

Introduction
The race to give AI agents a governed understanding of enterprise data has intensified dramatically in early 2026. Snowflake shipped Semantic View Autopilot. Databricks took Unity Catalog Business Semantics to general availability and open-sourced it. Microsoft unveiled Fabric IQ Ontology with MCP endpoints. Google announced Looker BI Agents grounded in a Knowledge Catalog semantic graph. Collibra launched AI-powered Semantic Agents that auto-generate models from glossaries and metadata.
The message from every major platform vendor is now the same: AI agents cannot operate reliably on raw schemas, and the manual process of building the semantic foundation has been the bottleneck. Automate it.
That message is correct. But the way most vendors are automating it reveals a deeper architectural gap that none of them are well-positioned to close on their own — and it is exactly the gap Timbr was built to fill.
What Each Vendor Is Actually Automating
It is worth being precise about what has shipped, because the differences matter more than the marketing suggests.
Snowflake’s Semantic View Autopilot (GA, February 2026) mines query logs, Tableau workbooks, and historical SQL patterns to propose canonical metric definitions. It uses clustering algorithms to find consensus business logic — if hundreds of queries define “active user” the same way, SVA proposes that as the standard. The result is a governed semantic view that powers Cortex Analyst and Cortex Agents. This is metric-governance automation: fast, practical, and tightly scoped to the Snowflake ecosystem.
Databricks Unity Catalog Business Semantics (GA, April 2026) moves metric definitions from the BI layer to the data layer itself. Metrics, dimensions, and context metadata become first-class catalog assets, addressable via SQL and consumable by Genie, AI/BI Dashboards, notebooks, and agents. Databricks also uses AI to bootstrap semantic definitions from existing catalog objects. Agent Bricks, their governed agent platform, leverages this metadata to achieve what Databricks reports as 70% higher accuracy than standard RAG. The core implementation is being open-sourced in Apache Spark — a significant interoperability signal.
Microsoft Fabric IQ Ontology (Preview, expanded at FabCon Atlanta 2026) is the most architecturally ambitious of the platform-native offerings. It goes beyond metrics into a full ontology: business entities, relationships, properties, rules, and actions, connected to analytical, operational, time-series, and geospatial data. Ontologies can be auto-generated from existing Power BI semantic models. At FabCon, Microsoft announced that Fabric IQ Ontology will be accessible through public MCP endpoints, enabling agents beyond the Microsoft ecosystem to ground reasoning in a shared semantic layer.
Google’s Looker BI Agents (announced at Next ’26) trigger downstream business actions grounded in LookML’s semantic layer. A native managed MCP server exposes LookML definitions to external agents. Gemini-powered generation automates semantic model creation from natural language descriptions, SQL queries, and database schemas. Knowledge Catalog integration transforms Looker metadata into a semantic graph for autonomous agent operation.
Collibra’s Semantic Agents (launched late 2025, expanding in 2026) take a governance-first approach: the Semantic Model Generation Agent reads existing business glossaries, metric catalogs, and physical metadata to auto-generate business-ready semantic models. The Semantic Mapping Agent uses ML to link physical data assets to those definitions programmatically, replacing the manual curation bottleneck.
Atlan’s Context Engineering Studio bootstraps semantic models from existing dashboards, query logs, and catalog metadata, then runs an evaluation suite against real business questions before deployment. Atlan draws an explicit distinction between the “semantic layer” (metric definitions) and the “context layer” (governance, lineage, quality signals, and usage patterns wrapped around those definitions), exposing both to agents via an MCP server.
These are serious, well-resourced efforts. None of them are toys. And each addresses a real piece of the problem.
But look at what they have in common and what falls through the gaps.
Three Camps, One Structural Gap
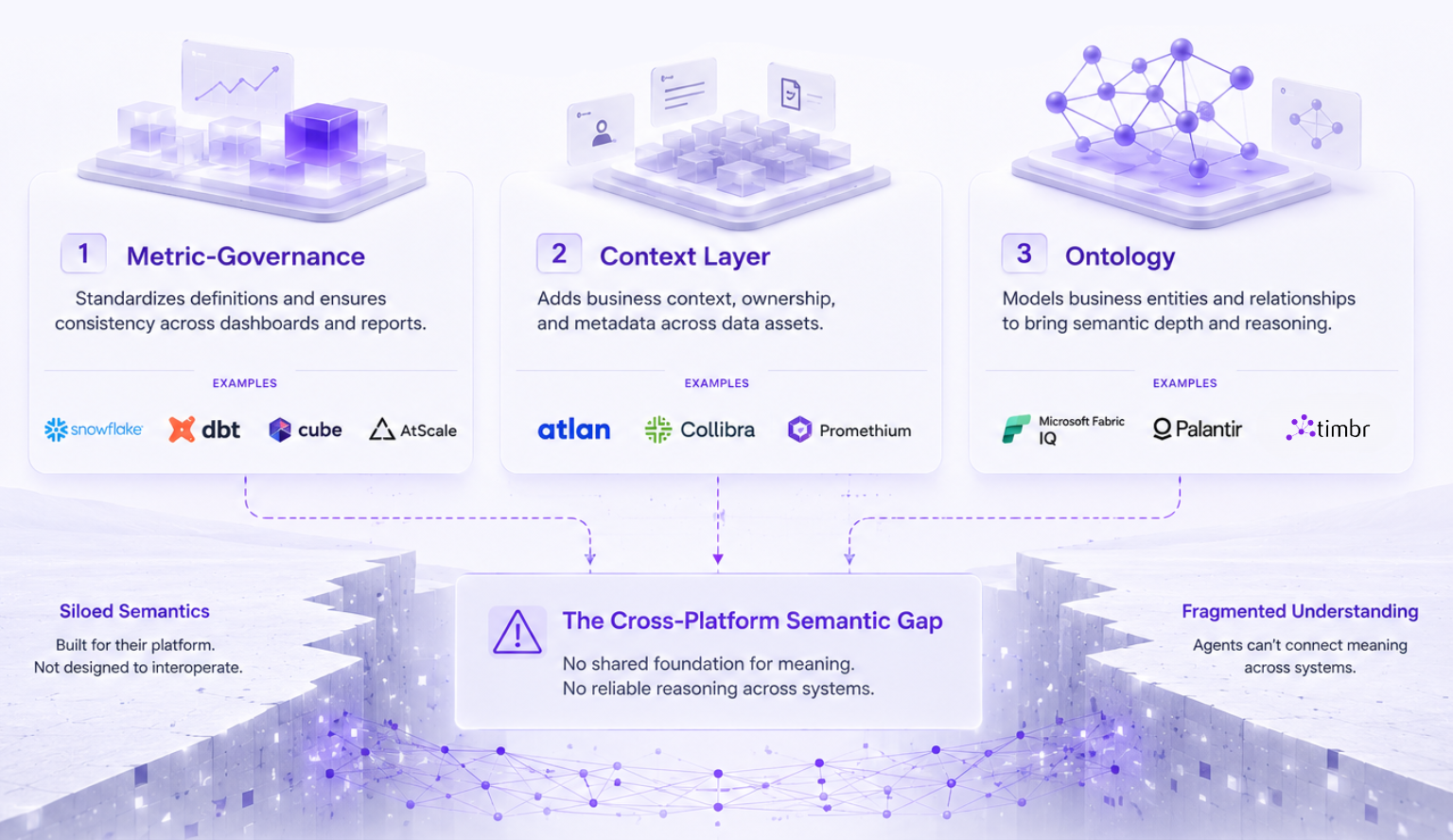
The market is splitting into three architectural camps, each automating a different layer of the semantic foundation:
The metric-governance camp – Snowflake, dbt (MetricFlow + MCP server), Cube (AI API + MCP), AtScale – focuses on ensuring every tool and agent uses the same definitions for revenue, churn, and every other business KPI. Define once, query everywhere. This is where most of the automation innovation has concentrated, and for good reason: inconsistent metric definitions are the single most common source of broken trust in analytics.
The context-layer camp – Atlan, Promethium, and to some extent Collibra – wraps governance metadata, lineage, quality signals, and usage patterns around whatever semantic definitions already exist, then exposes that enriched context to agents via MCP. The semantic layer tells you what “revenue” means. The context layer tells you who owns that definition, when it was last validated, what downstream dashboards depend on it, and whether the underlying data passed quality checks this morning.
The ontology camp – Palantir Foundry, Microsoft Fabric IQ, and Timbr – models not just metrics but the full semantic structure of the business: entities, relationships, hierarchies, rules, constraints, and actions. An ontology does not just tell an agent how to calculate revenue. It tells the agent that a Customer is a type of Account, that an Order has a relationship to a Product through a LineItem, that the relationship between a Supplier and a Factory is governed by a specific contract structure. This is the level of semantic reasoning that separates an agent that retrieves correct numbers from an agent that understands the business.
Each camp solves a real problem. But there is a structural gap that cuts across all three:
Almost every one of these approaches is locked to a single platform.
Snowflake’s semantic views live in Snowflake. Databricks’ Business Semantics are Unity Catalog objects. Fabric IQ Ontology is a Fabric item. Looker’s LookML is resolved within Looker’s runtime. Palantir’s Ontology is deeply embedded in Foundry.
For an enterprise with data in SAP, Snowflake, Databricks, Oracle, and PostgreSQL, which describes most large enterprises, no single-platform semantic layer provides a unified view. The agent that queries Snowflake gets one set of governed definitions. The agent that queries SAP gets whatever it can infer from a raw schema. The semantic foundation is fragmented at the platform boundary.
The Open Semantic Interchange (OSI) specification, published in January 2026 with 50+ partners, is an important step toward semantic portability. But OSI standardizes how definitions are exchanged between tools. It does not create a live, queryable semantic layer that spans multiple data platforms at runtime.
That is the gap Timbr is specifically designed to close.
How Timbr Closes the Cross-Platform Gap
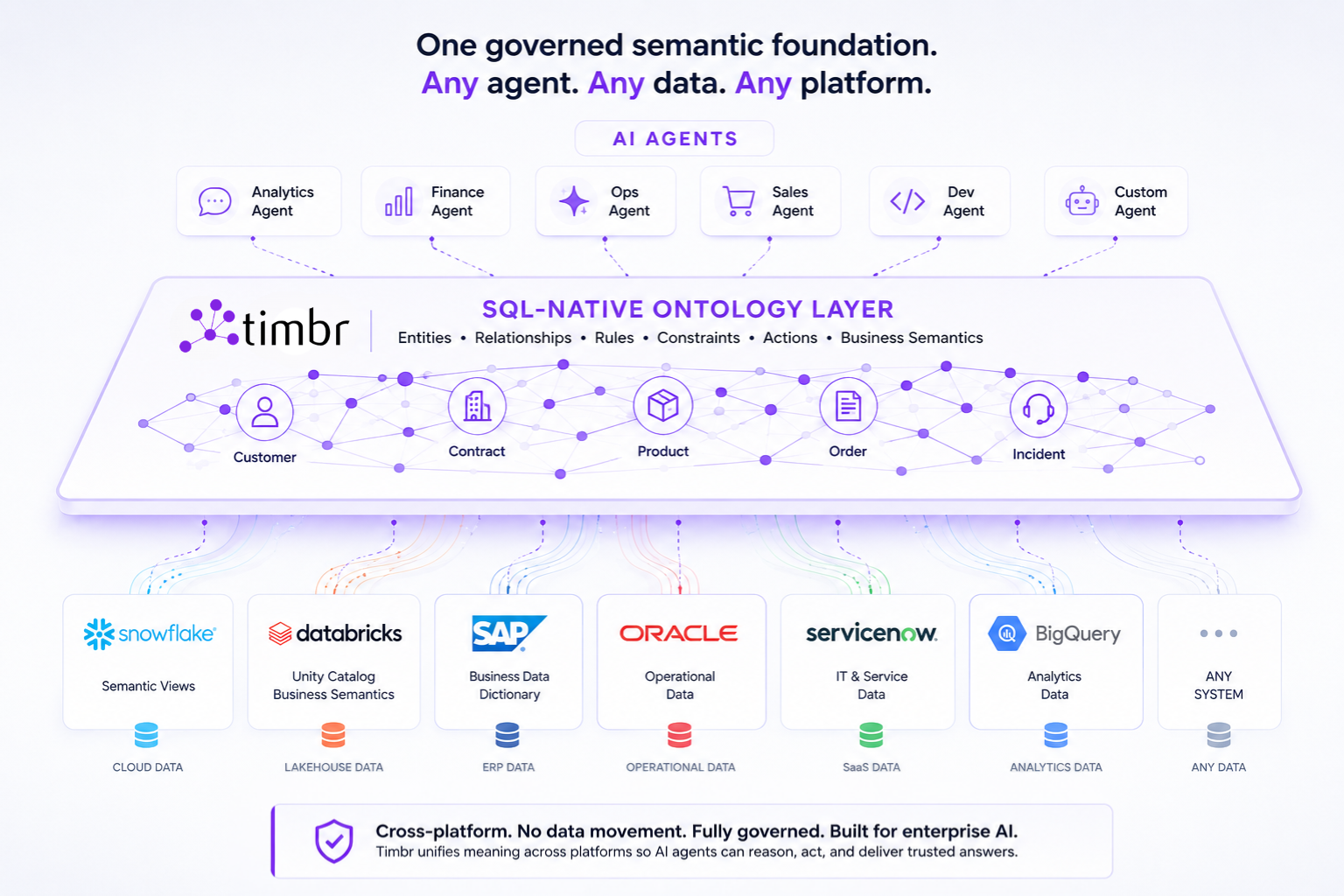
Timbr approaches the problem from a fundamentally different starting point than the platform vendors. Rather than building semantics into a single data platform’s catalog, Timbr provides an ontology-based semantic layer that sits above the data infrastructure and connects to data sources across platforms – Databricks, Snowflake, SAP, Oracle, PostgreSQL, SQL Server, Google BigQuery, and others.
The result is a unified graph of business concepts, relationships, hierarchies, and measures that spans the entire data estate. A Customer is defined once. The relationship between Product and Order is defined once. Revenue is calculated once. Every agent that operates within this environment, regardless of which LLM powers it, which BI tool consumes it, or which data platform stores the underlying data, works from the same governed definitions.
Ontological Reasoning, Not Just Metric Governance
Timbr’s ontology defines concept hierarchies using formal class inheritance. A VIP Customer is a Customer is an Account. Properties and measures defined at any level of the hierarchy are inherited by all descendant concepts. When an agent queries “total revenue for VIP Customers,” it does not need to know the filter logic that distinguishes a VIP Customer from a regular Customer – that logic is embedded in the ontology’s concept definition and applied automatically.
Relationships between concepts are first-class objects in the ontology, not implicit JOIN paths inferred from foreign keys. The relationship between an Order and a Product passes through a LineItem. The relationship between a Patient and a Diagnosis passes through an Encounter. These are not schema conventions an agent must guess at. They are explicit, governed definitions that the agent navigates directly.
This is the same architectural principle behind Palantir’s Foundry Ontology and Microsoft’s Fabric IQ. The critical difference: Palantir’s Ontology is locked inside Foundry. Fabric IQ’s Ontology is a Fabric item. Timbr’s ontology connects to data wherever it lives, without requiring that data to move into a single platform.
Cross-Platform Data Virtualization
Timbr queries data where it lives. There is no data movement, no replication, no ETL into a separate semantic store. Queries execute on the native compute engine of each data platform – SQL pushdown to Snowflake’s warehouse, Databricks’ clusters, SAP HANA, Oracle, or any other connected source.
The semantic layer reflects the current state of the data at all times. An agent can join a concept modeled from SAP data with a concept modeled from Snowflake data through the ontology’s relationship graph, without either system knowing about the other. The cross-platform join is resolved at the semantic layer through virtualization, with query execution pushed down to each source.
This means organizations do not need to consolidate data into a single platform before they can build a unified semantic foundation for AI agents. The ontology unifies meaning. The data stays where it is.
LLM-Powered Auto-Mapping: Automating the Ontology Itself
The automation challenge that Snowflake addresses with Semantic View Autopilot and Collibra addresses with its Semantic Agents, eliminating the manual bottleneck of semantic model creation, is equally critical for ontology-based approaches.
Timbr uses LLM-powered auto-mapping to scan existing catalog structures, including Unity Catalog, Snowflake’s Information Schema, and other metadata sources, and automatically generate ontology definitions: concept types, properties, relationships, and data source connections. What would otherwise be weeks of manual modeling becomes a starting point that domain experts refine rather than build from scratch.
The auto-mapping process works in three stages:
- Schema discovery and classification. Timbr scans the connected data sources, reads table and column metadata, and uses LLM reasoning to classify tables into candidate business concepts (e.g., a table with customer_id, name, email, and signup_date is classified as a “Customer” concept candidate).
- Relationship inference. Foreign key relationships, naming patterns, and structural similarities are analyzed to propose formal ontology relationships between concepts. The LLM distinguishes between structural relationships that reflect genuine business meaning and incidental schema patterns that do not.
- Hierarchy and measure generation. Based on column types, naming conventions, and existing documentation, the auto-mapper proposes concept hierarchies (e.g., VIP Customer as a subclass of Customer) and measure definitions (e.g., identifying amount columns as candidates for revenue measures with appropriate aggregation logic).
The output is a draft ontology that teams can review, adjust, and govern, not a black-box model that is difficult to inspect or modify. Every auto-generated definition is visible, editable, and subject to the same governance controls as manually created definitions.
Integration with Existing Platform Semantics
Timbr does not require organizations to abandon the semantic investments they have already made. It integrates natively with Unity Catalog, exposing semantic concepts as Databricks catalogs and schemas. Governance policies, row-level security, column masking, and SSO are applied harmoniously with existing platform-level controls.
For organizations that have already built metric definitions in dbt, Snowflake Semantic Views, or Power BI models, Timbr’s ontology sits above these definitions as a cross-platform unification layer. The platform-native semantics remain the source of truth within their respective ecosystems. Timbr adds the cross-platform relationships, concept hierarchies, and ontological reasoning that no single platform can provide on its own.
MCP, OSI, and the Agent Interface Layer
Two infrastructure developments are reshaping how semantic layers connect to AI agents, and both matter for evaluating any vendor’s approach.
Model Context Protocol (MCP) has become the de facto standard for how agents consume semantic context. Looker, dbt, Cube, AtScale, Atlan, and Microsoft Fabric have all announced or shipped MCP servers. Any semantic layer that does not expose its definitions through MCP is increasingly invisible to the growing ecosystem of MCP-compatible agents, including Claude, Cursor, Copilot Studio, and enterprise agent frameworks built on LangChain and similar tooling.
Open Semantic Interchange (OSI) standardizes how semantic definitions are represented and exchanged across tools, using a vendor-neutral YAML-based specification. The v1.0 spec was published in January 2026 with 50+ partners including Snowflake, Databricks, dbt Labs, Salesforce, JPMC, and AWS. OSI solves the portability problem: definitions can travel between tools. It does not solve the unification problem: making those definitions queryable as a single model across platforms.
For organizations evaluating their semantic architecture, the practical question is: does your semantic foundation serve definitions to agents (via MCP), ensure those definitions are portable (via OSI), and provide them as a unified model across your actual data landscape (via cross-platform virtualization)? Most current solutions address one or two of these requirements. Very few address all three.
Observability: Knowing What the Agent Knew
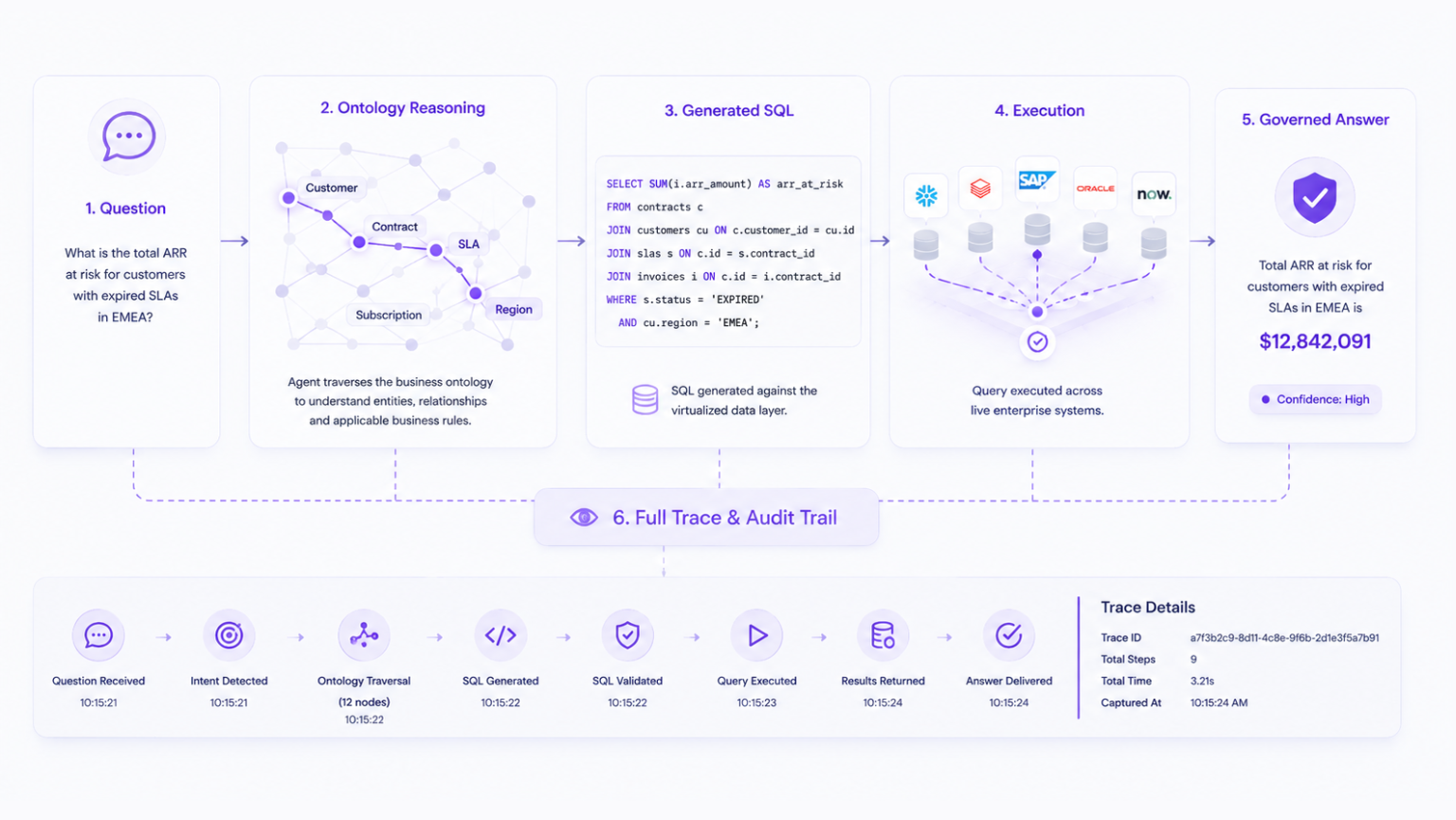
One dimension of the semantic foundation that is often overlooked in the automation conversation is observability, not just whether the agent returned a correct answer, but whether you can determine why it returned that answer.
Every Timbr Data Agent interaction is logged at the execution level: the reasoning path the agent followed through the ontology, the SQL it generated, the data it returned, the token cost at each step, and whether any retries occurred. Every conversation can be inspected. Every chain trace can be drilled into. The exact prompt constructed from the ontology context is visible and auditable.
This is not a debugging convenience. It is what makes it possible to run agents in production with confidence rather than hope. When a result is questioned, you can trace exactly where the reasoning went. When something is working well, you can understand why and replicate it across other domains.
An agent you cannot audit is an agent you cannot trust. An agent grounded in an ontology you can inspect is an agent whose reasoning you can verify.
The Question Worth Asking Before You Build
The next time a vendor presents a data agent demo or an automated semantic layer generator, the question worth asking is not how impressive the automation is. It is what the resulting semantic foundation actually covers.
Does it span the data platforms your enterprise actually uses, or only the vendor’s own ecosystem? Does it model business entities and relationships, or only metric definitions? Can agents outside the vendor’s own tooling consume it through standard protocols? Does it give you ontological reasoning, concept hierarchies, inherited properties, formal relationships, or just consistent metric definitions? And can you inspect exactly what the agent knew, and what it inferred, when it generated a specific answer?
The hardest problem in data agents has never been orchestration, retrieval, or natural language translation in isolation. It is giving AI systems a reliable, governed, cross-platform understanding of what enterprise data actually means at the level of business concepts rather than table schemas, consistently across every platform where enterprise data lives.
The vendors automating metric governance are solving a necessary problem. The vendors building ontologies are solving a deeper one. Timbr solves both across all platforms where enterprise data actually lives.
See It in Practice
Explore how Timbr’s ontology-based semantic layer gives data agents a governed understanding of your business across Databricks, Snowflake, SAP, and beyond.
