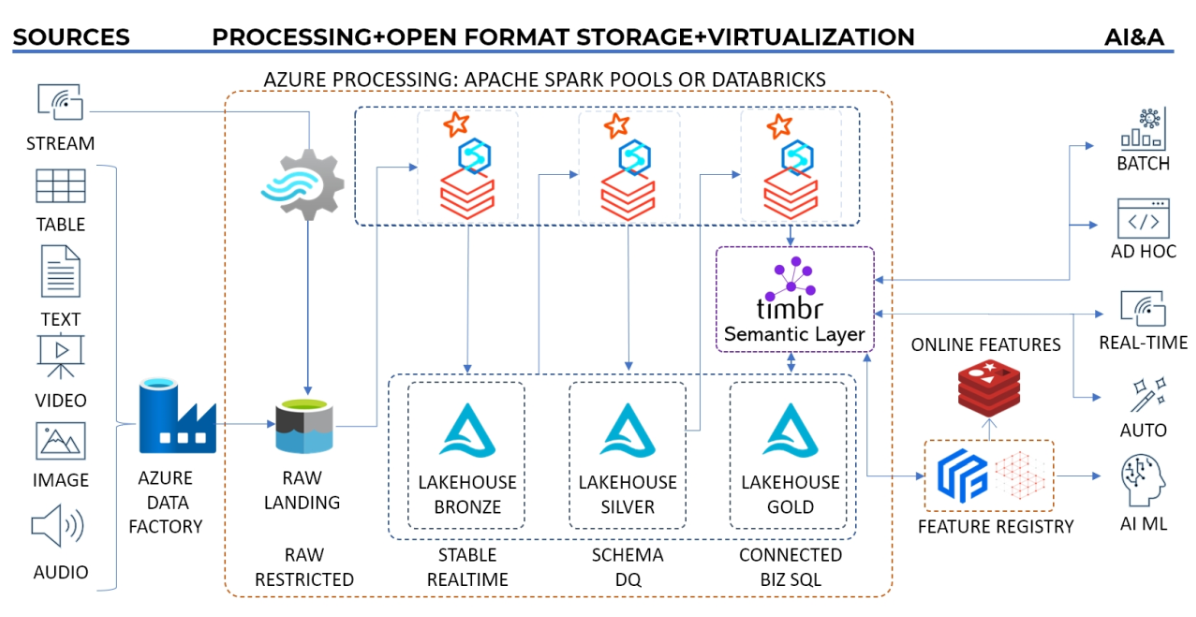
- Enhanced Data Discovery and Searchability: SQL ontologies improve the ability to search and discover relevant data by leveraging explicit relationships, making it easier for users to locate what they need within large datasets.
- Improved Data Context and Meaning: By providing a rich semantic layer, semantic ontologies add context and meaning to the data, helping users better understand how different data points are related.
- Unified View of Disparate Data Sources: Integrating data from various structured and unstructured sources offers a unified view of the entire data landscape.
- Facilitates Advanced Analytics and AI: The semantic relationships enable more advanced data analytics and AI applications by simplifying complex queries and providing more meaningful insights.
- Enhanced Data Governance and Compliance: With clear relationships and data lineage, knowledge graphs support better governance and compliance by providing visibility into how data flows and is used across the organization.
Conclusion
Timbr’s innovative approach to adding explicit relationships to data lakes represents a significant leap forward in making these vast data repositories more manageable and valuable. By providing a semantic layer that bridges the gap between the flexibility of data lakes and the structure needed for effective data analysis, Timbr empowers organizations to derive more value from their data assets.
How do you make your data smart?
Timbr virtually transforms existing databases into semantic SQL knowledge graphs with inference and graph capabilities, so data consumers can deliver fast answers and unique insights with minimal effort.
