
What Is a Knowledge Graph?
Definition, structure, and enterprise use cases
What Is a Knowledge Graph?
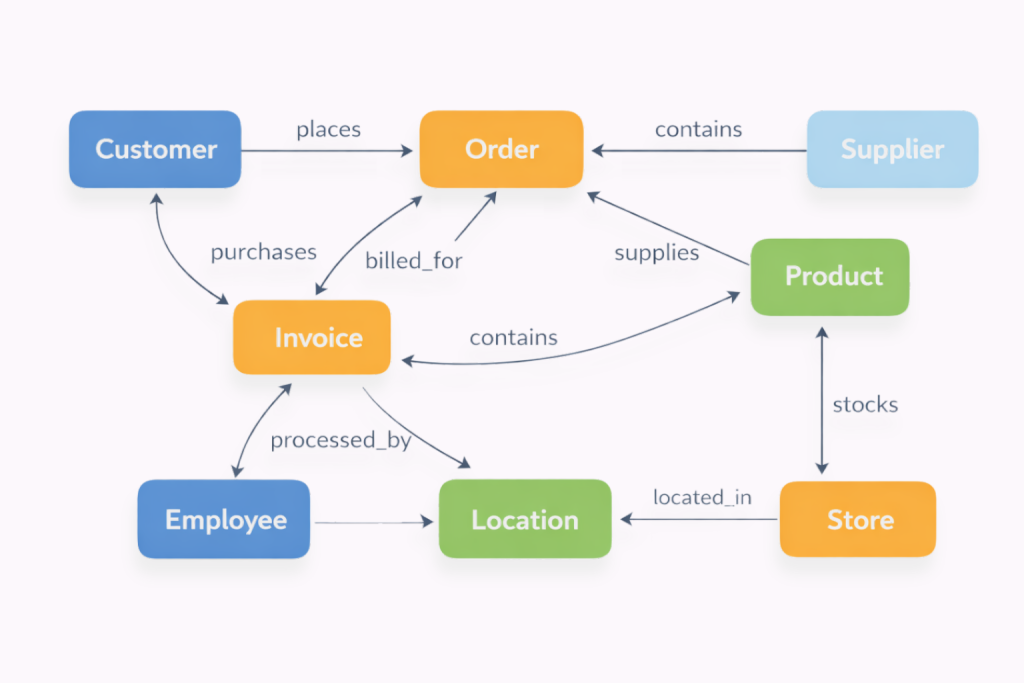
A knowledge graph is a way of organizing and accessing data by representing real-world entities and the relationships between them. Instead of storing information as isolated rows and tables, a knowledge graph connects entities (concepts) – such as people, organizations, products, or events – in a structure that preserves meaning and context.
A knowledge graph does not require data to be physically stored in graph form. The graph may be materialized, virtual, or a combination of both. What defines a knowledge graph is the explicit modeling of concepts and relationships, independent of how or where the underlying data is stored.
Each entity is described by its properties, and each relationship explicitly defines how entities are connected. This makes it possible to understand not just what data exists, but how different pieces of data relate to one another across systems, domains, and business contexts.
By modeling data this way, knowledge graphs help both humans and machines interpret information more accurately, answer complex questions, and work with data in a form that reflects how the real world is connected.
How Knowledge Graphs Differ From Traditional Data Models
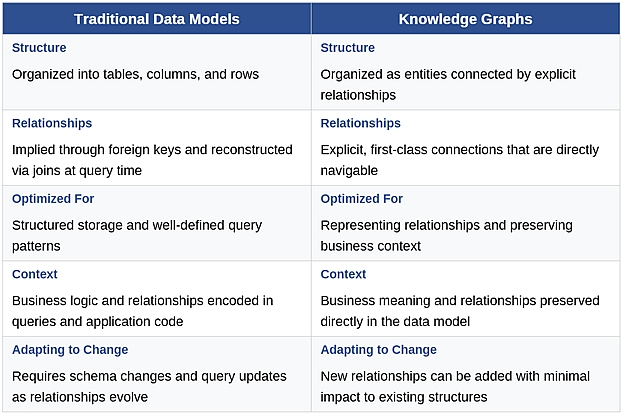
Traditional data models are designed to store and retrieve records efficiently. Information is organized into tables, columns, and rows, with relationships implied through keys and joins. This structure works well when data is stable, well-defined, and queried in predictable ways.
Knowledge graphs take a different approach. Instead of treating relationships as something reconstructed procedurally at query time, they model relationships as first-class elements of the data model itself. These relationships may be defined logically and resolved dynamically, rather than being embedded directly in physical storage structures. Entities are explicitly connected to one another, and those connections carry meaning. This makes it possible to navigate data based on how things are related, not just how they are stored.
The practical difference is context. In a traditional model, understanding how customers relate to products, transactions, regions, or policies often requires complex joins and assumptions baked into queries or applications. In a knowledge graph, those relationships are part of the model. The structure reflects how the domain actually works, regardless of how the data happens to be stored, which makes it easier to ask complex questions, adapt to change, and reason across systems without rewriting logic every time requirements evolve.
Core Components of a Knowledge Graph
A knowledge graph is built from a small set of core components that work together to represent real-world information in a connected and meaningful way. While implementations vary, most knowledge graphs share the same foundational elements.
| Component | What It Represents | Example |
|---|---|---|
| Entity (or Concept) | A real-world object or idea that the organization cares about | Customer, Product, Order |
| Property | A characteristic that describes an entity or relationship | Customer ID, Order Date, Status |
| Relationship | A meaningful connection between entities | Customer placed Order |
Entities represent the things a business cares about. These may correspond to physical records, logical abstractions, or unified concepts spanning multiple systems. Each entity corresponds to a distinct real-world object or idea and serves as a primary anchor within the graph. An entity does not need to map one-to-one to a single table or data source.
Properties describe entities by capturing their attributes. These properties may be stored directly, derived, or computed from underlying data sources at query time. For example, a customer entity might have properties such as name, region, or account status. Properties add descriptive detail, but on their own, they do not explain how entities relate to one another.
Relationships define how entities are connected. A relationship might express that a customer placed an order, a product belongs to a category, or a transaction occurred at a location. Unlike traditional models, where relationships are inferred procedurally through joins, knowledge graphs define relationships explicitly as part of the semantic model, even when the underlying data remains relational.
For example, a customer entity can be connected to an order entity through a “placed” relationship, while the order itself has properties such as order date, status, and total amount. This structure allows systems to understand not just the individual data points, but how they relate within a business context.
Together, entities, properties, and relationships form a connected structure that reflects how information exists in the real world. This structure makes it possible to navigate data based on meaning and context, rather than reconstructing connections through logic embedded in queries or applications.
What Are Knowledge Graphs Used For?
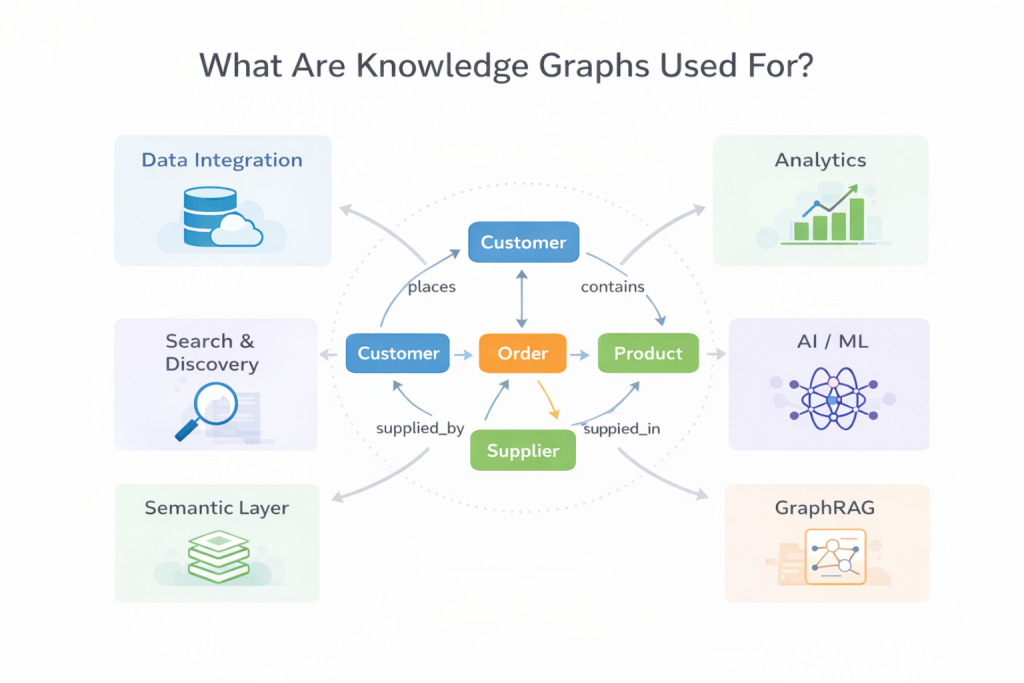
Knowledge graphs are used to connect data across systems, domains, and formats in a way that preserves meaning. Rather than focusing on a single application, they act as a foundational layer that supports multiple use cases where understanding relationships matters.
Data Integration and Unification
Organizations use knowledge graphs to link data across different systems without forcing itinto a single physical schema. Entities and relationships can be defined over existing sources while each system remains intact.
Example: A customer in a CRM can be connected to their orders in an e-commerce system and their support tickets in a service platform without copying or reshaping the underlying data.
Analytics and Decision-Making
By modeling relationships directly, knowledge graphs make it easier to ask complex questions that span multiple dimensions. Analysts can explore how entities relate without embedding business logic repeatedly in joins or transformations.
Example: An analyst can examine how product returns correlate with suppliers, regions, and delivery timelines in a single query path.
Search and Discovery
Knowledge graphs improve search by allowing systems to understand intent and relationships, not just keywords. This enables more accurate results when users search for concepts, entities, or the connections between them. This applies whether the graph is materialized or resolved dynamically at query time.
Example: A search for a customer surfaces related contracts, active orders, and recent issues instead of unrelated records with similar names.
AI and Machine Learning Support
Knowledge graphs provide structured, governed context that AI systems can rely on. This is true regardless of how the underlying data is stored. By grounding models in explicit relationships and definitions, they reduce ambiguity and improve the reliability of AI-driven analysis.
Example: An AI assistant answering revenue questions uses defined relationships between customers, orders, and invoices instead of inferring meaning from raw tables.
The Enterprise Reality
Most explanations of knowledge graphs stop at structure and use cases. In practice, this is where things get more complex.
In enterprise environments, data does not live in a single system, follow a single definition, or change at a predictable pace. The challenge is not modeling relationships in isolation, but maintaining consistency as data moves across teams, platforms, and business processes.
A knowledge graph only becomes useful at scale when it can handle these realities, whether it is implemented as a physical graph, a virtual semantic layer, or a hybrid of both.
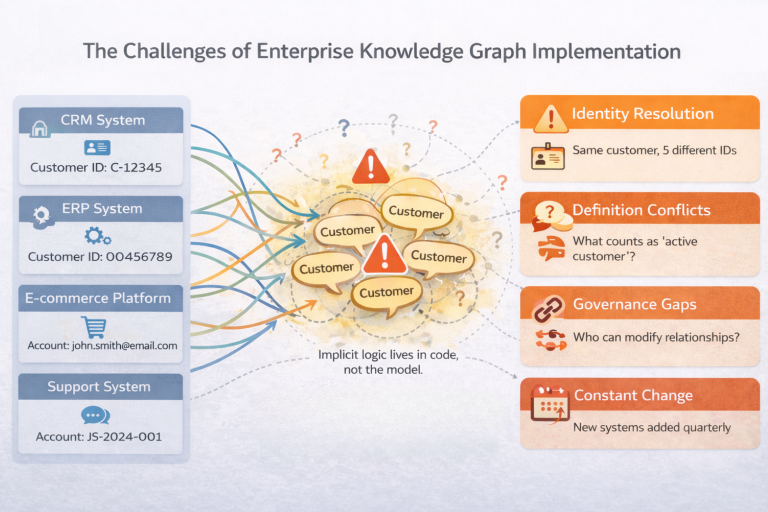
First, identity must remain consistent. The same customer, product, or organization often appears in multiple systems under different identifiers. Without a shared way to resolve and maintain identity, relationships quickly become unreliable.
Second, business definitions matter. Concepts like “customer,” “order,” or “revenue” often mean different things to different teams. If those definitions are not explicitly modeled, the graph reflects ambiguity instead of clarity.
Third, relationships need rules. In real systems, relationships are not just connections. They carry constraints, direction, and meaning. For example, who is allowed to modify a relationship, when it is valid, or how it behaves over time. Without these rules, graphs may look correct visually but fail under real analytical or operational workloads.
Finally, change is constant. New systems are added, definitions evolve, and governance requirements increase. A knowledge graph must adapt without requiring a full redesign every time something changes.
This is the point where many theoretical knowledge graphs struggle. The difference between a working demo and a production-ready knowledge graph is the ability to manage identity, definitions, constraints, and change as first-class concerns.
What Breaks in Production
In controlled environments, knowledge graphs often appear to work well. Data volumes are limited, relationships are clean, and assumptions hold. In production, those assumptions break down quickly.
What fails is rarely the idea of a knowledge graph itself. What fails is the ability to maintain correctness, consistency, and trust as the graph grows, evolves, and is used by many teams simultaneously.
Below are the most common failure points seen when knowledge graphs move from prototype to production.
Identity Resolution Breaks Down
In production systems, the same real-world object often appears under different identifiers across sources. A single customer may exist as multiple records in CRM, billing, support, and analytics systems.
If identity resolution is handled inconsistently or deferred to downstream queries, relationships degrade over time. Analysts lose confidence in results, and teams begin compensating with manual logic outside the graph.
Once identity becomes unreliable, every connected insight built on top of it becomes questionable.
Business Definitions Drift
Production environments rarely have a single, stable definition of core concepts like customer, order, or revenue. Definitions evolve as business rules change, teams reorganize, or systems are replaced.
When definitions are not explicitly modeled and governed, knowledge graphs begin to encode assumptions instead of meaning. Queries return technically correct results that contradict business expectations.
Over time, different teams interpret the same graph differently, undermining its role as a shared source of truth.
Relationships Lose Semantics
In real systems, relationships are not just links. They have direction, constraints, ownership, and lifecycle rules. Some relationships are valid only under certain conditions or timeframes.
When these rules are not enforced at the model level, graphs may look correct visually but fail under analytical or operational workloads. Users unknowingly traverse invalid paths or combine relationships that should never be evaluated together.
At scale, the absence of semantic rules leads to subtle errors that are difficult to detect and even harder to debug.
Change Becomes Risky
Production systems change constantly. New data sources are added, schemas evolve, governance requirements increase, and usage expands beyond the original design.
In many implementations, even small changes require significant rework. Teams hesitate to evolve the model because downstream dependencies are unclear, brittle, or undocumented.
At that point, the graph stops being a living representation of the business and becomes another system that teams work around instead of relying on.
Trust Erodes
When identity is inconsistent, definitions drift, relationships misbehave, and change is risky, users lose trust. Analysts fall back on custom queries. Engineers bypass the graph for critical workloads. AI systems consume inconsistent context.
The graph may still exist, but it is no longer authoritative.
This is the gap between a working demo and a production-grade knowledge graph.
Knowledge Graphs and AI
Artificial intelligence systems increasingly rely on data to reason, answer questions, and support decision-making. Large language models, recommendation engines, and analytical agents all depend on context to produce meaningful results. When that context is inconsistent, ambiguous, or incomplete, AI systems do not fail gracefully – they amplify errors.
This is where knowledge graphs become critical. Not as a novelty or enhancement, but as a way to provide explicit, governed context that AI systems can depend on.
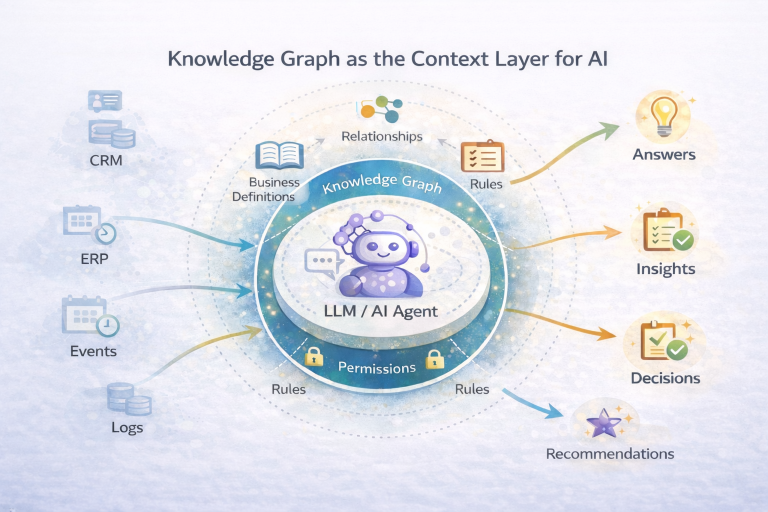
Why AI Needs More Than Raw Data
Modern AI systems excel at pattern recognition, but they do not inherently understand business meaning. They operate on signals derived from data, not on the intent, definitions, or constraints that govern how data should be interpreted.
Without an explicit representation of concepts and relationships:
- The same entity can be interpreted differently across prompts, tools, or workflows
- Business rules are inferred inconsistently instead of being enforced
- Context shifts based on how data is retrieved rather than what it represents
In these conditions, AI outputs may appear fluent and confident while being semantically incorrect.
Knowledge Graphs as Context Providers for AI
Knowledge graphs address this gap by encoding business meaning directly into the data model. Concepts, relationships, and constraints define how information connects and under what conditions it is valid.
Rather than asking AI systems to infer meaning from raw tables or fragmented schemas, the graph provides an explicit semantic map. This gives AI a stable foundation to reason over, instead of relying solely on probabilistic inference.
When used alongside AI systems, knowledge graphs help ensure that:
- Entities are consistently identified across sources
- Definitions remain stable as data evolves
- Relationships carry direction, scope, and meaning
- Outputs reflect business reality, not just syntactic matches
Grounding AI in Enterprise Reality
In enterprise environments, AI systems rarely operate on a single dataset or domain. They interact with data spanning finance, operations, customers, products, and policies – each with its own definitions and constraints.
A knowledge graph acts as a grounding layer between AI and underlying data systems. It allows AI-driven applications to retrieve information through business concepts rather than raw tables or application-specific logic. This reduces ambiguity, improves consistency, and makes results easier to validate.
As AI moves from experimentation into operational and decision-support workflows, this grounding becomes essential. Without it, the same issues that break knowledge graphs in production – identity drift, definition conflicts, and semantic ambiguity – surface even faster in AI-driven systems.
From Intelligence to Trust
The value of AI in the enterprise is not just speed or automation. It is trust.
Decision-makers need to understand where answers come from, how conclusions were formed, and whether results align with established business logic. Knowledge graphs support this by anchoring AI systems in shared definitions and governed relationships.
They do not replace AI reasoning. They make it usable in real-world environments.
This is the difference between AI that generates responses and AI that organizations are willing to rely on.
How Timbr Approaches Knowledge Graphs
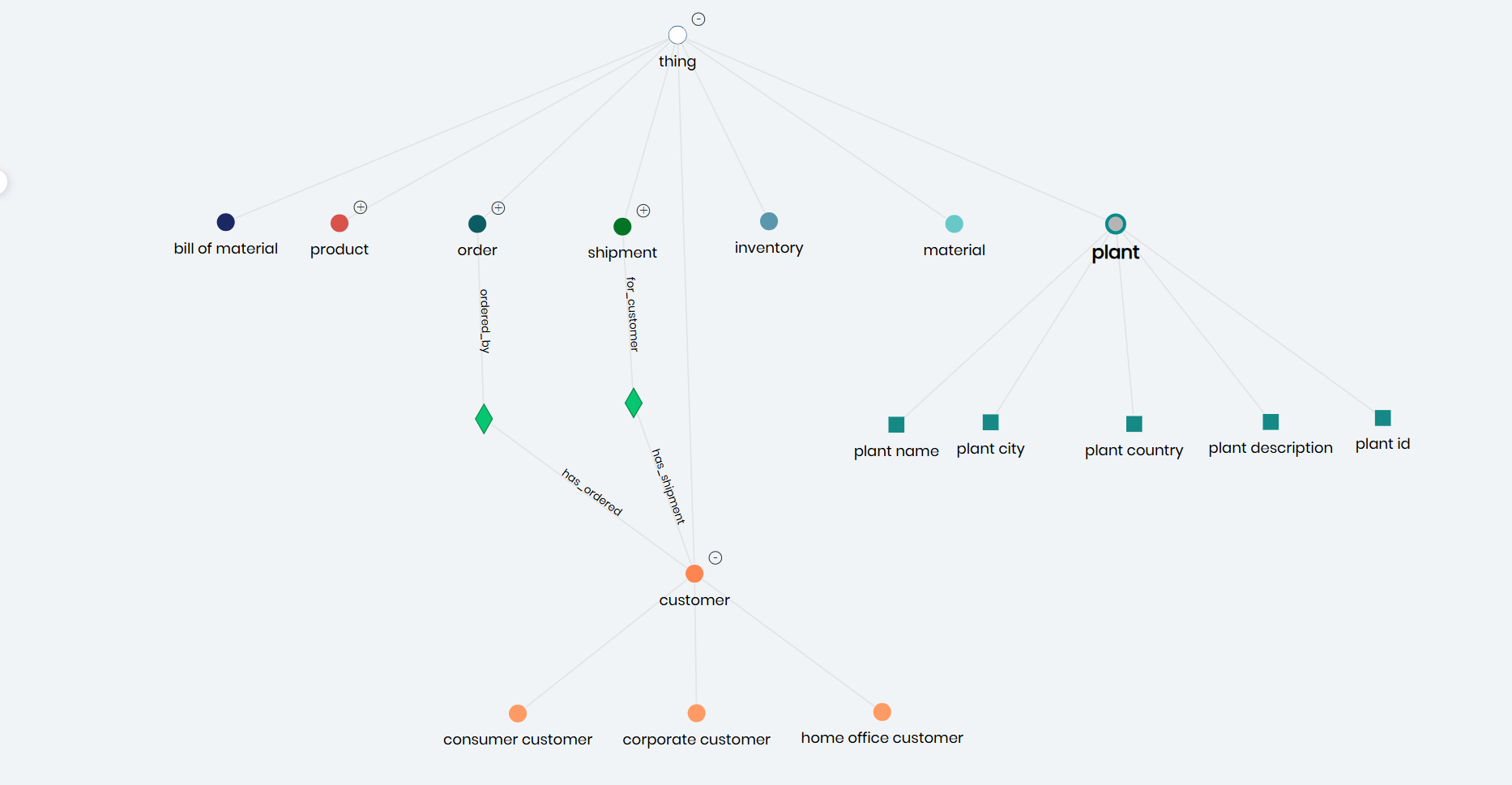
The challenges described above are not theoretical, they emerge from how knowledge graphs are modeled, governed, and maintained over time. As data grows, systems change, and more teams rely on shared models, early design decisions determine whether a graph remains trustworthy or gradually degrades.
Timbr approaches knowledge graphs by treating semantics, governance, and consistency as first-class design concerns rather than downstream considerations. At its core, this approach aligns with ontology-based modeling, where business concepts, relationships, and constraints are defined explicitly rather than inferred implicitly at query time. Rather than emphasizing storage, query patterns, or visualization, the focus is on how business meaning is defined, enforced, and preserved as data evolves.
SQL-Native Semantic Modeling
Timbr models knowledge graphs directly in SQL. Semantic concepts, relationships, and constraints are defined using the same language organizations already use to manage and govern their data.
This keeps the semantic model grounded in how data is actually produced, validated, and audited. Instead of introducing a parallel modeling language or runtime, semantics remain close to the source systems and the teams responsible for them.
By staying SQL-native, the knowledge graph integrates naturally with existing data platforms, governance processes, and operational workflows.
Explicit Concepts and Relationships
In Timbr, concepts and relationships are modeled explicitly rather than inferred implicitly through queries or application logic. Business meaning is defined at the model level and reused consistently across consumers.
This makes it possible to:
- Enforce consistent business definitions across teams
- Prevent ambiguous or invalid relationship traversal
- Preserve context as data is queried across domains
The result is a knowledge graph that reflects how the organization understands its data, not just how the data happens to be stored.
Built-In Governance and Constraints
Enterprise knowledge graphs require more than connectivity. They require rules.
Timbr allows constraints, permissions, and validation logic to be defined directly as part of the semantic model. This includes rules around identity resolution, relationship validity, and access control.
Because governance is embedded in the model itself, consistency does not depend on downstream tooling or custom logic. The graph remains reliable even as more users, applications, and analytical workloads depend on it.
This dramatically increases the success rate of NL2SQL, retrieval, and AI-agent workflows, helping organizations move from pilots to production-grade GenAI.
Built-In Governance and Constraints
Enterprise environments are not static. New systems are added, definitions evolve, and regulatory requirements increase.
Timbr separates semantic intent from physical data layout. This allows the knowledge graph to evolve without breaking downstream consumers or requiring repeated redesigns. Changes to definitions or relationships can be introduced deliberately and transparently, without forcing teams to rebuild queries or applications.
This design supports long-term maintainability rather than short-term structure.
A Foundation for Analytics and AI
Because semantics are explicit and governed, the knowledge graph acts as a stable interface for analytics and AI-driven systems. Analytical tools and AI models interact with consistent, trusted definitions rather than reconstructing meaning at query time.
This does not replace analytical engines or AI models. It provides them with reliable context to work from, reducing ambiguity and improving the quality of downstream results.
Summary
A knowledge graph organizes data by modeling real-world concepts and the relationships between them in a way that preserves meaning and context. What defines a knowledge graph is not whether data is stored as triples or tables, but whether semantics are explicit, governed, and reusable. Unlike traditional data models that reconstruct relationships through queries or application logic, knowledge graphs treat relationships as explicit, navigable parts of the model itself.
In enterprise environments, the challenge is not simply creating a graph structure – it is maintaining consistent identity, shared business definitions, valid relationships, and trust as data evolves across systems, teams, and use cases. Without explicit semantics and governance, knowledge graphs that work in controlled settings often break down in production.
These challenges become even more critical as organizations rely on analytics and AI systems that depend on accurate, well-defined context. When meaning is ambiguous or inconsistent, those systems amplify the same issues that undermine manual analysis. This is especially true for AI approaches such as GraphRAG, where retrieval quality and answer reliability depend directly on the structure and semantics of the underlying knowledge graph, regardless of how that graph is implemented.
Timbr approaches knowledge graphs by making semantics, governance, and consistency first-class concerns. By defining meaning explicitly, enforcing it at the model level, and designing for change, the knowledge graph remains a reliable foundation as data and usage scale.
If you want to see how knowledge graphs are defined, governed, and queried in practice, explore Timbr’s approach to semantic modeling.
