
Introduction
Large Language Models (LLMs) like GPT-4, Claude, and Gemini are transforming how enterprises interact with data. Teams increasingly expect to ask natural language questions and receive precise, SQL-powered answers from their enterprise data. But there’s a problem: traditional databases and semantic models lack the structure and context needed to reliably translate natural language into SQL.
That’s where Timbr comes in.
By combining the expressive power of ontologies with native SQL modeling, Timbr provides the structure and context LLMs need to generate accurate, context-aware queries. This makes Timbr’s ontology-based knowledge graph the foundation for enterprise-grade NL2SQL applications.
The Rise of LLMs and the NL2SQL Challenge
The idea of querying data with natural language has existed for years. But the recent rise of LLMs has brought this concept into real-world applications, from chatbots for data exploration to executive dashboards that respond to typed questions.
However, most enterprises quickly run into problems:
- Ambiguous queries: Users often phrase questions in imprecise ways.
- Missing structure: LLMs don’t inherently know how business data is modeled.
- Hallucinations: Without context, LLMs may invent joins, filters, or logic that don’t exist.
Basic NL2SQL solutions rely on string matching, templates, or rigid prompt engineering. But they fail to scale across diverse schemas and real-world questions. What’s needed is a deeper semantic foundation.
Why Traditional Semantic Layers and Knowledge Graphs Fall Short
Many organizations already use semantic layers like dbt metrics, LookML, or BI dashboards to provide curated data definitions. These layers can work reasonably well with LLMs, provided the data stores are static and the queries don’t require complex JOINs, but they present several limitations:
- Focused on visualizations, not language understanding.
- Lack relationships between business concepts.
- Not designed to provide logical context for LLMs.
SPARQL-queried OWL knowledge graphs require storing data in RDF format. However, they are not SQL-native and are often incompatible with enterprise data tools. Worse, they require translating from SPARQL to SQL, which adds complexity and reduces accuracy.
What about newer, AI-native approaches? Many of these solutions bolt LLMs onto traditional schemas without a semantic layer. While they may work for narrow use cases, they often lack scalability, governance, and reliability in complex enterprise environments. Unlike retrieval-augmented generation (RAG) systems that rely on embeddings and prompt engineering, and often hallucinate schema relationships, Timbr grounds LLMs directly in a governed SQL ontology. This eliminates ambiguity and ensures precise data access.
What Makes NL2SQL Work Well
To support natural language queries that reliably translate into SQL, LLMs need more than just column names and table schemas. They need:
- A semantic model of the business: clear concept definitions, hierarchies, and annotations.
- A graph of relationships: how entities like “Customer”, “Order”, and “Region” connect.
- A native SQL foundation: the model must align with how data is actually stored and queried.
This combination allows LLMs to understand what users mean, not just what they say, and generate correct SQL as a result.
For example, when a user asks, “What were our top performing regions last quarter?” the ontology helps the LLM recognize:
- “regions” refers to a specific hierarchy (e.g., geography > region > country).
- “last quarter” needs to resolve dynamically based on today’s date.
- “top performing” likely maps to a KPI like revenue, sales, or profit.
These insights lead to accurate, dynamic SQL with no guesswork.
How Ontology-Based Knowledge Graphs Solve This
The power of this approach becomes clearer when visualized. Below is a real example of a Timbr ontology-based knowledge graph, where business concepts like customer, order, and shipment are connected through meaningful relationships and governed by constraints.
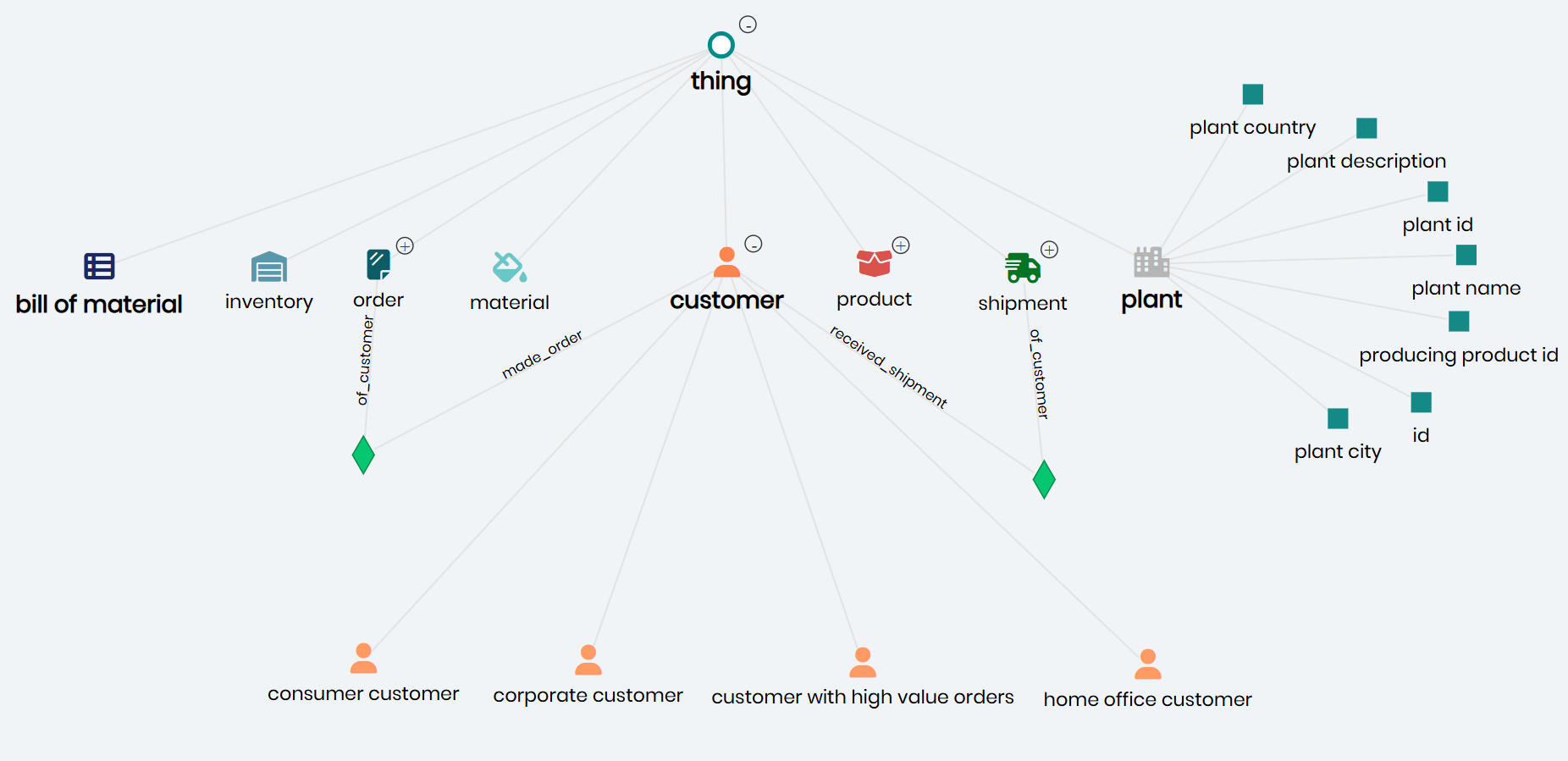
Timbr’s semantic layer models enterprise data as SQL-native ontologies, with each concept representing a business entity. These concepts are enriched with metadata, relationships, properties, and inheritance logic, all directly queryable in SQL. Unlike abstract RDF graphs, Timbr’s knowledge graph is designed for operational use, enabling immediate, context-aware query generation.
This matters because:
- LLMs are widely trained on SQL, but much less on SPARQL.
- Ontology relationships guide the LLM to connect the right entities.
- Constraints (e.g., primary keys, inheritance, filters) add context to improve query accuracy.
By providing this rich, machine-readable context, Timbr helps LLMs move from experimentation to enterprise-grade performance.
Timbr’s NL2SQL Stack: LangChain and LangGraph SDKs
Timbr offers two SDKs designed specifically for integrating LLMs with its ontology:
LangChain SDK
This SDK allows developers to plug in any LLM (OpenAI, Claude, Gemini, LLaMA, etc.) and query the Timbr ontology using natural language. Key features:
- Multi-LLM Support: Choose the right model for the task.
- SQL Generation: Automatically generate Timbr SQL enriched with relationships.
- Ontology Access: Pull semantic context directly into the LLM prompt.
- Streamlined Querying: Works with tools like run_llm_query to combine NL and SQL.
LangGraph SDK
For more advanced workflows, the LangGraph SDK enables step-by-step orchestration of multi-turn interactions. Key features:
- Concept Identification: Extracts the correct ontology concept and schema from the query.
- Contextual SQL Generation: Returns the correct SQL aligned with the concept structure.
These SDKs provide a seamless pipeline from user intent to accurate query results.
Together, they allow developers to go beyond simple prompts, enabling powerful workflows such as chat-based analytics, intelligent agents, and dynamic dashboards that speak the language of the business.
Why Enterprise Teams Choose Timbr for Production NL2SQL
Why does this matter in real-world enterprise settings? Because organizations need:
- Precision: Avoid hallucinated or incorrect results.
- Speed: Deliver answers without engineering bottlenecks.
- Governance: Know what data is being accessed and how.
- Scale: Handle thousands of queries across complex data models.

Timbr’s NL2SQL capabilities deliver on these needs by combining:
- SQL-native ontology models.
- SDK for integration with enterprise LLMs and data tools.
Customers using Timbr report accurate answers out of the box (when best modeling practices are followed), compared to alternative LLM-powered NL2SQL solutions. They also experience faster time from implementation to insight, enabling analysts to answer sets of questions that previously took weeks, now in days.

Want to Learn More?
Book a demo to see Timbr in action powering accurate NL2SQL.
Or, get started with a free POC*
*Free POC available for qualified enterprise organizations.
