
What Is NL2SQL?
Definition, architecture, and enterprise use cases
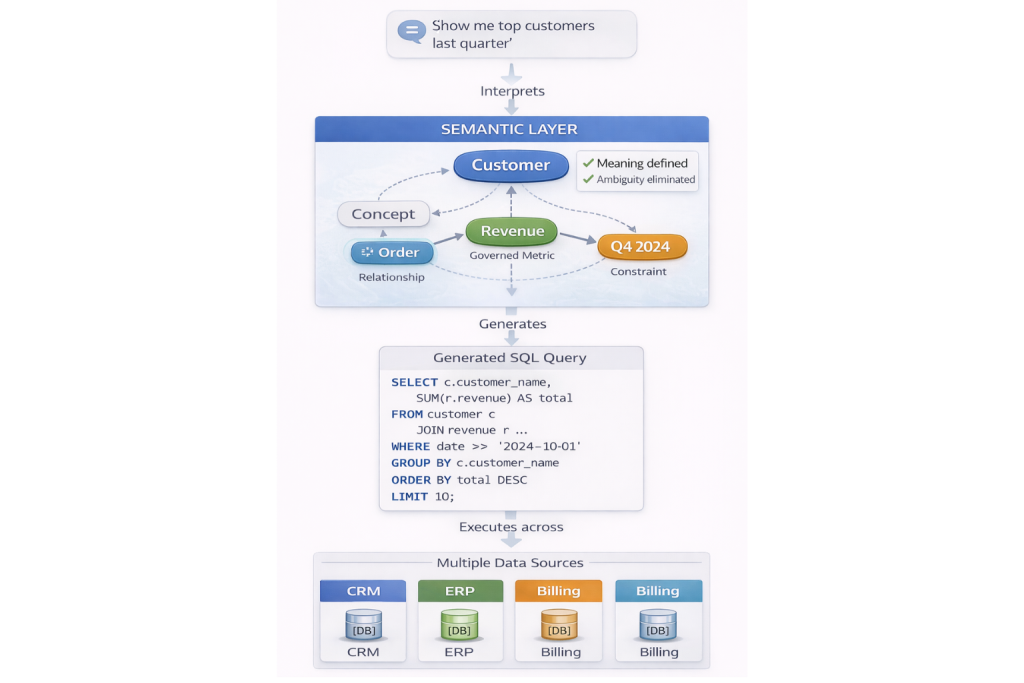
What Is Natural Language to SQL (NL2SQL)?
Natural Language to SQL, commonly referred to as NL2SQL, is a class of systems designed to translate human-language questions into executable SQL queries. The goal is straightforward: allow users to ask questions like “What were our top customers last quarter?” and receive accurate results without writing SQL.
At a glance, NL2SQL looks like an AI problem. Advances in large language models have made it possible to generate syntactically valid SQL with impressive fluency. In demos and sandbox environments, these systems often look magical.
In real enterprise environments, however, NL2SQL frequently fails in subtle and costly ways. Queries execute successfully. Results look reasonable. And yet the answers are wrong.
The reason is not model quality. It is missing structure.
NL2SQL systems do not fail because they cannot generate SQL. They fail because they lack a shared, explicit understanding of business meaning. Without semantic structure, natural language questions are ambiguous – and ambiguity cannot be resolved reliably at query time.
How NL2SQL Works
Most NL2SQL systems follow a similar multi-step pipeline, regardless of whether they are embedded in BI tools, data platforms, or AI copilots.
Intent and Entity Extraction
The system first attempts to understand the user’s question by identifying intent and entities. For example:
- “Top customers”
- “Last quarter”
- “Revenue”
At this stage, ambiguity is unavoidable. Does “customer” refer to an account, an end user, or a billing entity? Does “top” mean highest revenue, most transactions, or largest lifetime value?
Natural language alone does not contain enough information to answer these questions definitively.
Schema Mapping
Next, the system maps extracted entities to database structures. It attempts to associate concepts like “customer” or “revenue” with tables, columns, and join paths.
In schema-only environments, this mapping relies on:
- Column names
- Table metadata
- Statistical similarity
- Training examples
If multiple candidates appear plausible, the system selects one based on probability rather than meaning.
This is the point where NL2SQL systems often diverge silently from business intent.
SQL Generation and Execution
Once a mapping is selected, the system generates SQL and executes it against the database. Modern models excel here. The query runs. The database returns results.
Crucially, SQL execution success does not imply semantic correctness. A query can be syntactically perfect while answering the wrong question.
Where NL2SQL Works Well
NL2SQL performs reasonably well under specific conditions.
It works best when:
- Schemas are simple and well-named
- Definitions are unambiguous
- The analytical domain is narrow
- Results are manually validated
In these environments, NL2SQL acts as a convenience layer rather than a reasoning system. Being slightly wrong is tolerable, and errors are caught quickly. For teams with a single curated dataset and governed metrics, NL2SQL can be a meaningful productivity boost.
Enterprise environments rarely meet these conditions.
The Enterprise Reality of NL2SQL
In real organizations, natural language questions are overloaded with implicit assumptions.
Different teams use the same words to mean different things. Metrics evolve. Relationships depend on context. Schemas change independently across systems.
NL2SQL systems are expected to bridge this complexity automatically. Without explicit semantic grounding, they cannot.
Domain-Specific Meaning Collisions
These collisions show up as soon as language hits enterprise ambiguity.
Consider a financial services organization.
In retail banking, an “active account” might mean one with recent transactions. In wealth management, “active” may mean assets under management above a threshold. In compliance, “active” could mean not closed, regardless of usage.
A user asks: “How many active customers do we have?”
The NL2SQL system must choose which definition applies. Without a shared semantic model, it guesses based on which table it maps to first. The SQL runs. The answer looks reasonable.
The retail banking team reports 150,000 active customers. The wealth management team reports 12,000. Compliance reports 200,000. All three numbers came from the same NL2SQL system, all answering what appears to be the same question.
When these numbers appear in a consolidated executive report, discrepancies trigger investigations. Days are spent reconciling definitions that were never explicit to begin with. The NL2SQL system is blamed for being “unreliable,” but the actual problem is structural.
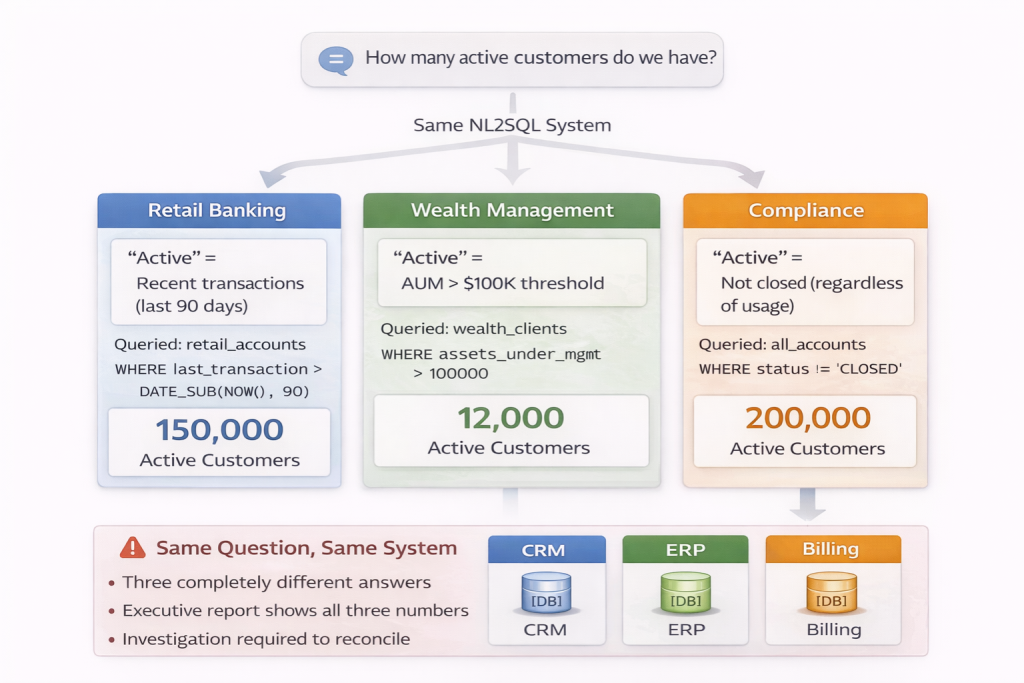
Similar issues appear across industries:
- Healthcare: What counts as a “patient visit” – ER intake, scheduled appointment, or completed treatment? Different departments use different definitions, and NL2SQL systems have no way to determine which applies.
- E-commerce: Is a “customer” the purchaser, the recipient, or the account holder? A question about “top customers” produces different answers depending on which entity the system maps to.
- SaaS: Does “revenue” mean billed, collected, recognized, or projected? Each definition serves a legitimate purpose, but NL2SQL systems cannot determine intent from natural language alone.
These are not edge cases. They are the norm in any organization with multiple systems, teams, or domains.
What Breaks Without Semantic Structure
Consider a common failure cascade.
A user asks: “Show me our top customers last quarter.”
The system must decide:
- Which customer definition applies
- Which revenue metric to use
- Which time logic defines “last quarter”
- Which relationships connect customers to revenue
In a schema-only environment, these decisions are inferred at query time.
The system selects a join path between an orders table and a customers table based on a foreign key. It chooses a revenue_amount column because the name matches. It applies a date filter to order_date using a fiscal quarter calculation.
Illustrative example (schemas vary across organizations):
SELECT c.customer_name, SUM(o.revenue_amount) AS total
FROM customers c
JOIN orders o ON c.customer_id = o.customer_id
WHERE o.order_date >= ‘2024-10-01’ AND o.order_date < ‘2025-01-01’
GROUP BY c.customer_name
ORDER BY total DESC
LIMIT 10;
The query runs. Results appear:
- Customer A: $2.5M
- Customer B: $1.8M
- Customer C: $1.6M
- …
The numbers look reasonable. The user shares them in a presentation.
Three weeks later, the finance team presents their quarterly customer report. The top customers list is completely different. Finance used recognized_revenue from a different table, applied billing_customer_id instead of shipping_customer_id, and calculated quarters based on fiscal periods, not calendar months.
Both queries are valid SQL. Both produce plausible results. But they answer fundamentally different questions.
Analysts begin adding conditional logic in dashboards to reconcile differences. Engineers encode assumptions in pipelines to “fix” discrepancies. AI systems now require human review to determine which joins and metrics are valid before generating queries.
Trust erodes. Teams revert to custom SQL and manual validation. The NL2SQL system still functions, but it is no longer used for anything important.
These failures are structural, not model-related.
Why NL2SQL Depends on Semantic Structure
NL2SQL systems do not reason over tables. They reason over meaning.
Without explicit semantics, every natural language question becomes a guessing exercise.
Concepts Must Be Explicit
NL2SQL requires clearly defined concepts such as Customer, Order, or Revenue. These cannot be inferred reliably from schemas alone.
In most organizations, customer data exists across CRM, billing, and support systems. A CRM system stores customer_id with contact details and account status. A billing platform uses account_number with payment history. A support system references support_user_id tied to tickets and interactions.
Table-centric models treat these as separate entities. NL2SQL systems must choose which one applies to the question “Who are our customers?” The choice is often arbitrary, based on which table appears first in metadata or which column name scores highest in similarity matching.
An ontology-based model defines Customer as a single concept and maps each system’s identifiers to it explicitly. The concept unifies these representations semantically without requiring schema consolidation. When a user asks about customers, the system has a single, governed target to query against.
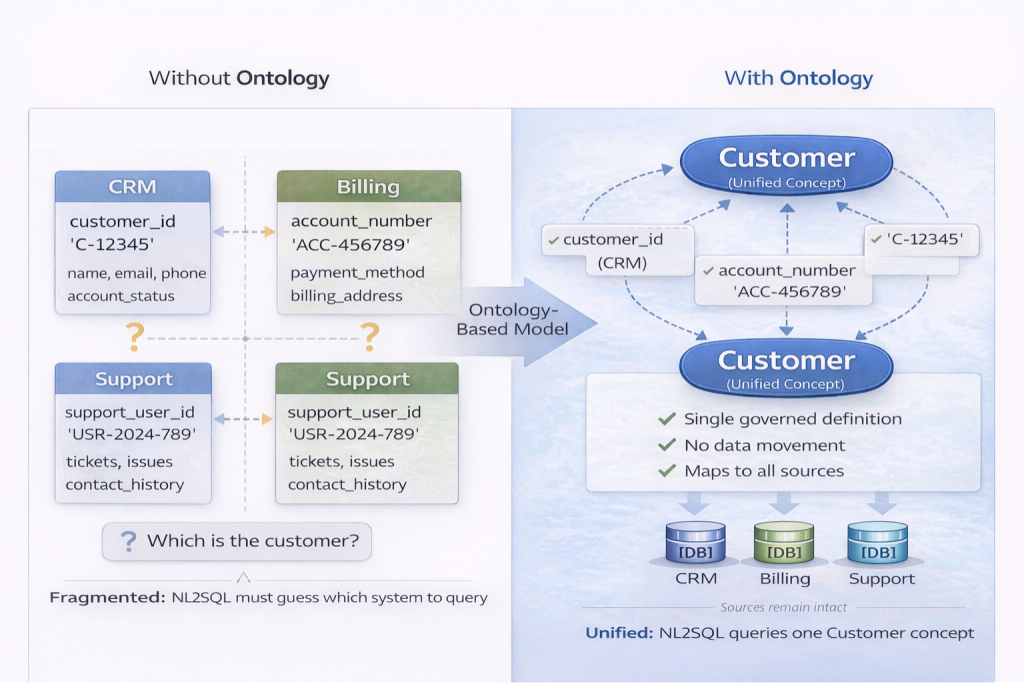
Concepts Must Be Explicit
Relationships Must Be Declared
Joins are not semantics. Relationships carry intent.
A system must know the difference between:
- Order billed to Customer
- Order shipped to Customer
In schema-only environments, both relationships may exist as foreign keys: orders.billing_customer_id and orders.shipping_customer_id. When a user asks “Show me customer orders,” NL2SQL systems must guess which relationship applies.
Most systems default to whichever join appears more frequently in training data or metadata. This produces inconsistent results depending on context. A billing-focused question gets the wrong relationship. A logistics question joins incorrectly.
Declared, named relationships eliminate this ambiguity. The system can distinguish intent and, when needed, either request clarification or apply business rules to select the correct relationship.
Metrics Must Be Governed
NL2SQL systems must rely on shared, validated metric definitions.
In enterprise systems, “revenue” may exist as:
- Gross revenue: Total transaction amounts before any deductions
- Net revenue: After discounts, returns, and adjustments
- Recognized revenue: Aligned with accounting recognition rules
- Projected revenue: Forecasted based on pipeline and historical trends
Each definition serves a legitimate business purpose. Schema-only NL2SQL systems select whichever column name matches best – often revenue or revenue_amount – without understanding which variant applies.
A semantic layer exposes governed metric definitions where “Revenue” is defined explicitly with its calculation logic, time behavior, and valid contexts. NL2SQL queries against this governed definition rather than guessing at column mappings.
Constraints Prevent Hallucination
Constraints restrict what interpretations are valid.
For example, a constraint may prevent joining inactive customers to active orders, or restrict revenue calculations to recognized transactions only. Another constraint might enforce that “last quarter” always uses fiscal quarters for financial reporting contexts.
Consider a specific scenario: a user asks, “Show revenue for customers in churned status last quarter.” A constraint rule states that revenue metrics are only valid for active customers unless explicitly overridden. The system can either request clarification or return a governed interpretation based on business rules, rather than generating a query that violates logical constraints.
These constraints limit the interpretation space before SQL is generated, preventing plausible but invalid queries from executing. Instead of generating any syntactically correct SQL, the system generates SQL that respects business rules and valid relationships.
This is how NL2SQL systems avoid hallucinating queries that look right but violate business logic.
NL2SQL, Knowledge Graphs, and GraphRAG
NL2SQL does not operate in isolation.
Knowledge graphs provide explicit relationship structure between entities. Semantic layers expose stable, governed definitions. GraphRAG systems use these structures to assemble context for AI reasoning.
NL2SQL relies on the same foundation.
A question like “Which customers were affected by delayed shipments last month?” requires traversing multiple relationships:
Customer → Order → Shipment → Delay
Without declared relationships, this traversal becomes guesswork. The system must infer which tables to join, in what order, and under what conditions. Each inference point introduces potential error.
With explicit knowledge graph relationships, the path is clear. The system knows that Orders are placed by Customers, Orders generate Shipments, shown in Delivery status. The question maps to a relationship traversal rather than a probabilistic join selection.
This is the same structural dependency that makes GraphRAG effective: context assembly requires explicit relationships, not inferred connections.
The Enterprise Adoption Reality
NL2SQL systems often succeed in demos and fail in production.
The difference is not the technology. It is the gap between controlled environments and real enterprise complexity.
Demos use clean, single-domain datasets with unambiguous definitions. Questions are carefully scoped. Results are manually validated. Success rates appear high because the test conditions eliminate the ambiguity that exists in production.
Production environments have overlapping systems, evolving definitions, and context-dependent meanings. Questions come from users who do not understand the data model. Results are trusted without validation because that is the promise of NL2SQL.
This creates what can be called the “uncanny valley” of NL2SQL. The system works 80% of the time, fails 20% of the time, and users cannot predict which questions will succeed. After a few unexpected failures, trust collapses entirely.
Organizations often abandon NL2SQL not because it never works, but because unreliable answers are worse than no answers at all. Users would rather wait for an analyst than risk making decisions based on plausible but incorrect data.
How Timbr Approaches NL2SQL
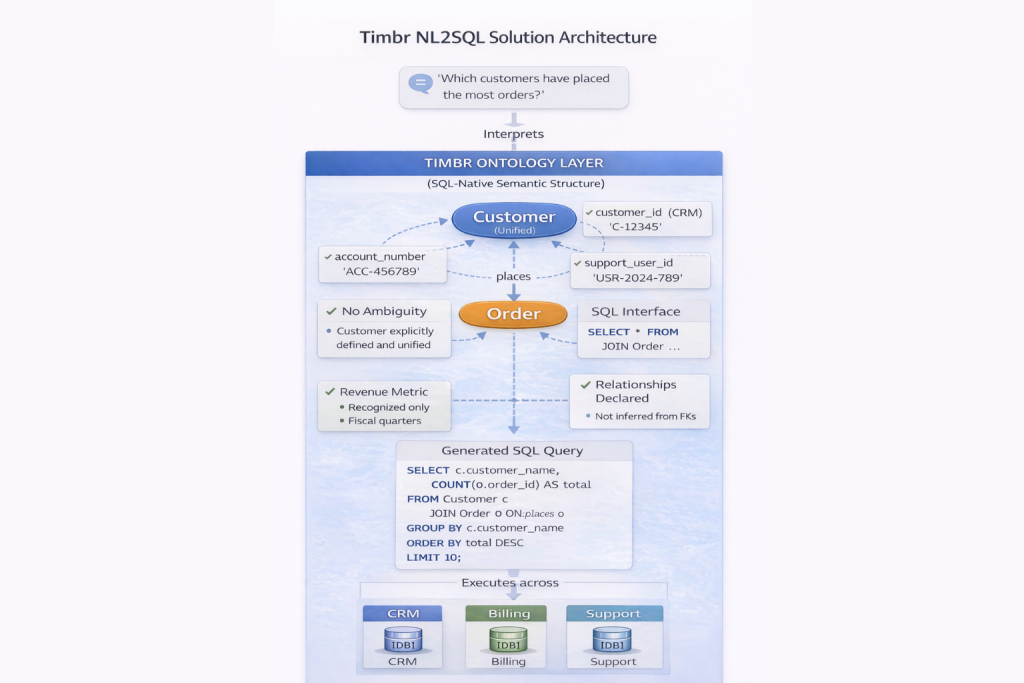
Timbr approaches NL2SQL by removing ambiguity before a query is generated.
Natural language questions are interpreted against an ontology-based semantic layer, not against raw schemas. Business meaning is modeled explicitly as concepts, relationships, governed metrics, and constraints, and enforced structurally at query time.
When a user asks for “top customers,” the system does not infer intent from column names or training probabilities. The ontology already defines:
- Which Customer concept applies – a unified business entity mapped across CRM, billing, and support systems
- Which revenue metric is valid – a governed SQL measure with explicit calculation logic, time behavior, and business context
- Which relationships are allowed – orders placed by customers, not shipments delivered to recipients
- Which constraints apply – active customers only, fiscal quarter definitions, and valid join paths
SQL is generated within these semantic boundaries, not through probabilistic schema matching. If a question violates business rules or lacks sufficient clarity, the interpretation space is constrained or flagged, rather than silently producing a plausible but incorrect query.
Because the ontology is SQL-native and executable, definitions are not duplicated across tools. The same semantic model powers BI dashboards, applications, APIs, and NL2SQL. When a definition changes, it changes once and propagates automatically everywhere it is consumed.
This shifts NL2SQL from a probabilistic guessing problem into a constrained interpretation problem.
The system does not guess which table, column, or metric to use. It knows because meaning is explicit, governed, and enforced by design.
Summary
Natural Language to SQL systems translate human questions into executable queries. While AI advances have improved SQL generation, enterprise NL2SQL failures persist.
The root cause is not model quality. It is missing semantic structure.
NL2SQL systems succeed only when business meaning is explicit, relationships are declared, metrics are governed, and constraints are enforced. Without these foundations, queries become plausible but wrong, and trust erodes quickly.
NL2SQL is not an AI problem. It is a data modeling problem.
If you want to see how natural language querying works when business meaning is explicit and governed, explore Timbr’s ontology-driven approach to NL2SQL.
