
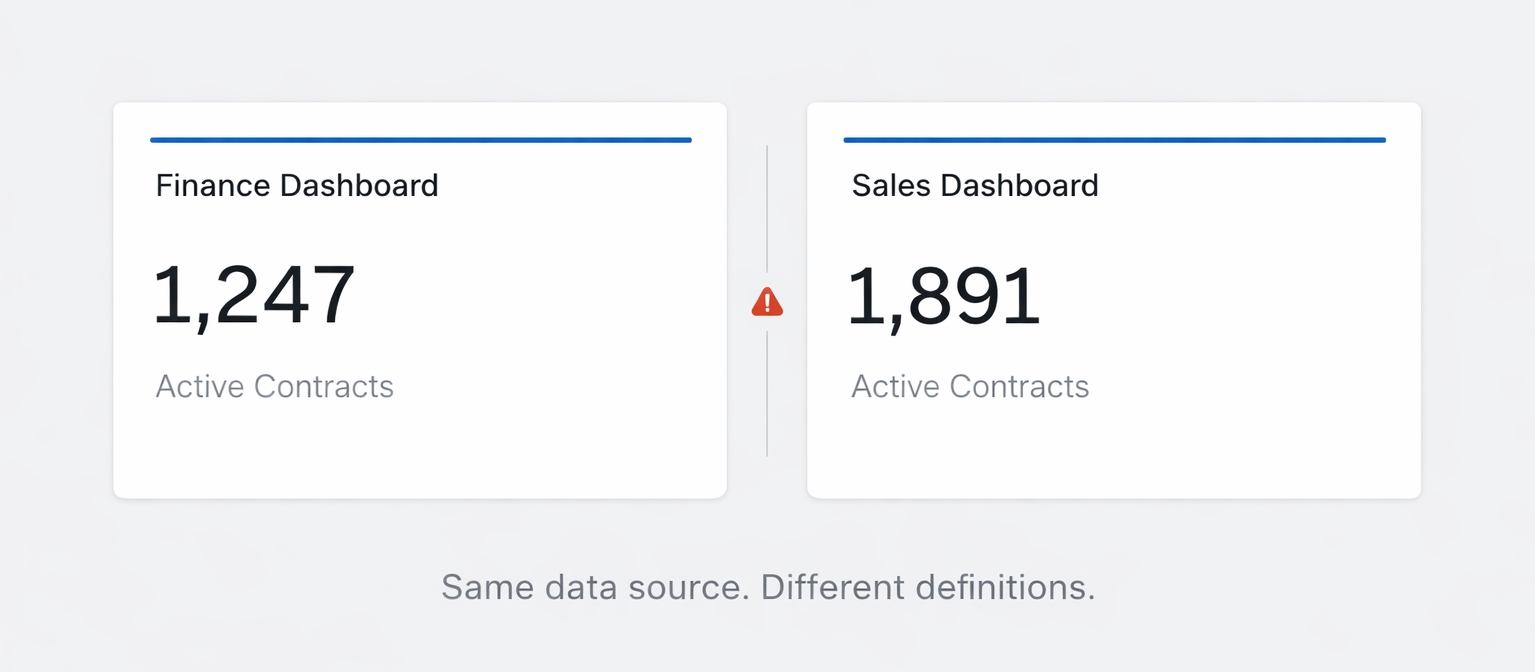
- Enterprise ontologies are designed to define business meaning, but in practice they fall out of sync as data models, dashboards, and application logic evolve independently.
- This article examines why semantic divergence is a structural problem in traditional ontology architectures, not a failure of modeling languages or governance processes.
- It then explains how SQL-based, co-located ontologies keep semantics aligned by operating directly where data is queried and consumed, rather than as a separate system.
Introduction
Most enterprises update their data warehouse schemas regularly. They revise business logic in dbt and application code even more often. Dashboards refresh daily. Pipelines evolve continuously.
Ontologies and semantic models, however, are rarely updated. Not because they don’t need to be. But because changing them is risky, expensive, and often breaks downstream systems.
So definitions freeze while the business keeps moving. Over time, the gap between what the ontology describes and how the business actually operates grows wider. Queries still run. Dashboards still load. AI systems still respond. But the meaning they rely on is no longer aligned.
This is semantic divergence, and it is one of the primary reasons ontology and knowledge graph initiatives stall after initial success.
Before going further, two clarifications are important.
First: many platforms market themselves as “semantic” or “knowledge graph” solutions while offering little more than labeled tables or static relationships. Those systems tend to fail immediately and visibly. This article addresses a different failure mode, real ontology-based and knowledge graph systems that were thoughtfully designed, adopted successfully, and worked as intended, until the business changed and the semantics didn’t.
Second: the problem of semantic divergence is not caused by the expressiveness of the ontology language. OWL/SPARQL ontologies are formally powerful, they support full OWL DL reasoning, transitive relationships, class hierarchies, cardinality constraints, and inverse properties. The failure is not representational. It is operational. The question is not whether the ontology can describe the business accurately. It is whether the ontology can stay accurate as the business changes.
Why Enterprise Semantics Diverge Over Time
Semantic models do not fail all at once. They diverge gradually as the business and data platform change around them.
1. Business definitions change
What qualified as an active contract, subscription, or recognized transaction two years ago is rarely valid today. Pricing models shift. Contract structures evolve. Eligibility rules change with new regulations.
The ontology defined “Active Contract” as any contract with a future end date. A year later, Finance excluded paused contracts, amended agreements, and early renewals. Nobody updated the semantic model.
2. Schemas evolve independently
New tables appear. Columns get renamed. Relationships change. Pipelines are refactored. Each change carries semantic implications, but the ontology is rarely updated to reflect them.
A new contract_status field replaces date-based logic. Downstream systems still reference the old definition. The ontology knows nothing about the change.
3. Logic gets duplicated across systems
Business rules live simultaneously in SQL views, BI semantic layers, dbt models, application code, and AI prompts. When definitions change, updates happen in some places but not others.
“Active Subscription” means one thing in the CRM, another in the warehouse, and something slightly different in AI-generated queries. Nobody can say which definition is authoritative.
4. No single system owns meaning
When semantic logic is scattered, there is no clear source of truth. Teams avoid making changes because the blast radius is unclear. Definitions freeze even as the business keeps moving.
The result: the ontology becomes documentation of what the business used to be, not what it actually is.
Why Semantic Divergence Breaks AI Before It Breaks BI
BI tools can limp along with slightly outdated definitions. Dashboards still show trends. Analysts can adjust. AI cannot.
LLMs rely on consistent semantic signals
When an LLM generates SQL or retrieves context, it treats the ontology as ground truth. If “Active Contract” has diverged from the real business definition, the model confidently returns answers based on outdated logic.
Small definition changes create large NL2SQL errors
A definition shifts from date-based logic to status-based logic. The ontology still encodes the old assumption. Every AI-generated query is now subtly wrong, and the error is invisible to the user.
Agents fail silently
Unlike a broken dashboard, a diverging ontology does not announce itself. The agent answers the question. The SQL executes. The result simply does not match what the business expects.
Failures are hard to debug
When an LLM hallucinates a join, the issue is obvious. When the ontology is out of sync with reality, the SQL looks correct. The logic is just based on assumptions that no longer hold.
This is why semantic divergence kills AI adoption faster than it kills BI.
Why OWL/SPARQL Ontologies Struggle With Enterprise Change
This is the part that requires precision. The dominant narrative is that OWL/SPARQL ontologies fail because they are not expressive enough. That is wrong. OWL DL is formally powerful, it supports the full range of class hierarchies, property inheritance, cardinality constraints, transitive and inverse relationships, and rule-based reasoning. For specialized domains like genomics, pharmaceutical knowledge graphs, or financial instrument taxonomies (FIBO), OWL’s expressiveness is genuinely necessary and irreplaceable.
The real failure mode is operational, not representational.
Ontologies are treated as static artifacts
Ontology design is typically a front-loaded, project-oriented effort. Domain experts, knowledge engineers, and architects collaborate to model the business. Once deployed, the ontology enters a maintenance phase that is, in practice, no maintenance at all. The organizational model assumes the hard work is done at design time.
The data stack and the ontology live in separate worlds
When the warehouse schema changes, a team runs a migration script, updates dbt models, reviews changes in version control, and deploys. The ontology, sitting in a separate triplestore, knows nothing about any of this. Keeping it synchronized requires a manual, parallel process that is expensive, error-prone, and politically difficult to prioritize.
This is the core structural problem. It is not that OWL cannot express the new business reality – it can. It is that there is no native mechanism connecting OWL’s world to the schema migration that just happened in Snowflake.
The SPARQL expertise barrier amplifies the problem
OWL ontologies are consumed via SPARQL, a powerful but specialist query language that most data engineers, analysts, and BI developers do not know. This means the semantic layer is maintained by a small team of knowledge engineers, and consumed by almost no one else directly. The more isolated the ontology, the less visibility anyone has into its drift, and the less organizational pressure there is to maintain it.
Updates break downstream systems
Modifying an ontology in production has cascading consequences. Queries may fail. Dashboards may return different numbers. Reports may shift unexpectedly. The organizational incentive is to freeze definitions, even as semantic debt accumulates. Change becomes a crisis, not a practice.
How SQL Ontologies Change the Operating Model
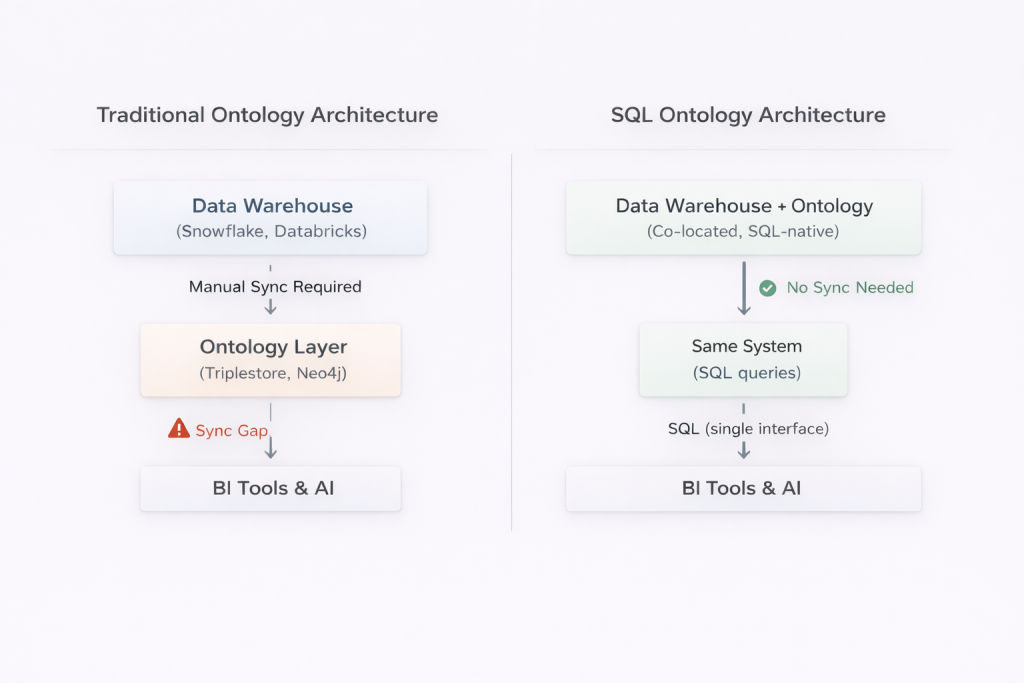
SQL ontologies address semantic divergence through an architectural insight rather than a language one: if the semantic layer lives in the same operational world as the data stack, it can be maintained using the same practices that already keep the data stack aligned.
The key claims here deserve scrutiny, so let’s be precise about what they mean in practice, using Timbr as a concrete reference point, since it represents the most mature implementation of this approach.
Co-location eliminates the synchronization gap
In Timbr, ontology concepts are SQL-native virtual tables mapped directly to warehouse tables in Snowflake, Databricks, Microsoft Fabric, or other platforms. When a schema changes, the ontology mapping can change in the same operation, the same migration script, the same PR, reviewed by the same people, governed by the same CI/CD controls. There is no parallel artifact to manually synchronize.
This is not simply a claim about SQL being easier to write. It is a claim about architectural co-location: the ontology is not beside the data stack, it is part of it.
Full OWL DL reasoning, expressed in SQL
A reasonable challenge to SQL ontologies is that they sacrifice formal expressiveness for operational convenience. The evidence does not support this concern. Timbr fully complies with OWL DL, the decidable, computationally tractable profile of OWL, and implements its inference engine as a SQL rewrite engine that automatically generates queries based on inheritance, transitivity, and other inference rules.
Practically, this means:
- Sub-concept hierarchies with full property and relationship inheritance
- Transitive reasoning across relationships (if Person IS-A Customer and Customer owns a Car, the ontology infers Person owns a Car)
- Inverse relationships, cardinality constraints, and rule-based concept classification
- Business logic is expressed directly in SQL, which allows aggregations and calculations that OWL alone cannot express
In fact, Timbr goes beyond what OWL DL supports natively by allowing SQL-expressed business rules that would otherwise require OWL extensions like SWRL or SPIN-Rules. The representational trade-off is not OWL vs. SQL, it is OWL Full (undecidable, computationally intractable) vs. OWL DL (decidable, fully supported). That is a trade-off the enterprise ontology community itself endorses.
Universal consumption without specialist skills
Because Timbr ontologies are exposed as standard SQL, ODBC/JDBC, REST, and direct BI tool connections, the semantic layer is accessible to the full data team, not just knowledge engineers. This has a compounding effect on maintenance: when everyone queries through the ontology, divergence is noticed immediately. The broader the adoption, the stronger the feedback loop that keeps definitions current.
Governance is structural, not procedural
Access control, row-level security, and lineage in Timbr are defined at the ontology level and automatically propagate to every downstream consumer dashboards, AI agents, REST APIs, notebooks. When the ontology evolves, governance evolves with it. This is different from the OWL/SPARQL model, where governance must typically be implemented separately in the triplestore and then re-implemented in every downstream system that consumes from it.
Evolution happens incrementally
Small, frequent changes are easier to test and communicate than periodic wholesale redesigns. SQL ontologies support targeted updates, add a relationship, refine a constraint, and deprecate a measure, without forcing a rebuild. The change discipline is the same as schema migration: versioned, reviewed, tested, and deployed.
What This Looks Like in Practice
Consider a common scenario: the business changes its definition of “Active Contract.”
Before:
The ontology defines “Active Contract” as any contract with a future end date.
Change:
Finance updates the definition to exclude paused contracts, amended agreements, and early renewals.
In a traditional OWL/SPARQL ontology
- The triplestore schema must be updated by a knowledge engineer
- Downstream SPARQL queries must be rewritten
- BI semantic layers must be manually synchronized
- AI prompts and NL2SQL context must be revised
- Systems may show inconsistent results during the transition period
- Because the change is isolated to a specialist team, it is often delayed or deprioritized
In a SQL ontology
- The constraint is updated in one place, in SQL, by a data engineer
- The change is versioned and tested like any schema migration
- All downstream consumers, dashboards, agents, copilots, APIs, automatically use the new definition
- Lineage tools show exactly what changed and when
- Rollback is possible if needed
This is the difference between managing semantic divergence and being managed by it.
Where OWL/SPARQL Remains the Right Choice
An honest framing of SQL ontologies requires acknowledging where the traditional OWL/SPARQL approach holds genuine advantages. These are narrower than often claimed, in particular, the reasoning and inference capabilities of OWL DL are fully matched by SQL ontologies like Timbr, so expressiveness is not the differentiator. What remains are specific deployment contexts where the OWL/SPARQL ecosystem has structural advantages.
Cross-organizational and linked data scenarios
RDF’s URI-based identity model is designed for interoperability across organizational boundaries. If your ontology needs to federate with external standards bodies, government datasets, or linked open data, OWL/SPARQL’s grounding in W3C standards is difficult to replace. Timbr supports OWL export and can interoperate with triplestores, but the native environment is enterprise SQL, not the open web of linked data.
Existing OWL investments
Organizations that have already built substantial OWL ontologies, particularly in regulated industries using standards like FIBO (financial) or FHIR (healthcare), have significant institutional knowledge embedded in those models. The path is not necessarily to abandon them. Timbr itself offers OWL-to-SQL migration paths, allowing organizations to bring existing OWL models into the SQL-native operational layer while preserving the modeling work already done.
What High-Performing Teams Do Differently
Organizations that maintain semantic models successfully treat them as living systems, not project deliverables. The tooling choice matters, but the operating model matters more. Specifically:
- They treat semantic changes like code changes – definitions are versioned, changes are reviewed, and tests validate assumptions before deployment.
- They version business definitions explicitly – “Active Contract” is not static; versioned definitions make evolution explicit and auditable.
- They test semantic assumptions continuously – automated checks validate constraints, relationships, and measures before users notice issues.
- They roll changes forward instead of freezing models – deprecation windows and migration paths replace fear-driven stagnation.
- They use one semantic layer across BI, AI, and agents – when every tool queries the same ontology, inconsistencies surface immediately rather than silently.
Conclusion
Semantic divergence is not a failure of modeling. It is the natural result of a changing business operating in the real world. The failure comes from treating ontologies as static artifacts that must be protected from change, rather than living systems designed to evolve safely.
The traditional critique of OWL/SPARQL ontologies that they lack expressiveness for enterprise use, is largely misplaced. What they lack is operational integration. They were designed to represent knowledge correctly, not to stay synchronized with a changing data platform inside a fast-moving enterprise. That is a structural problem, not a language problem.
SQL ontologies, as implemented by platforms like Timbr, address this structural problem directly. They achieve OWL DL-equivalent reasoning while making the semantic layer a native citizen of the data stack subject to the same migration discipline, governance controls, and CI/CD practices that teams already use to manage schemas and transformations. The ontology evolves because it is connected, not isolated.
For enterprises whose primary need is aligning business definitions across BI, AI, and agents against a live relational data platform, this operational integration is the decisive advantage. OWL/SPARQL retains its place for domains requiring cross-organizational linked data interoperability or W3C standards compliance for external federation. But for the majority of enterprise semantic layer use cases where the goal is trustworthy, consistent, AI-ready business definitions that stay current, the operating model of SQL ontologies is built to last, not just to launch.
Dashboards stay aligned. AI stays accurate. Trust remains intact.
