
- Databricks supports measures through ad-hoc SQL, Spark, and Delta Live Tables—but these can be complex and hard to manage at scale.
- Timbr offers a smarter approach with automatic semantic measure generation, measure composability, and a cost-performance optimized cache.
- This blog compares SQL-based aggregations in Databricks and Timbr measures
Introduction
Measures are pivotal for transforming raw data into actionable insights, enabling everything from financial forecasting to customer behavior analysis. The need for consistent, reusable, and performant measures is critical to align teams, reduce technical debt, and ensure trust in data. However, inconsistent metric definitions across departments can lead to duplicated efforts and eroded confidence.
Databricks provides robust, engineer-centric tools for date integration, optimized for flexibility and ML, while Timbr augments these with a semantic layer, automatic measure generation, and a four-tier cache tailored for business analytics.
The following comparison equips decision makers with insights to optimize their data platforms, balancing technical innovation with enterprise governance and AI-driven analytics
Understanding Measures and Their Role in Data-Driven Decision Making
Measures are quantitative metrics defined over data stores (e.g. SUM(sales), AVG(revenue), etc.) and serve as the foundation of analytics, reporting, and machine learning (ML).
Measures are essential for:
- Decision Making: Providing trusted KPIs for business planning.
- Consistency and Trust: Ensuring uniform metrics across teams to avoid discrepancies.
- Powering LLM Integration: Enabling Large Language Models (LLMs) to answer natural language queries (e.g., “What’s our total sales by region?”) when paired with semantic metadata.
Measures’ key challenges include:
- Inconsistent Definitions: Different teams defining “total sales” in conflicting ways, undermining trust.
- Scalability: Managing metrics across projects without duplication.
- Performance: Delivering low-latency queries for real-time analytics.
- AI Readiness: Preparing metrics for LLM-driven insights with rich metadata.
Databricks and Timbr address these challenges, but their approaches differ in automation, governance, and usability, impacting time to value and enterprise scalability.
How are Measures Created in Databricks?
Databricks offers a flexible, engineer-centric platform for measure creation, leveraging Apache Spark and Delta Lake. Measures are defined through SQL queries, Spark DataFrames, or Delta Live Tables (DLT), catering to data engineers, ML practitioners, and analysts. However, these methods often require technical expertise for setup and optimization.
1. SQL Queries and Views
The simplest approach is defining measures as SQL aggregations in Databricks SQL or notebooks. For example:
sql
SELECT SUM(quantity * price) AS total_sales_amount
FROM sales;
This can be saved as a view for reuse:
sql
CREATE VIEW total_sales_view AS
SELECT SUM(quantity * price) AS total_sales_amount
FROM sales;
2. Materialized Views
For improved performance, materialized views store precomputed results as Delta tables:
sql
CREATE MATERIALIZED VIEW total_sales_mv
AS SELECT SUM(quantity * price) AS total_sales_amount
FROM sales;
These are updated via DLT or manual refreshes, reducing query latency for dashboards.
3. Spark DataFrames
Programmatic measures are defined using Spark DataFrames in Python or Scala, offering flexibility for complex logic:
python
from pyspark.sql import SparkSession
spark = SparkSession.builder.appName("Measure").getOrCreate()
df = spark.table("sales")
total_sales_df = df.agg({"quantity * price": "sum"}).withColumnRenamed("sum(quantity * price)", "total_sales_amount")
total_sales_df.write.mode("overwrite").saveAsTable("total_sales_measure")
4. Delta Live Tables (DLT)
DLT enables real-time or incremental measure computation, ideal for streaming data:
sql
CREATE LIVE TABLE total_sales_measure
AS SELECT SUM(quantity * price) AS total_sales_amount
FROM LIVE.sales;
How Timbr Creates Measures on Databricks?
Timbr, a semantic layer integrated with Databricks, formalizes measures within an ontology, offering a business-friendly approach with automated features. Measures are created manually, automatically generated, or accessed programmatically, leveraging Databricks’ compute for execution.
1. Automatically Generated Measures
Timbr can automatically generate measures during ontology creation by inferring aggregations from data sources (e.g., Databricks Delta tables). For a sales_orders concept, Timbr might propose:
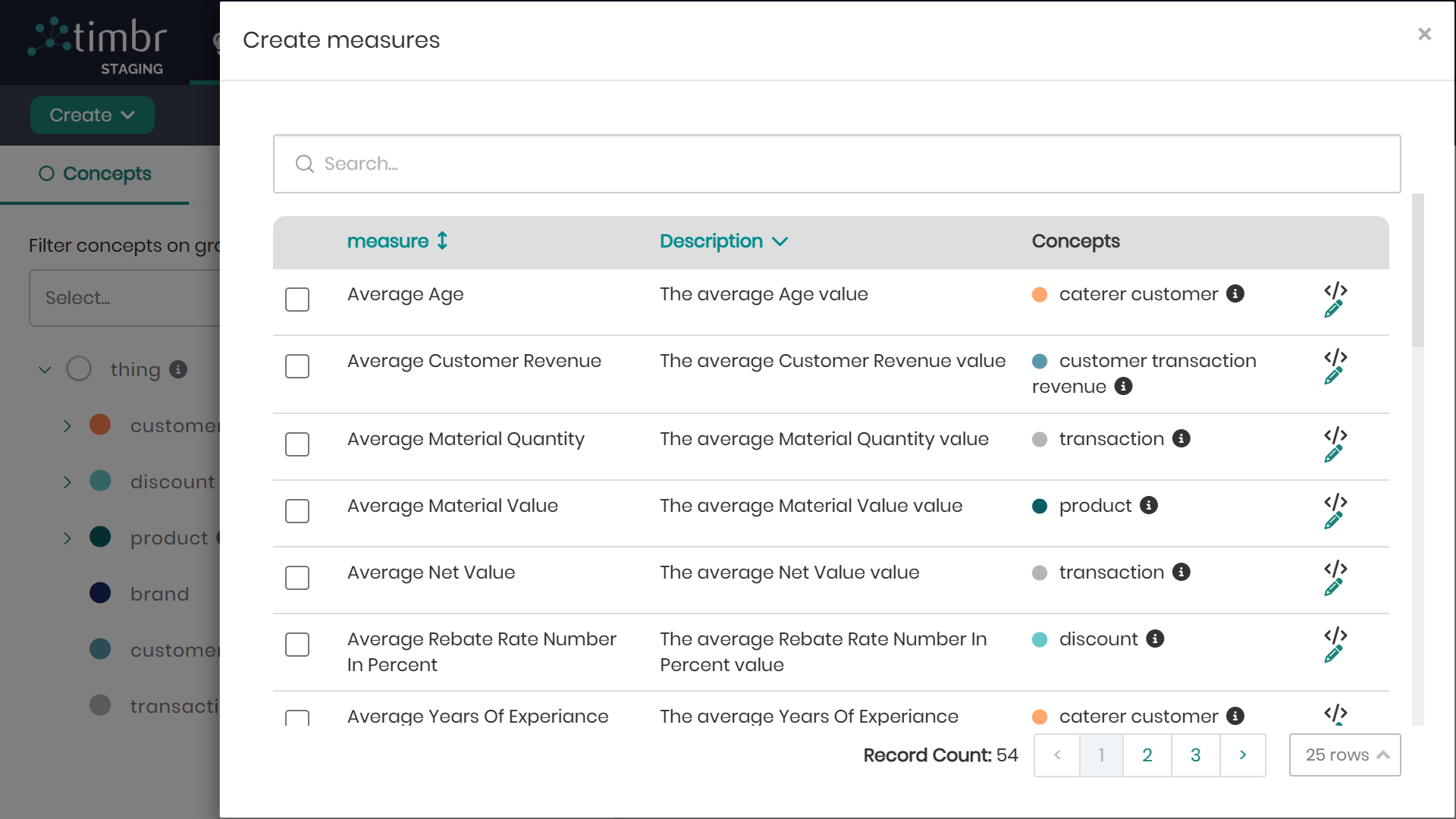
This automation, enabled through no-code or semi-automatic ontology generation, scans numeric columns to suggest measures like sums or counts, significantly reducing setup time.
2. Manual Measure Definition
Manual measures are defined using CREATE MEASURE:
sql
CREATE OR REPLACE MEASURE total_sales_amount DECIMAL(38,2)
AS SELECT SUM(quantity * price)
3. Programmatic Creation of Measures
Timbr supports JPype, JayDeBeAPI, SQLAlchemy, Spark, Python, R, Scala, and Java, enabling ML pipelines:
python
from sqlalchemy import create_engine
engine = create_engine("databricks://<host>:<port>/default?http_path=<path>&access_token=<token>")
result = engine.execute("SELECT total_sales_amount FROM dtimbr.sales_orders")
print(result.fetchall())
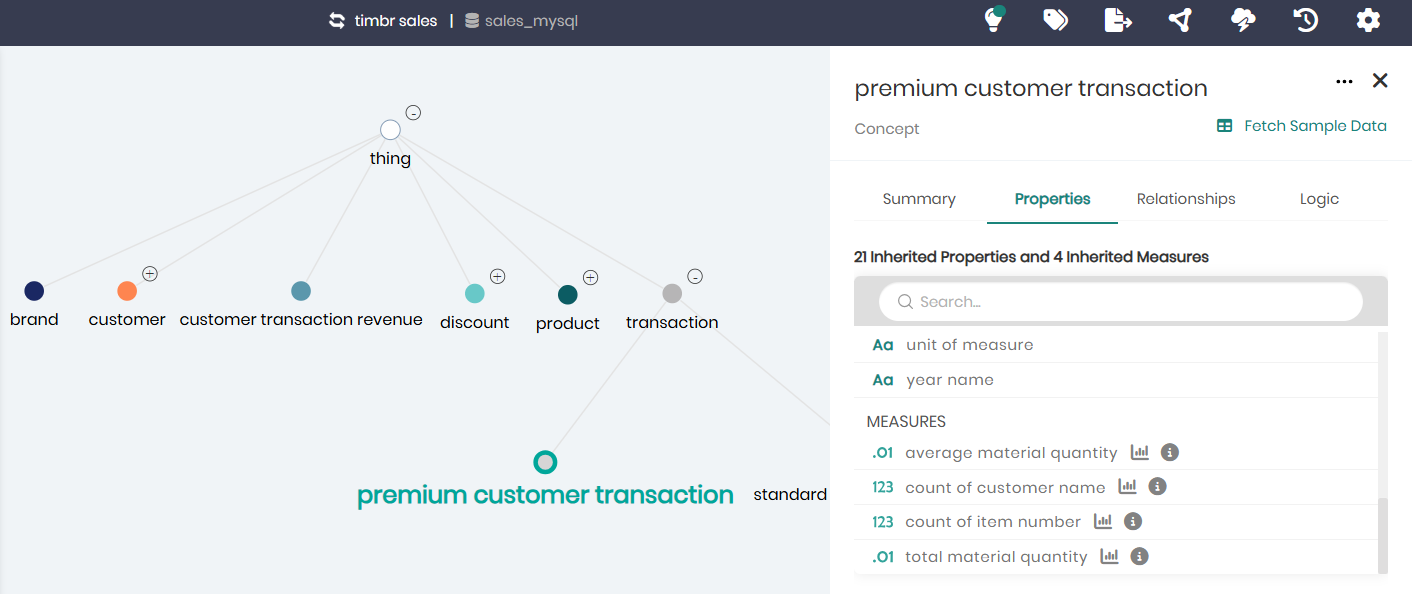
4. Measures inherited from top-level concepts:
Timbr’s ontology supports inheritance, allowing measures to be reused across concept hierarchies:
sql
CREATE OR REPLACE MEASURE total_instrument_value DECIMAL(38,2)
AS SELECT SUM(value)
CREATE OR REPLACE CONCEPT security INHERITS (financial_instrument);
SELECT SUM(`measure.total_instrument_value`) FROM dtimbr.security;
How Databricks and Timbr Optimize Measures Performance?
Databricks Measures Performance
For performance optimization, Databricks relies on manual optimization through user-controlled techniques:
- Decision Making: Providing trusted KPIs for business planning.
- Materialized Views: Precompute results for low latency.
- Delta Lake Caching: Stores data in memory/disk.
- Query Result Caching: Temporary caching in SQL endpoints.
- Z-Order Indexing: Optimizes data access:
- Adaptive Query Execution (AQE): Dynamically optimizes query plans.
- Photon Engine: Vectorized execution accelerates SQL workloads.
Strengths: Transparent, configurable, supports streaming via DLT.
Weaknesses: No pre-aggregations, and manual indexing requires expertise, increasing operational overhead.
Timbr Measures Performance
Timbr automates performance with its four-tier cache (DB, Datalake, SSD, In-memory) and query optimizations :
- Query Optimization: Intelligent routing and rewriting enhance efficiency .
- Cache Invalidation: Supports incremental update based on table refreshness
Strengths: Automated, reduces compute costs for repetitive queries, business-friendly.
Weaknesses: Requires approval – human in the loop.
Performance Comparison
Timbr’s automated four-tier cache excels for repetitive queries (e.g., dashboards), delivering instant results without user intervention. Databricks’ manual optimizations provide control and flexibility, ideal for streaming or ad-hoc workloads, but demand setup and expertise.
Using Databricks and Timbr Measures to Power LLMs
Databricks integrates with LLMs via SQL endpoints but lacks semantic context, limiting query accuracy. Timbr enhances LLM performance with semantic metadata, enabling precise natural language queries.
While Databricks offers ML and streaming strengths, Timbr stands out for automated, reusable measures and an LLM-ready semantic layer that simplifies query generation and boosts business user accessibility.
Governance and Scalability Considerations
Databricks Measures Governance and Scalability
Governance is managed via Unity Catalog, offering metadata, access control, and lineage. Measures, as tables or views, lack semantic context, leading to ad-hoc governance. Scalability requires manual reuse across projects, risking inconsistencies and duplication.
Timbr Measures Governance and Scalability
Measures are governed entities within the ontology, enriched with business rules and relationships . Integration with Unity Catalog ensures enterprise-grade governance. Scalability is enhanced by inheritance and automatic measure generation, enabling reuse across departments. Auditable lineage via the ontology ensures trust and compliance.
Governance and Scalability Comparison
Timbr’s semantic governance and reusability minimize duplication and ensure consistency, while Databricks’ external governance is less integrated, posing challenges for enterprise-wide alignment.
In Summary, how Databricks’ SQL Aggregations and Timbr Measures on Databricks Compare?
Databricks provides engineers with flexibility through various methods to define and manage metrics, including SQL, Spark, and Delta Live Tables (DLT). In contrast, Timbr simplifies this process by unifying metric creation through a single CREATE MEASURE syntax and automatically generating derived metrics, reducing complexity and setup time. This streamlined approach makes Timbr more accessible for data teams seeking efficiency without sacrificing capability.
Timbr also stands out in terms of reusability and semantic simplicity. Its inheritance model allows metrics and logic to be reused across the data model, minimizing duplication. In comparison, Databricks often requires engineers to manually replicate definitions across contexts. Moreover, Timbr’s ontology-based semantic layer enables users to write no-join queries that are easy for business users to understand, while Databricks users must manually handle joins and relationships.
While both platforms support Python and Spark for programmatic and machine learning access, Databricks shines in low-level ML customization, whereas Timbr adds value with higher-level, semantic ML pipelines that leverage the graph structure and ontology-driven design.
Comparison Table
| Criteria | Databricks | Timbr |
|---|---|---|
| Definition | Aggregated metrics via SQL, Spark, DLT, or materialized views. | Formal objects via CREATE MEASURE or CREATE CUBE |
| Automatic Generation | None; manual definition required. | Yes; infers measures during ontology creation. |
| Storage | Queries, views, or Delta tables in Unity Catalog/Delta Lake. | Four-tier cache - DB, Datalake, SSD, In-memory |
| Execution | Spark engine via Databricks SQL/notebooks. | Translated to Databricks SQL, executed with four-tier cache. |
| Inheritance Support | None; separate measures per table. | Native via INHERITS for concept hierarchies. |
| Semantic Layer | None; Unity Catalog for governance. | Ontology with concepts, relationships, no-join queries. |
| Query Simplicity | Manual joins (e.g., sales JOIN products). | No-join queries via virtual columns in dtimbr schema |
| Reusability | Moderate; views/tables, manual setup. | High; reusable via inheritance. |
| UI Support | Databricks SQL Analytics for queries, dashboards. | Timbr UI for no-code measure creation, ontology management. |
| Integration with BI Tools | Strong; SQL endpoints (Tableau, Power BI). | Strong, native OLAP on timbr cubes (vtimbr) or dtimbr concepts |
| Integration with LLMs | Exposed via SQL endpoints with limited accuracy due to lack of semantic context. | Exposed via OpenAPI or LangChain/LangGraph SDK, ontology enables accurate LLM queries. |
| Performance Optimization | Materialized views, Delta Lake caching, Z-order, AQE, Photon; manual. | Four-tier cache, query optimization; automated and manually configurable. |
| Governance | Unity Catalog for metadata, access control, lineage. | Ontology + Unity Catalog for semantic governance, access control, lineage. |
| Use Case | Ad-hoc analysis, streaming, custom ML, engineering workflows. | Business analytics, ML pipelines, complex data. |
| Learning Curve | Moderate to high; SQL, Spark, DLT knowledge. | Moderate; Timbr SQL, ontology concepts. |
| Extensibility | High; Spark, Python, Scala for custom logic, ML. | High; Spark, Python, Scala for custom logic, ML. |
Conclusion
Timbr serves as an accelerator for semantic consistency and metric trust, reducing technical debt through automated measure generation and inheritance. Its no-code UI and simplified queries foster collaboration between business and technical teams, bridging the gap between data producers and consumers. The ontology lays a foundation for AI/LLM-readiness, enabling natural language queries that enhance decision-making.
In contrast, Databricks’ flexibility supports technical innovation but risks metric silos without a semantic layer, increasing governance overhead. By adopting Timbr, enterprises can streamline analytics, reduce duplication, and prepare for AI-driven insights, aligning with strategic goals for scalability and trust.
For CIOs and CDOs, the choice between Databricks and Timbr for measure creation depends on balancing technical flexibility with enterprise governance and AI readiness. Databricks excels in streaming, ML, and custom workflows but requires manual effort, risking inconsistencies without a semantic layer. Timbr’s semantic ontology, automatic measure generation, and four-tier cache deliver rapid time to value, consistent metrics, and LLM-ready analytics, making it a strategic accelerator for business-driven enterprises.
By integrating Timbr with Databricks, you can empower both technical and business teams, reduce technical debt, and build a future-proof data stack that drives trusted, AI-enhanced decisions.
