
What Is an Ontology-Based Data Model?
Definition, structure, and enterprise use cases
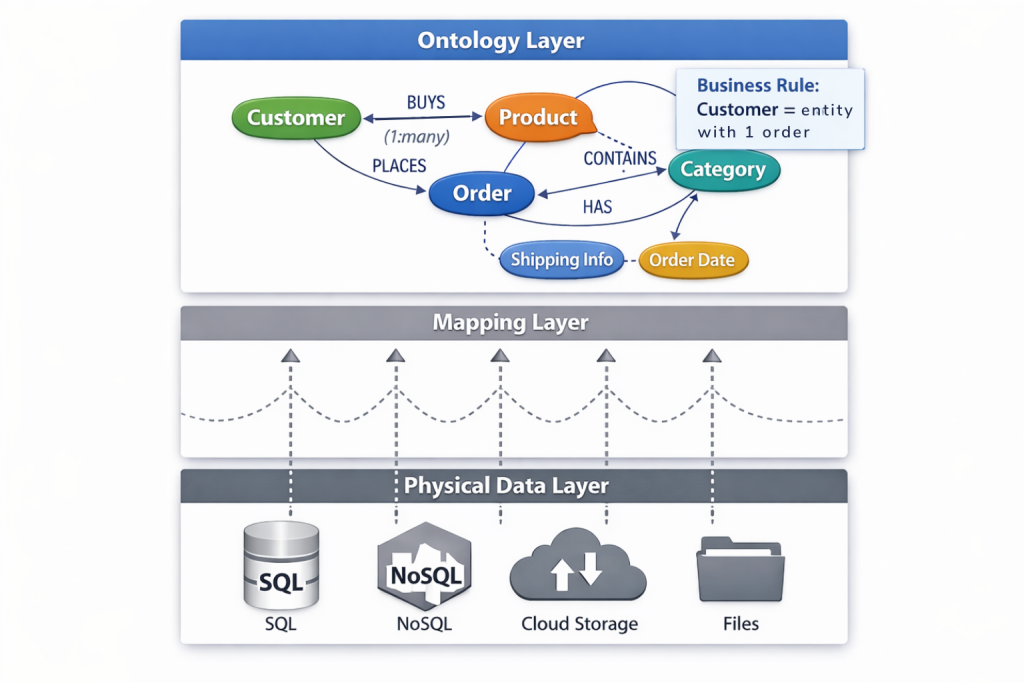
What Is an Ontology-Based Data Model?
An ontology-based data model represents data by defining business concepts, their relationships, and governing rules explicitly, rather than inferring meaning from table structures, column names, or application logic.
Instead of modeling data purely as tables, keys, and joins, ontology-based models describe what things are, how they relate, and under what conditions those relationships are valid. Concepts such as Customer, Order, Product, or Account are treated as first-class entities, with named relationships and constraints that reflect real-world business meaning.
Ontology-based data models sit above physical schemas. They do not replace databases, warehouses, or storage systems. Instead, they provide a semantic structure that translates raw data into a consistent, interpretable representation that can be reused across analytics, applications, and AI systems.
In practice, ontology-based data models form the structural foundation for semantic layers, knowledge graphs, and AI-driven data consumption. They define meaning once, explicitly, and allow that meaning to propagate consistently across tools and use cases as systems evolve.
An ontology defines meaning and structure. A knowledge graph is data organized, connected, and queried using that structure.
How Ontology-Based Data Models Work
Ontology-based data models separate business meaning from physical implementation. Rather than embedding logic in queries, pipelines, or dashboards, meaning is encoded directly into the model itself as defined concepts, relationships, and constraints.
This shift changes where decisions are made. Instead of reconstructing intent at query time, systems rely on shared, explicit definitions of concepts and relationships that are applied consistently everywhere the data is used.
Concepts as First-Class Business Entities
At the core of an ontology-based data model are concepts. A concept represents a business entity, not a table.
Examples include:
- Customer
- Order
- Invoice
- Product
- Account
A concept defines what something is, along with the attributes that describe it and the relationships it participates in. These attributes may map to columns in one or more underlying systems, but the concept itself exists independently of how data is stored.
This distinction becomes critical in real enterprise environments.
Consider a Customer entity. In most organizations, customer data is spread across multiple systems:
- A CRM system stores customer_id, contact details, and account status
- A billing platform uses account_number and payment history
- A support system references a support_user_id tied to tickets and interactions
Each system has its own schema, identifiers, and update cycles. Table-centric modeling treats these as separate entities that must be joined, reconciled, or duplicated. Analysts end up choosing which system is “authoritative” depending on the question, and logic proliferates as teams attempt to stitch together a unified view for each use case.
An ontology-based model defines Customer as a single concept and maps each system’s identifiers and attributes to that concept explicitly. The concept unifies these representations semantically without requiring schema consolidation or data duplication. Queries, analytics, and applications work with Customer as a business entity, not as a collection of loosely related tables.
This is the fundamental shift ontology-based models introduce. Data is organized around meaning, not storage.
Relationships Are Declared, Not Inferred
Traditional data models often infer relationships from foreign keys, naming conventions, or join logic embedded in queries, assuming that structural hints are sufficient to capture business meaning. Ontology-based models take a different approach.
Relationships are explicitly declared and named.
Examples include:
- Customer places Order
- Order billed to Customer
- Order shipped to Address
- Product belongs to Category
Each relationship carries semantic intent. It describes what the connection means, not just how two tables happen to be joined.
This matters when multiple relationships exist between the same entities. In schema-based models, ambiguity is resolved at query time, often inconsistently and differently across tools and teams. Ontology-based models treat each relationship as a distinct, intentional construct that can be governed, constrained, and reused.
As a result, systems no longer need to guess which relationship applies. The semantic intent is encoded directly in the model.
Constraints Encode Business Meaning
Ontology-based data models allow constraints to be defined as part of the model itself.
Constraints may express:
- Cardinality (one-to-one, one-to-many)
- Optionality (required vs optional relationships)
- Validity conditions
- Classification rules
- Access restrictions
These constraints are not merely validation checks. They determine which relationships, metrics, and interpretations are valid in specific business contexts. They encode business rules that determine when data is considered meaningful, valid, or usable in a given context.
For example, a relationship such as Order billed to Customer may be mandatory, while Order shipped to Address may be optional for digital goods. These distinctions affect analytics, reporting, and downstream logic, and they are enforced structurally rather than reimplemented procedurally in every query or tool.
By embedding constraints into the model, ontology-based systems enforce business meaning consistently across all consumers.
Ontologies as a Governed Vocabulary
An ontology functions as a governed vocabulary for the business.
- Concepts are defined in business terms
- Relationships are named and intentional
- Constraints express rules and boundaries
- Definitions are shared, versioned, and reusable
This vocabulary becomes the common language across teams, tools, and systems. When definitions change, they are updated once at the model level and propagate automatically, rather than being reimplemented repeatedly in downstream logic.
Because governance is embedded directly into the structure of the model, consistency is enforced by design rather than by process. This is what allows ontology-based models to scale in enterprise environments without fragmenting as systems, teams, and use cases multiply.
Ontology-Based Models vs Traditional Data Modeling Approaches
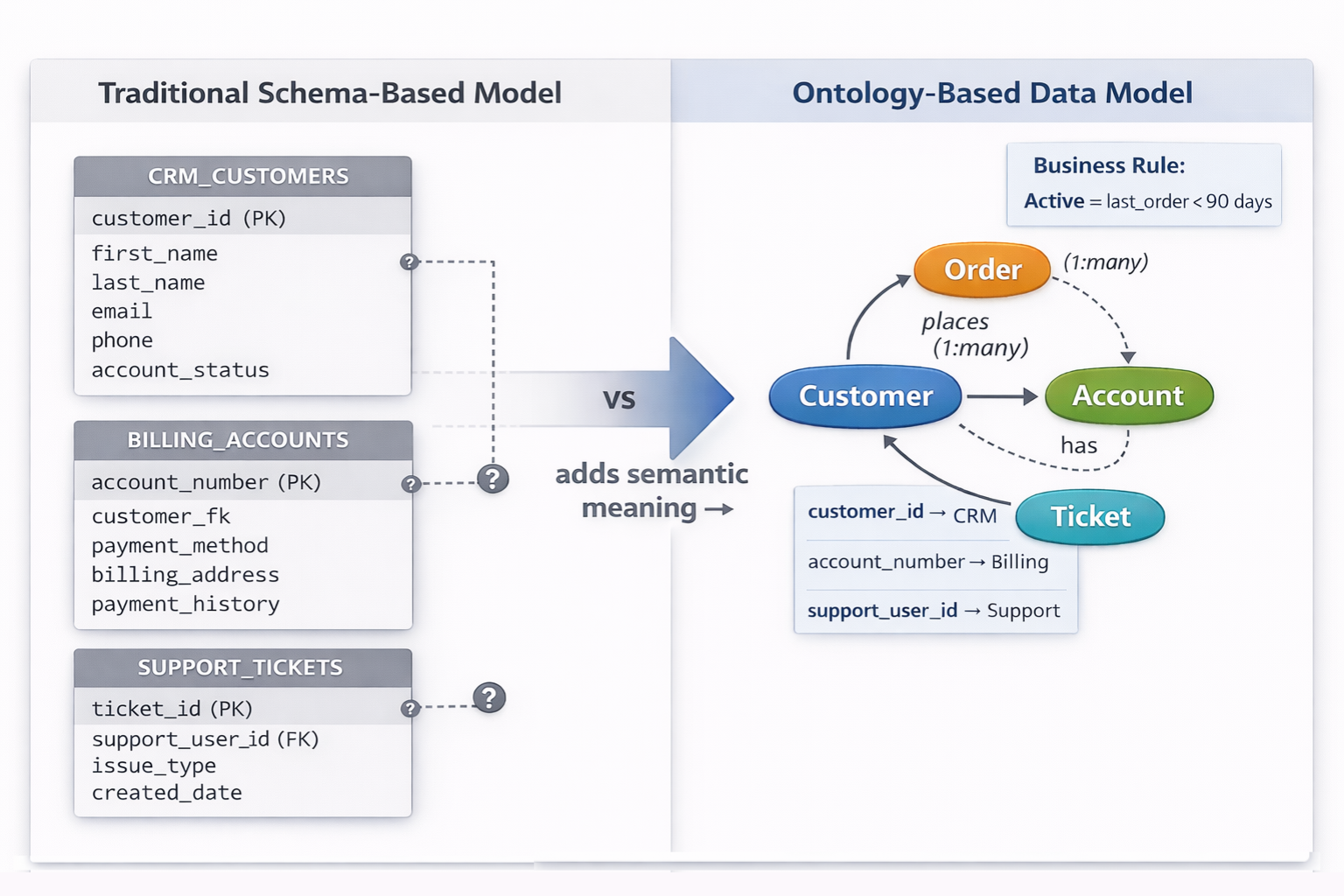
Ontology-based data models differ from traditional approaches not only in structure, but in intent. Traditional models are designed primarily to organize and store data efficiently. Ontology-based models are designed to represent business meaning explicitly and make that meaning reusable across systems, tools, and use cases.
This distinction becomes important as data environments grow more complex and consumption extends beyond reporting into applications and AI-driven workflows.
ERDs and Schema-Centric Models
Entity-relationship diagrams and relational schemas focus on how data is stored. They define tables, columns, and keys, and they excel at enforcing referential integrity, transactional consistency, and performance at the database level.
However, ERDs are not designed to express higher-level business semantics. In practice, they struggle to represent:
- Multiple semantic relationships between the same entities
- Business rules beyond structural constraints
- Hierarchies and inheritance
- Context-dependent meaning
As systems grow and data is reused across teams and tools, meaning must be reconstructed repeatedly in queries, views, and applications. The schema remains largely static, while interpretation fragments across consuming layers. Over time, this separation becomes a source of inconsistency rather than stability.
Views, Joins, and Query-Level Semantics
Many organizations attempt to layer meaning on top of schemas using views, joins, and calculated fields. This approach can work initially, particularly in smaller environments or when a single tool dominates data consumption.
Over time, however, semantics defined at the query level tend to fragment. Definitions implemented in views and calculated fields:
- Are duplicated across tools and teams
- Drift as requirements change
- Become difficult to govern centrally
- Break silently when underlying schemas evolve
Because these definitions live downstream, each consumer becomes responsible for maintaining its own interpretation of the data. As environments grow, this leads to inconsistent results and increasing maintenance overhead.
Ontology-based models move semantic definitions out of queries and into a shared structure that all consumers rely on, reducing duplication, drift, and long-term operational risk.
Metadata and Catalogs
Metadata catalogs document schemas, datasets, ownership, and lineage. They are valuable reference systems for discovery and governance, but they primarily describe data rather than define how that data should be interpreted or used.
Ontology-based data models are operational. They are used directly in querying, analytics, and AI workflows. Meaning is not just documented; it is enforced and executed consistently wherever the data is consumed.
Where Ontology-Based Models Matter in Enterprise Environments
Ontology-based data models become essential as data environments grow more complex. They matter most when organizations operate across multiple systems, domains, and use cases, and when business meaning must remain consistent despite constant change.
Multi-System, Multi-Domain Data
Enterprises rarely operate on a single system. Mergers, acquisitions, and departmental autonomy result in overlapping representations of the same business entities. Even without acquisitions, similar fragmentation emerges organically as teams adopt different SaaS platforms, build domain-specific systems, or optimize schemas for local needs.
Consider an organization that acquires a competitor. Both companies have customer databases, order systems, and product catalogs, but they are structured differently. The acquiring company uses numeric customer IDs and stores orders in a normalized schema. The acquired company uses alphanumeric account codes and maintains a denormalized order history table optimized for reporting.
Schema-centric integration forces a choice: migrate one system to match the other, maintain dual systems indefinitely, or build complex ETL pipelines that synchronize data between incompatible structures. Each option is expensive, fragile, and creates ongoing maintenance burden.
An ontology-based model defines Customer, Order, and Product as unified concepts that map to both systems without requiring schema changes or data migration. Analysts and applications work with the business concepts directly. The ontology handles the translation between physical representations transparently.
When a third acquisition occurs, the ontology extends to accommodate the new source without disrupting existing mappings or queries. Existing analytics, applications, and AI workflows continue to operate against the same business concepts, even as the underlying systems multiply.
Evolving Business Logic
Business definitions are not static. Revenue recognition rules change. New products are introduced. Regulatory requirements evolve.
Consider a financial services company facing new regulatory requirements that redefine how customer risk is classified. Previously, risk was calculated based on transaction volume alone. The new regulation requires incorporating account age, geographic factors, and relationship depth. The change is not optional, and inconsistencies across systems create both compliance risk and audit exposure.
When business logic is embedded in dashboards, reports, and pipelines, each downstream consumer must be identified and updated individually. Analysts update BI calculations. Engineers modify transformation models. Data scientists adjust feature pipelines. Verifying that every definition has been updated correctly becomes difficult, and small discrepancies can persist unnoticed across reports, models, and applications.
With an ontology-based model, the Customer Risk classification is defined once in the ontology. The new regulatory logic is implemented in the concept definition and constraint rules. All consuming systems inherit the updated definition automatically, and validation occurs at the model level rather than across dozens of downstream artifacts.
Governance Without Bottlenecks
Ontology-based models support governance by making rules explicit and enforceable, while reducing manual intervention.
Consider a healthcare organization enforcing patient privacy across analytics, operations, and research. Clinicians need full visibility. Researchers require anonymized data. Billing analysts need financial details without clinical context.
In schema-centric environments, these requirements are typically enforced through a combination of database-level policies, view logic, and manual controls in downstream tools. As new reports, extracts, and applications are created, access rules must be reimplemented repeatedly. Over time, inconsistencies emerge, and governance becomes a bottleneck rather than a safeguard.
An ontology-based model encodes these access rules directly into the Patient concept and its relationships. When users query the same concept, visibility is enforced automatically based on role and query context, regardless of which tool, report, or application is used.
Governance is enforced structurally, not procedurally.
What Breaks Without Ontology-Based Modeling
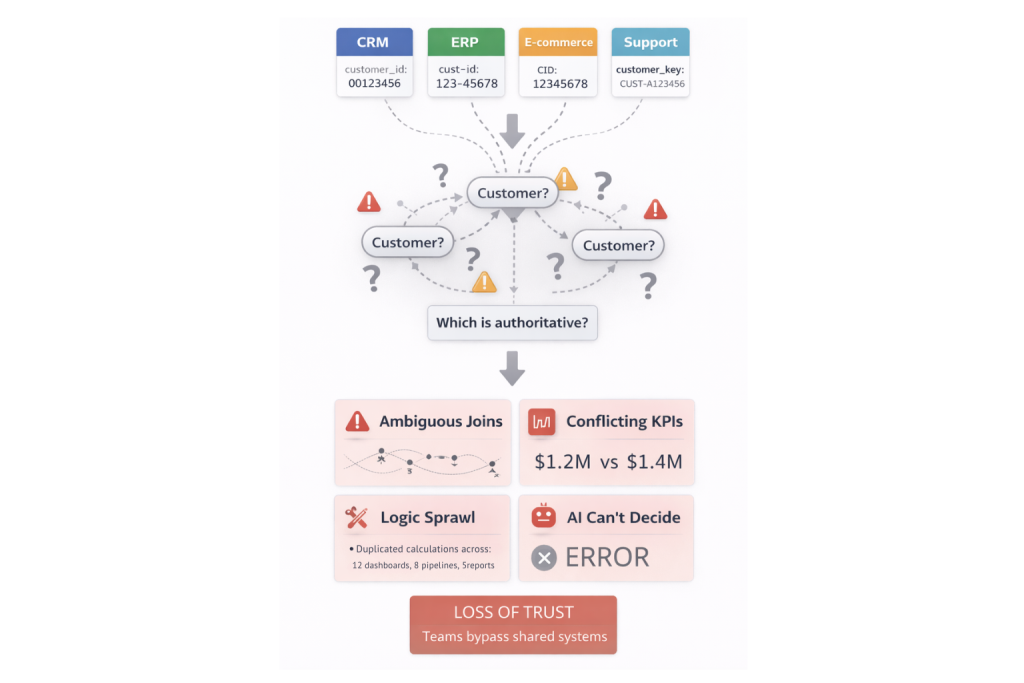
An organization extends its order schema to support more complex fulfillment. A single customer_id column is replaced with billing_customer_id and shipping_customer_id. Both reference the same customers table, but represent different business relationships.
Existing queries and views now contain ambiguous joins. Some default to billing customers. Others implicitly join shipping customers. Results change subtly and inconsistently.
The same KPI now differs across the executive dashboard, the finance close report, and the customer operations report, even though all three claim to measure the same thing.
Analysts add conditional logic in dashboards to patch discrepancies. Engineers encode assumptions in pipelines. When AI systems attempt to generate queries against this schema, they cannot determine which customer relationship to use without human intervention, forcing manual review or hard-coded overrides.
Trust erodes. Teams bypass shared models and return to custom SQL and data marts. The system still functions technically, but meaning has fragmented.
These failures are structural, not tool-related.
Enterprise Reality: Ontology Adoption in Practice
Ontology-based modeling is powerful, but it is not automatic.
It requires deliberate modeling decisions, alignment across stakeholders, and discipline around definitions. Organizations that treat ontologies as documentation rather than operational infrastructure fail to realize value. The ontology becomes a reference artifact that drifts from actual usage, creating confusion rather than clarity.
Partial adoption introduces fragmentation. When some teams rely on the ontology while others bypass it, the model cannot function as a single source of truth. Metrics diverge, definitions compete, and the benefits of shared semantics erode.
Over-modeling creates unnecessary rigidity. Attempting to capture every possible nuance upfront produces models that are difficult to evolve. Under-modeling recreates the same ambiguity ontology-based approaches are meant to eliminate. Effective adoption requires identifying which distinctions matter for decision-making and which can evolve over time.
Successful organizations treat semantics as infrastructure. Ontology changes are versioned, tested, reviewed, and governed with the same rigor as production systems. When this discipline is applied, ontology-based models become a stabilizing force rather than an additional layer of complexity, enabling consistency at scale without slowing the business.
Ontology-Based Models, Knowledge Graphs, and Semantic Layers
Ontology-based data models underpin many modern data architectures, providing the structural foundation that higher-level systems depend on.
Knowledge graphs use ontologies to define what nodes represent, how edges are named, and which hierarchies or classifications apply. The ontology determines which entities exist, how they relate, and what inferences are valid. Without an ontology, a graph is simply connected data without shared meaning.
Semantic layers rely on ontologies to stabilize definitions across tools and teams. Metrics, dimensions, and relationships remain consistent because the underlying concepts and relationships are explicitly modeled rather than inferred or reconstructed. When semantic layers lack an ontology-based foundation, definitions drift and fragmentation reappears.
AI retrieval and reasoning systems, including GraphRAG, depend on ontologies to supply structured, interpretable context. Ontologies allow AI systems to traverse relationships, apply constraints, and reason over meaning rather than relying on text similarity or schema guessing alone.
Without an ontology-based foundation, these systems rely on inference, heuristics, or repeated manual intervention to remain accurate. As scale and complexity increase, those approaches fail to sustain consistency or trust.
How Timbr Implements Ontology-Based Data Models
Identity Resolution Breaks Down
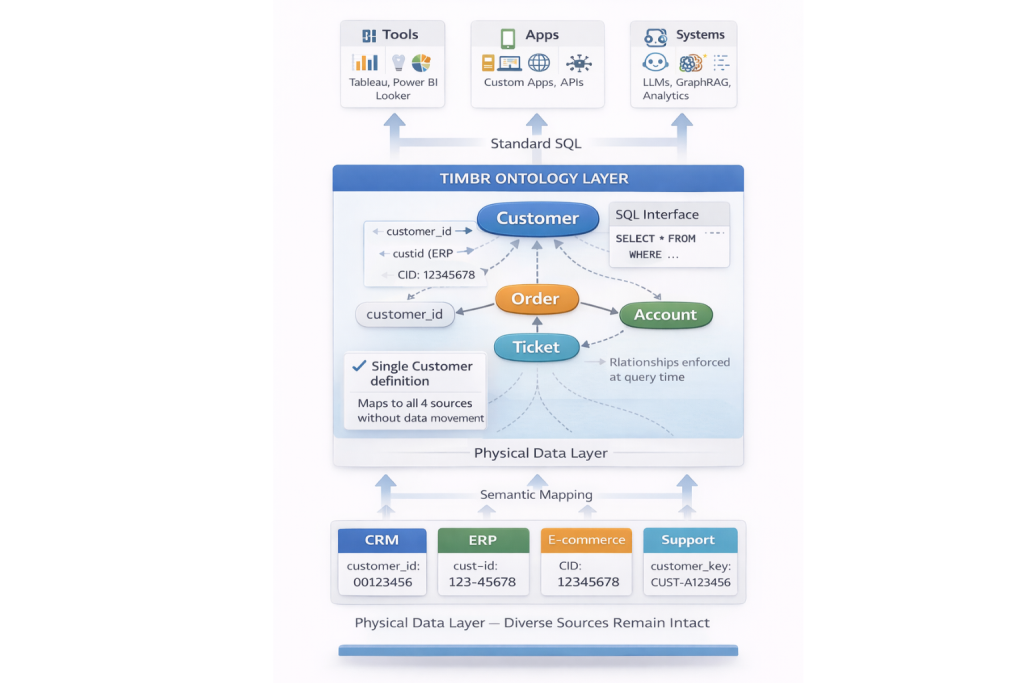
Timbr implements ontology-based data models as a SQL-native, executable semantic structure, where business meaning is not just described but directly enforced at query time.
Because metrics and measures are defined directly on top of these concepts and relationships, business logic remains consistent across analytics, applications, and AI systems without being reimplemented downstream.
Concepts, relationships, and constraints are defined explicitly in SQL and mapped to existing data sources without data movement or schema consolidation. Relationships are declared with intent rather than inferred from foreign keys or naming conventions, eliminating ambiguity across analytics, applications, and AI workflows.
Because the ontology itself is executable, it serves as the single place where business meaning is defined and enforced. When definitions change, those changes propagate automatically to every consuming system through the same semantic interface.
The ontology is exposed through standard SQL interfaces, allowing it to be reused consistently across BI tools, data science workflows, APIs, and AI systems without reimplementation or translation into tool-specific formats.
Summary
An ontology-based data model defines business meaning explicitly through concepts, relationships, and constraints. It separates semantics from physical storage, enabling consistency, reuse, and governance at scale.
In enterprise environments, ontology-based models provide the structural foundation required for semantic layers, knowledge graphs, and AI-driven data consumption. Without them, meaning fragments, logic drifts, and trust erodes.
This is why ontology-based data models are no longer optional as organizations scale into AI-enabled data systems, they are the only way to preserve shared meaning as data, tools, and consumers multiply.
If you want to see how ontology-based data models are created and managed in practice, explore Timbr’s approach to ontology modeling and executable semantic design.
