
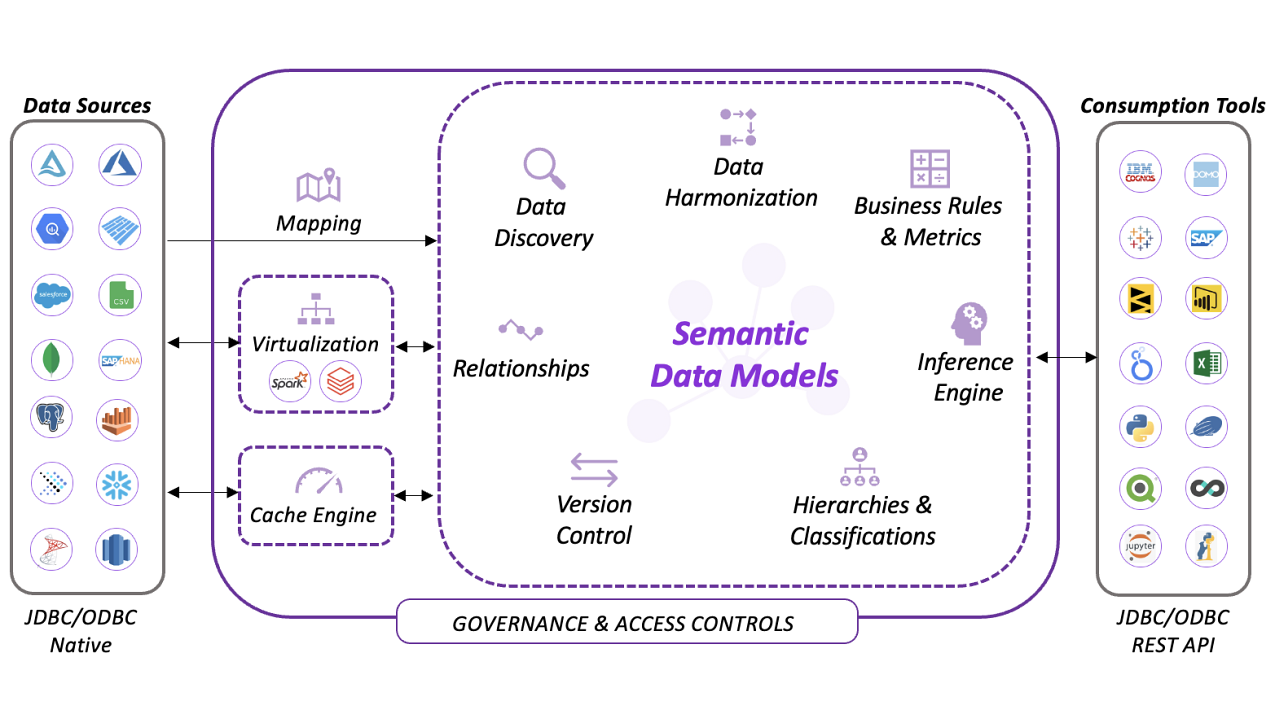
Data mesh is an innovative data architecture that challenges traditional centralized approaches, like data warehouses and data lakes, by decentralizing data ownership and management. This approach is particularly useful for large organizations that struggle with scalability, data bottlenecks, and the need for real-time data access.
To successfully implement a data mesh architecture, organizations need robust tools that not only facilitate decentralized data management but also provide comprehensive governance capabilities.
Timbr’s SQL-based knowledge graph technology provides an ideal foundation for implementing data mesh architectures. It combines the flexibility of an intelligent semantic layer with advanced governance features and the newly added capability to manage data products by domain.
In this blog post, we’ll delve into how Timbr delivers a data mesh implementations through its governance capabilities, easy compartmentalization, and powerful querying features.
What is Data Mesh?
At its core, data mesh is designed to address several key challenges inherent in traditional centralized data architectures:
1. Scalability: Centralized systems often struggle to scale effectively, leading to bottlenecks and delays. By decentralizing data ownership, data mesh allows each domain to manage its data independently, making it easier to scale as the organization grows.
2. Data Accessibility and Usability: In centralized architectures, accessing and using data often involves complex ETL (Extract, Transform, Load) processes that can delay data availability. Data mesh, on the other hand, maintains data in its original form and allows domain-specific teams to apply transformations as needed. This approach makes data more accessible and usable in real-time, reducing the need for specialized data engineers to manage complex data pipelines.
3. Ownership and Quality Control: One of the significant issues with centralized data systems is the lack of clear ownership and responsibility for data quality. In a data mesh, each domain is responsible for its own data, ensuring that those who understand the data best are also responsible for its quality. This model enhances data quality and ensures that data is more relevant and accurate.
4. Flexibility and Agility: Traditional data architectures can be rigid, making it difficult to respond to changing business needs. Data mesh’s decentralized approach provides the flexibility needed to adapt quickly to new requirements, whether it’s integrating new data sources or adjusting data governance policies.
Implementing Data Mesh with Timbr
Data mesh architecture is centered around four fundamental principles: domain-oriented decentralized data ownership, data as a product, self-serve data infrastructure, and federated computational governance. Timbr addresses each of these principles effectively:
1. Domain-Oriented Decentralized Data Ownership
Timbr allows different domains within an organization to create and manage their own ontologies (each ontology is equivalent to a data product), which are essentially domain-specific data models. By enabling each domain to define, integrate, govern, and control its own data products, Timbr ensures that data ownership is truly decentralized and can be managed at the domain level or data product level (ontology). This aligns with the data mesh principle that advocates for data being managed by the teams closest to it, who understand its context and usage best.
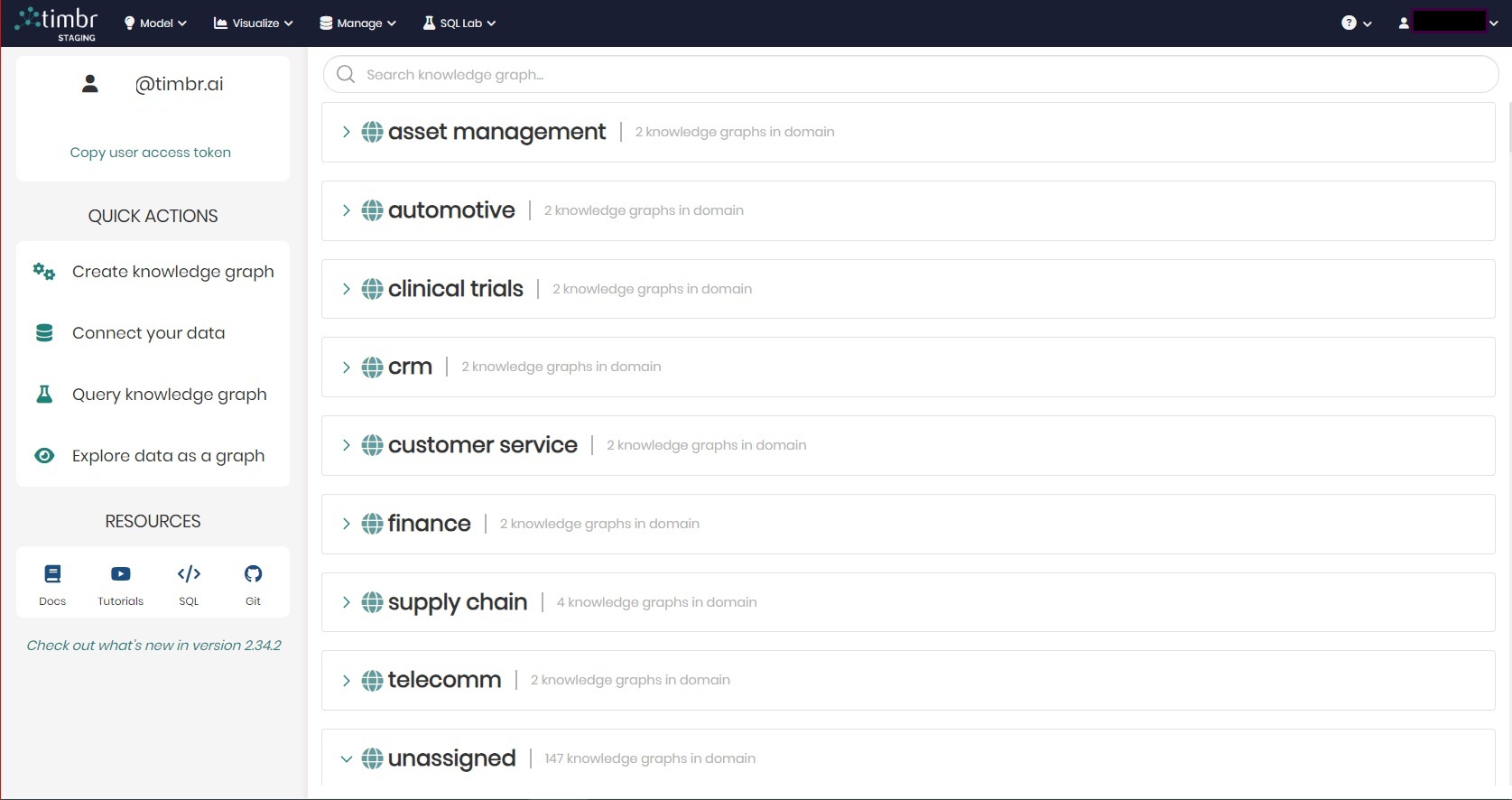
2. Data as a Product
Timbr facilitates treatment of data as a product by enabling the creation of domain-categorized ontologies that are tailored to specific business needs. Each ontology in Timbr can be enriched with metadata, business logic, and governance rules, making the data not only accessible but also meaningful and valuable to other parts of the organization. By structuring data in this way, Timbr ensures that data is treated as a product that is curated, maintained, version-controlled and optimized for consumption.
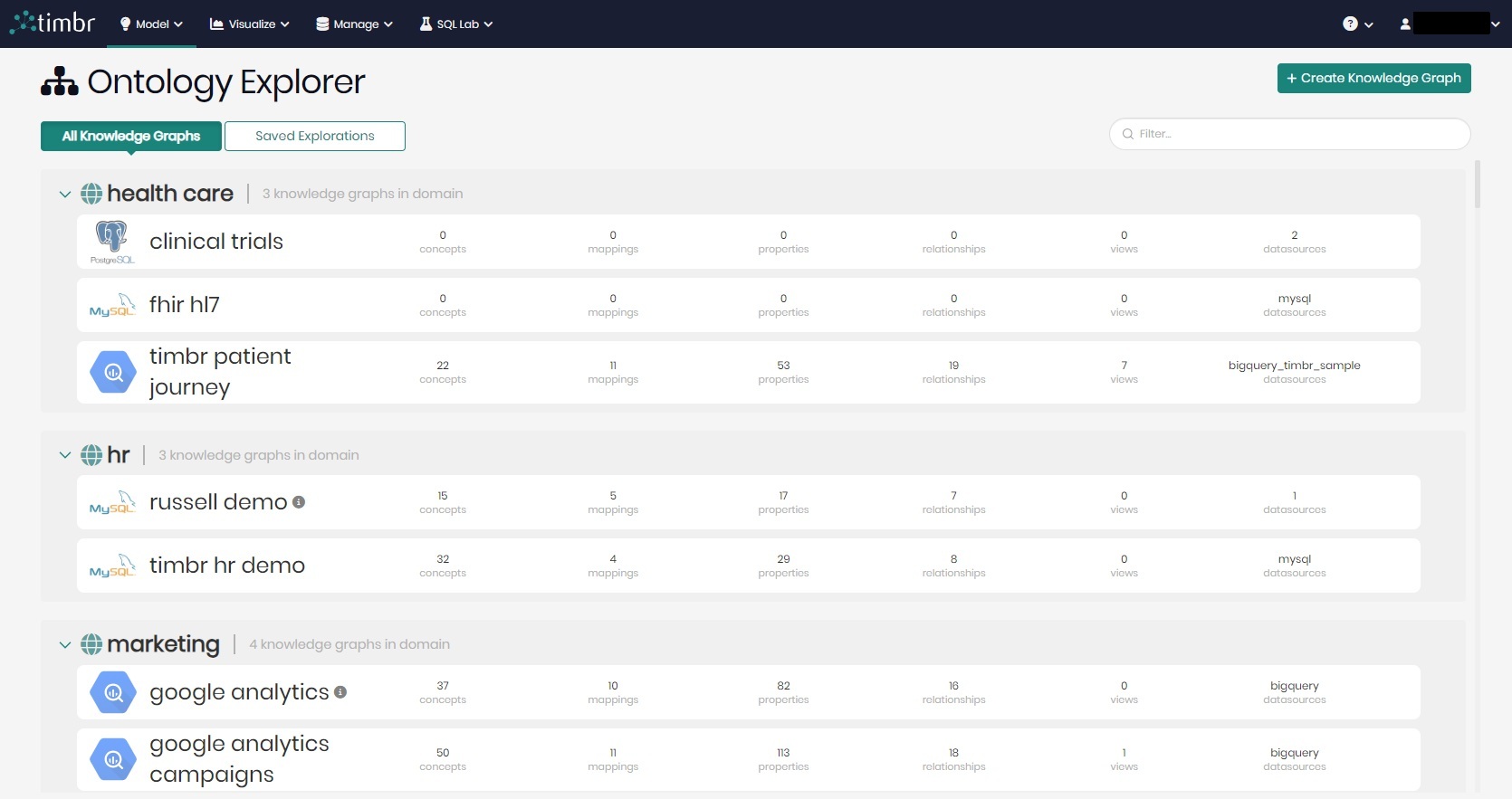
3. Self-Serve Data Infrastructure
Timbr provides a self-serve data infrastructure that enables data democratization by defining a semantic data model for every business domain and additionally allow integration of multiple data sources using Timbr’s virtualization engine.
By leveraging the power of relationships in SQL, Timbr reduces query complexity and size by eliminating the need for JOIN and UNION statements. This feature allows domain teams to independently manage and query their data within and across domains without relying on a central data team. The self-serve model in Timbr is further supported by its user-friendly interface and integration with existing SQL-based systems, enabling teams to easily interact with and manipulate their data products and expose them to data analysts, data scientists and web-app developers.
SQL Queries Across Domains – Example
This example uses two domain ontologies: Automotive and Supply Chain whose model is shown here:
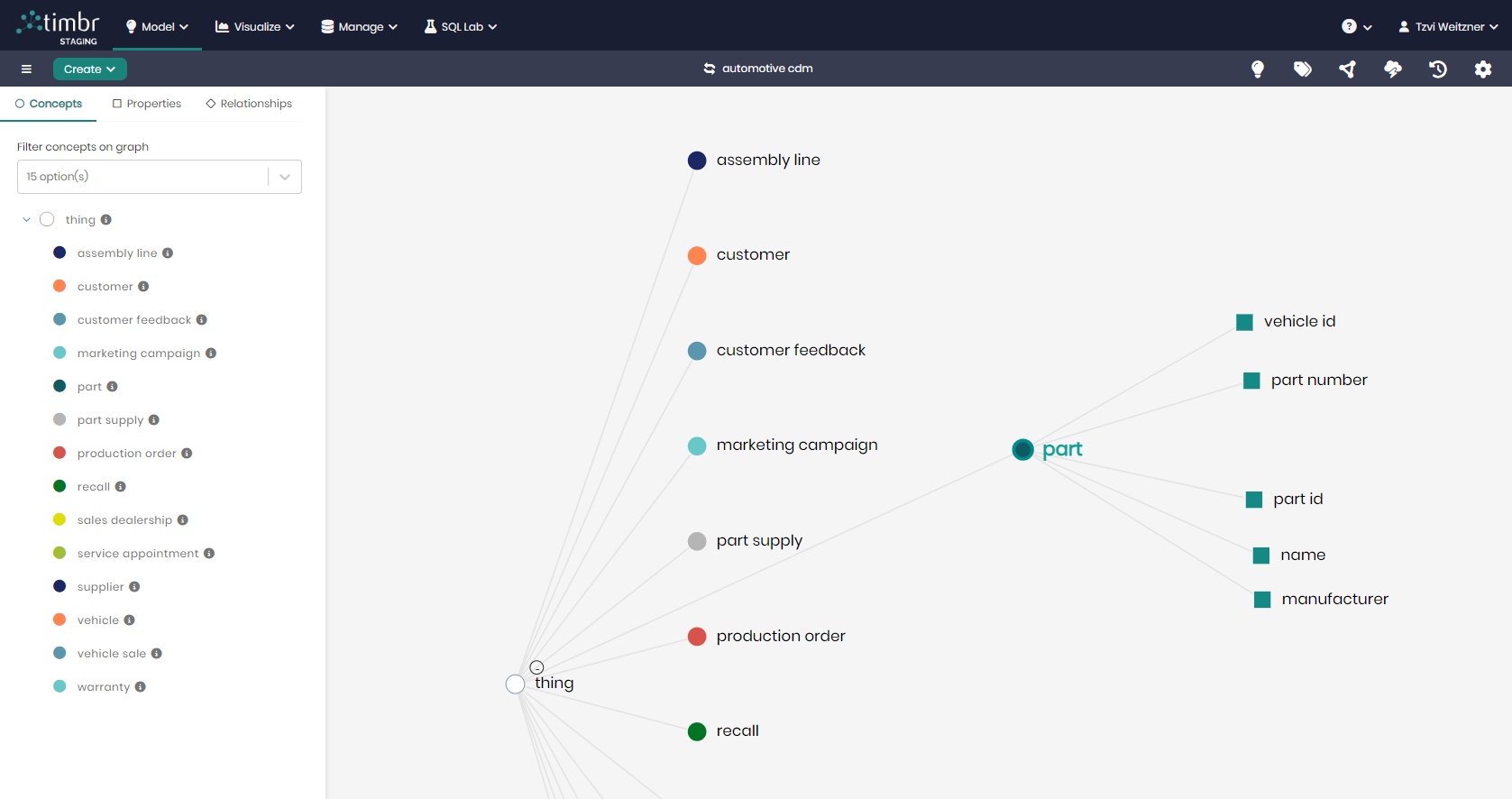
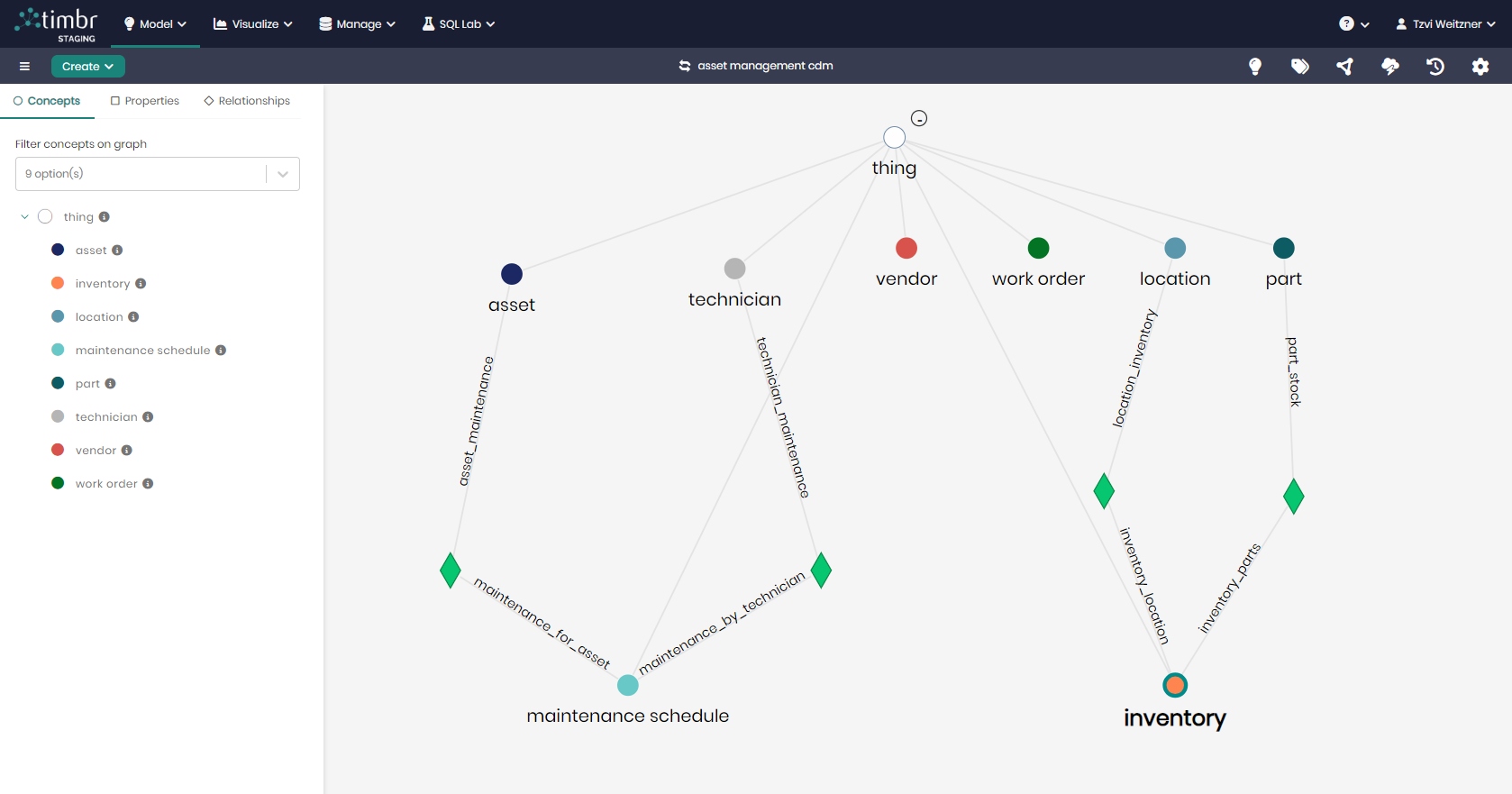
These domain-oriented ontologies share one common concept: Part
We show below the types of queries that Timbr enables for these ontologies.
Query from automotive domain to get all part ids:
SELECT part_id from automotive_cdm .timbr.part
Query from the asset management domain to count the number of all parts per inventory:
SELECT inventory_name, count(part_id) as number_of_parts
FROM asset_management_cdm.dtimbr.`inventory`
GROUP BY inventory_name
Query that combines both asset management domain and automotive domain to count all car parts per inventory:
SELECT inventory_name, count(1) as number_of_car_part
FROM asset_management_cdm.dtimbr.`inventory`
WHERE `inventory_parts[part].part_id` IN (SELECT part_id FROM automotive_cdm.timbr.part)
GROUP BY inventory_name
4. Federated Computational Governance
Timbr supports federated governance by allowing each domain to enforce its own governance policies while ensuring adherence to organization-wide standards. This is achieved through features like row-level security, compartmentalized access control, and detailed user rights management. Timbr’s knowledge graph technology also includes tools for tracking data lineage and ensuring compliance, which are crucial for maintaining governance across a decentralized architecture.
Summary
Data mesh represents a significant evolution in data architecture, offering a scalable, flexible, and agile approach to managing large, complex data environments. Timbr enables organizations to effectively implement a data mesh architecture. It allows for the decentralization of data ownership, ensures data is treated as a product, provides a robust self-serve infrastructure, and supports federated governance, all while leveraging the power of SQL ontologies and relationships.
This makes Timbr a powerful tool for organizations looking to adopt a data mesh approach and overcome the limitations of traditional centralized data architectures.
How do you make your data smart?
Timbr virtually transforms existing databases into semantic SQL knowledge graphs with inference and graph capabilities, so data consumers can deliver fast answers and unique insights with minimum effort.
