
- Timbr’s GraphRAG SDK lets developers build advanced RAG workflows using structured SQL-based retrieval, without needing a graph database.
- Unlike traditional RAG, GraphRAG leverages Timbr’s ontology to follow relationships, extract structured facts, and provide accurate, explainable results.
- This blog explores how GraphRAG unifies SQL and vector search to answer questions using both structured data and unstructured text.
Introduction
Timbr GraphRAG brings the power of knowledge graphs to Retrieval-Augmented Generation (RAG), enabling large language models (LLMs) to retrieve and reason over both structured and unstructured enterprise data. By connecting your LLM of choice to Timbr, GraphRAG delivers accurate, context-aware answers grounded in your organization’s knowledge.
For those unfamiliar with Timbr, the platform delivers an ontology-based semantic layer that unifies and virtualizes data across sources into a SQL-accessible knowledge graph. This makes enterprise data easier to query, understand, and consume, especially in AI-driven workflows.
We’re excited to announce the release of the Timbr GraphRAG SDK, a developer toolkit that brings the power of knowledge graphs to RAG applications. Built on the foundation of Timbr GraphRAG, this SDK makes it easy for developers and data engineers to build RAG pipelines that produce high-accuracy, explainable outputs, without sacrificing flexibility or ease of use.
What is GraphRAG and Why It Matters
GraphRAG (Graph-based Retrieval-Augmented Generation) is an emerging approach that enhances traditional RAG by combining graph-powered structured data retrieval with vector-based unstructured data search. In a standard RAG setup, an LLM answers questions by retrieving text snippets (via vector similarity) from documents. This works for many cases but struggles with complex queries that require connecting facts or reasoning over structured data. Baseline RAG systems often “struggle to connect the dots” between disparate information pieces and to understand holistic concepts across large documents.
GraphRAG addresses these limitations by incorporating a knowledge graph: it leverages explicit relationships between entities and facts, so the AI can traverse and reason through data like a human expert.
By uniting a knowledge graph with traditional vector search, GraphRAG provides richer context and more precise answers. Instead of relying solely on semantic text similarity, the system can also query structured databases or ontologies to fetch exact facts (e.g. totals, relationships, hierarchies).
This dual approach leads to answers that span both the explicit relationships in structured data and the implicit insights from unstructured text. In practical terms, GraphRAG can answer complex questions that mix data and context, for example, “Which product line had the highest sales last quarter and what were customers saying about it in reviews?”
A GraphRAG system could break this into a structured query to find the sales leader, and a semantic search to gather relevant customer feedback, then synthesize a comprehensive answer. The result is greater accuracy, relevance, and explainability in AI responses especially in enterprise scenarios where both databases and documents hold crucial information.
GraphRAG Use Cases
GraphRAG is important wherever critical knowledge is spread between structured and unstructured data. Data engineers and decision-makers can use it to unlock insights that pure text-based AI misses.
For instance, in customer support, GraphRAG can combine a customer’s profile and transaction history (structured data) with support tickets or knowledge base articles (unstructured text) to answer customer queries with full context.
In healthcare or finance, it could correlate database records with policy documents or research papers to support complex decision making.
Even in IT operations, as Microsoft researchers note, GraphRAG enables context-rich reasoning by fusing structured graphs of system data with unstructured logs and guides, yielding more precise diagnoses and recommendations.
Across industries, this structured + unstructured approach helps AI “connect symptoms, causes, and resolutions” with greater precision – a leap forward in trustworthy AI-assisted analytics.
What makes Timbr’s GraphRAG special?
In traditional RAG, the LLM might retrieve raw text and attempt to infer structured facts, which can be error-prone. Leveraging Timbr ontologies, the LLM can directly query governed, structured data (through SQL queries and metrics powered by semantic relationships that replace JOINs and UNION commands) to get exact answers from single source of truth tables.
In other words, the Timbr GraphRAG SDK delivers context-rich RAG that draws from governed metrics and concepts, not just raw text. Your enterprise knowledge (sales figures, customer data, inventory, etc.) is exposed to the AI in a meaningful way, drastically improving accuracy and relevance. Because the semantic layer understands business definitions and relationships, the AI is far less likely to hallucinate or misinterpret terms, it knows, for example, what “premium customer” or “Q1 gross margin” specifically means in your data model, and can retrieve the correct numbers and related info accordingly.
In short, Timbr GraphRAG offers a ready-to-use foundation for building graph-enhanced AI agents that reason over and respond with deep context from your enterprise data.
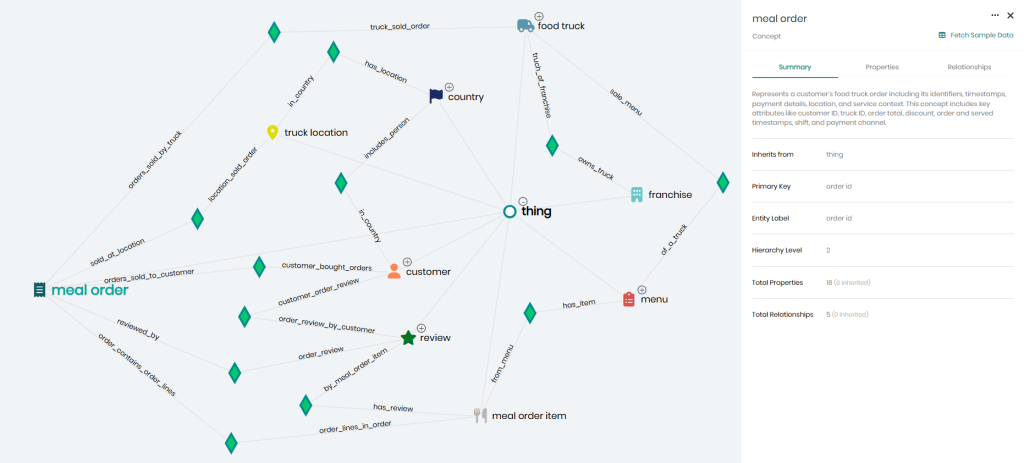
Ontology view of semantic relationships in Timbr, showing how entities like orders, customers, and food trucks are linked through business logic for context-aware querying.
Unique Capabilities and Benefits
Timbr’s implementation of GraphRAG offers several unique
capabilities that set it apart from DIY approaches or baseline RAG solutions:
Ontology-Driven Knowledge Graph
Timbr allows you to create a
virtual knowledge graph over existing data sources with minimal effort. The
ontology captures your domain’s concepts and relationships (e.g. customers,
products, transactions) directly on top of your SQL tables.
Benefit: No complex ETL or graph database needed –
you leverage your current warehouse with an intelligent semantic layer,
ensuring data consistency and real-time access to facts.
Integrated Structured + Unstructured Querying
The GraphRAG SDK intelligently
routes queries to the appropriate system. Structured questions (e.g. “total
sales by region”) are answered via Timbr’s graph-powered SQL queries on your
warehouse, while unstructured or open-ended questions (e.g. “what are customers
saying about product X?”) are handled via vector search on documents. For
hybrid questions, both paths are used and results are fused.
Benefit: Users get comprehensive answers that might
include exact figures and supporting context from text, all in one go.
Higher Accuracy and Contextual Precision
By leveraging a knowledge graph,
the SDK can draw on explicit relationships and constraints in your data. This
yields more precise answers than using embeddings alone. For example, instead
of guessing how two pieces of info relate, the system “knows” the link (through
the ontology). GraphRAG with Timbr has the context to “traverse disparate
pieces of information through their shared attributes”, solving questions
baseline RAG would miss.
Benefit: More accurate, explainable AI – the answers
are grounded in both your database and documents, reducing hallucinations and
improving trust.
Semantic Query Understanding
Timbr’s semantic layer stores
business definitions, hierarchies and metrics. The SDK leverages this for
natural language understanding. An LLM using Timbr can recognize that “top
three regions” refers to a rank ordering of a region entity by a revenue measure,
for instance, and Timbr provides the logic to get that.
Benefit: Business-friendly AI that understands your
terminology and can translate user questions into correct queries. This
significantly shortens development of AI assistants that speak the language of
your business.
Faster Development & Scaling
Because Timbr GraphRAG builds on
SQL and cloud data warehouses, it scales with your existing infrastructure.
Developers familiar with SQL can adopt it easily. The SDK’s reference
implementation (with Streamlit UI, example data, and step-by-step docs) means
you can prototype quickly.
Benefit: Reduced time-to-value – data engineers can
stand up a graph-augmented QA system without needing specialized graph
programming skills. Plus, all data stays in your secure environment (no need to
export data to external vector stores or graph DBs), which is a big win for
enterprise governance.
GraphRAG with vs. without Timbr: A Comparison
To highlight the difference Timbr makes, here’s a quick comparison of building a GraphRAG solution the “traditional” way versus using the Timbr GraphRAG SDK:
| Aspect | Without Timbr (DIY GraphRAG) | With Timbr GraphRAG |
|---|---|---|
| Knowledge Graph Setup | Must manually design and build a knowledge graph (often migrating data into a graph database or writing custom ontology code). High effort and requires graph expertise. | Ontology is auto-created or defined via Timbr’s tools on top of your existing DB. Low effort: your relational schema is quickly mapped to a virtual knowledge graph. |
| Data Integration | Hard to unify multiple sources – data may reside in silos. Likely need complex ETL to combine structured and unstructured data for AI. | Virtual integration: Timbr connects to many data sources (Snowflake, BigQuery, etc.) natively. Structured and unstructured data remain where they are, but are queried together through the semantic layer. |
| Querying Structured Info | LLM must rely on vector search or brittle templates to retrieve structured facts (e.g., totals, counts). Potential for errors or stale data if using extracted text. | LLM can execute live SQL on the data via Timbr’s semantic layer. Structured queries are answered with exact values from the source (no hallucination). Timbr’s relationships replace complex JOINs, simplifying query logic. |
| Unstructured Data Access | Need to set up a separate vector database or service and custom code to combine results with structured data answers. Merging answers is non-trivial. | Built-in integration: Timbr SDK works with Snowflake Cortex or similar vector search seamlessly. The workflow already handles combining graph query results with document search results for you. |
| Accuracy & Context | Risk of incomplete context – purely embedding-based RAG might miss relational context, and custom graphs may not stay in sync with source data. | Rich context from knowledge graph + documents. GraphRAG with Timbr understands entity relationships (for higher precision) and always queries the latest data in the warehouse. More transparent and up-to-date answers. |
| Development Effort | High: requires stitching together graph DB, vector search, LLM orchestration, plus ensuring they work in concert. Each component is maintained separately. | Lower: provided as an SDK with reference app and utilities. You focus on defining your ontology and plugging in credentials. Timbr handles the heavy lifting of graph query translation and data orchestration in one coherent framework. |
Introducing the Timbr GraphRAG SDK
The Timbr GraphRAG SDK is our implementation of the GraphRAG paradigm, designed to make it easy for enterprises to build GenAI applications that truly understand your data. Timbr’s unique semantic layer brings ontology intelligence to RAG workflows. In practical terms, the SDK allows you to plug in your existing cloud data warehouses (e.g. Snowflake, Databricks, Microsoft Fabric, etc.) and documents, and effortlessly overlay an ontology-driven knowledge graph via Timbr.
By unifying and virtualizing data across sources into a queryable graph, Timbr turns scattered tables into a rich knowledge graph without relocating your data. This means your LLM can now treat databases and documents as one cohesive information source.
How the Timbr GraphRAG SDK Works (Example)
To illustrate how GraphRAG comes to life, let’s walk through the example provided in the SDK. We built a demo (using Snowflake’s Tasty Bytes sample dataset – a fictional food truck company) that showcases Timbr GraphRAG in action. In this scenario, structured data about food trucks, customers, orders, etc., lives in Snowflake as tables, and we’ve added unstructured data in the form of customer review PDFs. The goal is to allow natural language questions to be answered using both the structured database and the unstructured reviews, where appropriate.
At a high level, here’s how the Timbr GraphRAG workflow operates:
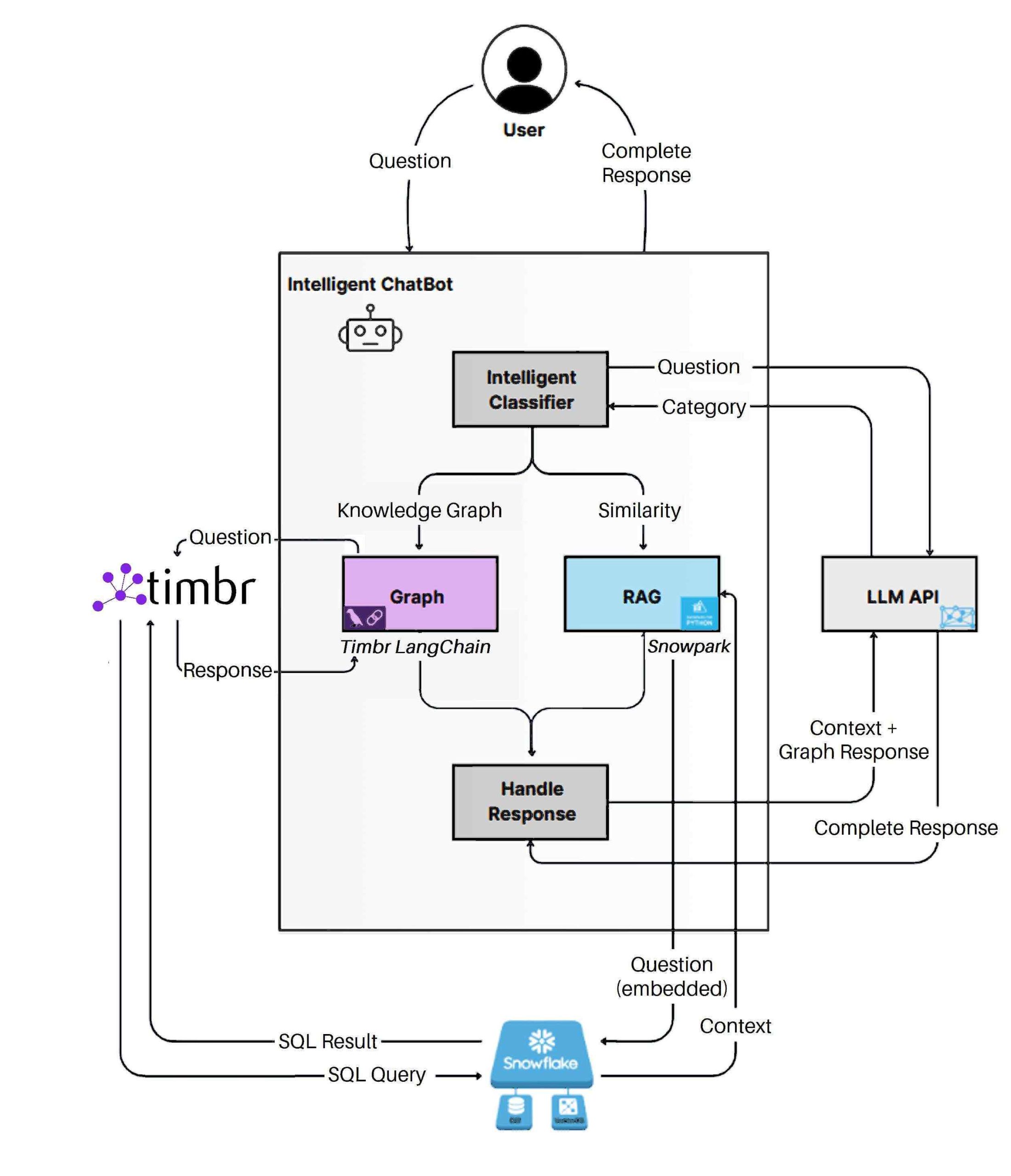
Timbr GraphRAG SDK sample architecture.
- Question Understanding & Routing: When a user asks a question in the demo app, an LLM first classifies the query type. Is the question about a structured fact (e.g. “How many orders were placed in 2022?”), unstructured content (e.g. “Any negative feedback about our salads?”), or a combination (“Which truck has the most orders and what do reviews say about it?”)? This intelligent routing step uses a model (GPT-4 in our example) to decide the path.
- Structured Query Path: For questions requiring structured data, Timbr’s engine converts the natural language question into an optimized graph query. Under the hood, Timbr translates this to SQL and runs it on Snowflake (or your connected database). Because the Timbr ontology understands the data model, the query can use semantic relationships rather than complex SQL joins. The result might be a precise table of answers. For instance, “What is the make and model of the electric food truck with the most orders in 2022, and how many orders did it have?” would be answered by querying the knowledge graph for truck order counts and returning the top result with its details (all via SQL on live data).
- Unstructured Query Path: For questions seeking information from text (like customer opinions, reviews, etc.), the SDK uses Snowflake Cortex (Snowflake’s integrated vector search service) to find relevant chunks of unstructured data. In our demo, the review PDFs are vectorized and stored in Snowflake; a query like “What’s common about the least satisfactory dishes?” triggers a semantic search over those embeddings. The relevant text snippets (e.g. sentences from negative reviews) are retrieved as evidence.
- Hybrid Query Path: If a question needs both types of answers, the system will do both of the above in parallel. For example, “Which food truck gets the best reviews for chicken?” involves finding structured data (identifying a truck with top ratings) and also pulling unstructured snippets (review excerpts about chicken dishes) – the GraphRAG pipeline merges these results.
- Answer Generation: Finally, the retrieved structured results and text excerpts are fed into an LLM (e.g. GPT-4) which composes a natural language answer. The LLM is prompted with the context from the database query and document snippets, allowing it to explain or summarize accordingly. In our demo, the answer might read like: “Truck Bella’s Best Bites sold the most meals in 2022 (5,420 orders). Customers often praised its chicken tacos – reviews frequently mention ‘tender chicken’ and ‘flavorful sauce’ as highlights.” This way, the response combines a factual, verifiable statistic with qualitative context from customer feedback – a direct payoff of the GraphRAG approach.
Notably, every step in this process is underpinned by Timbr’s semantic layer. The ontology ensures that the structured queries are accurate and meaningful (no SQL guessing), and it provides the “knowledge graph memory” that the LLM can rely on. Meanwhile, Snowflake provides the muscle to handle large-scale data and vector search, all in one platform. The Timbr GraphRAG SDK orchestrates these pieces, so developers can focus on modeling their domain and questions, rather than plumbing data pipelines.
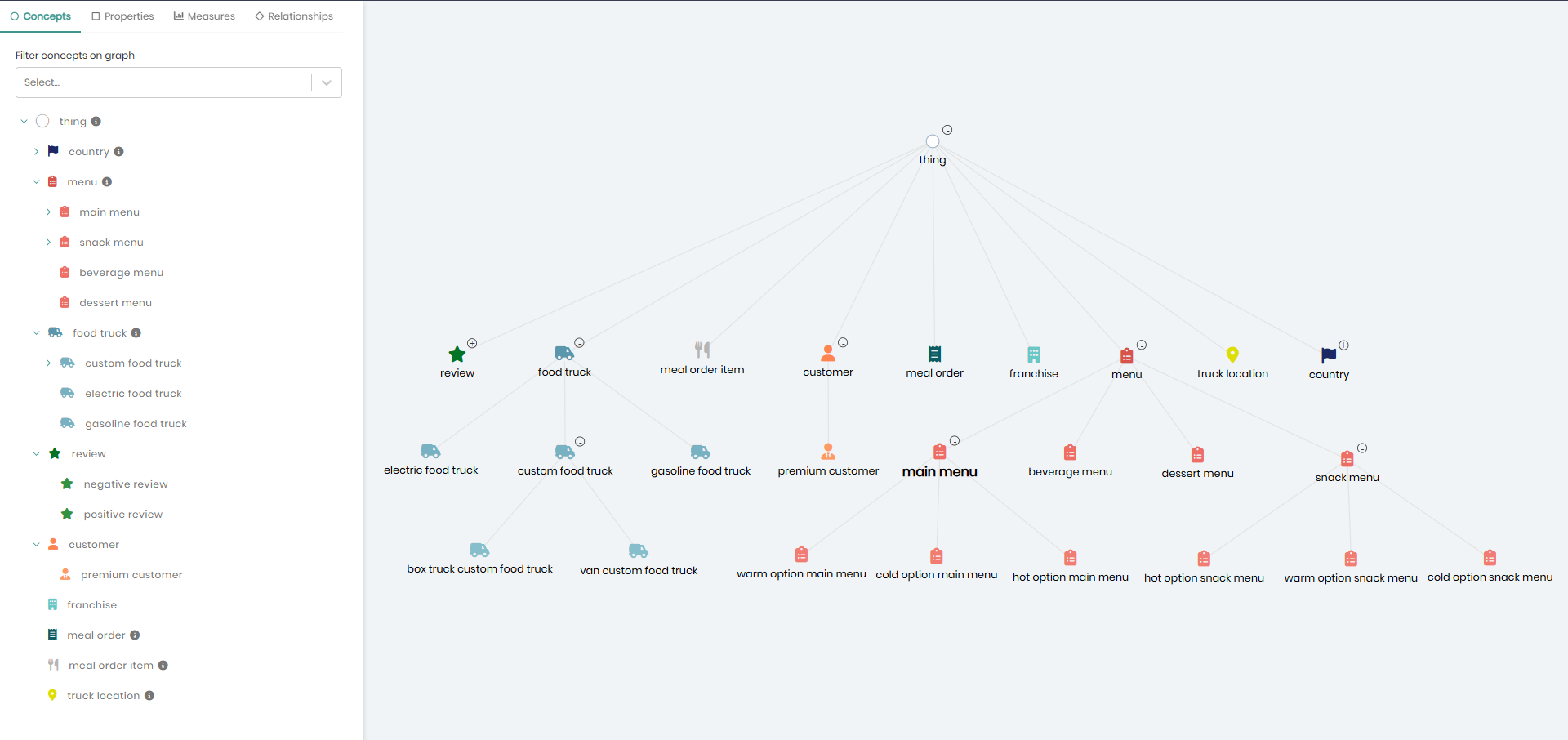
Ontology model of the Tasty Bytes dataset, mapping core concepts like customers, trucks, orders, and reviews to Snowflake tables for seamless querying in GraphRAG workflows.

Lineage view showing how each concept is mapped to its corresponding Snowflake tables, enabling full traceability and transparency from source data to knowledge graph.
Conclusion
Timbr GraphRAG marks a significant step toward graph-powered AI in the enterprise. By marrying knowledge graphs with LLMs, organizations can achieve a new level of precision and context in AI-driven analytics and assistants. Data engineers benefit from a unified framework that accelerates development, while decision makers get more trustworthy answers that reflect a 360° view of their data.
For Timbr users, we invite you to explore the GraphRAG SDK on GitHub and try the included demo with your own data. With Timbr GraphRAG, you can transform siloed data and documents into a holistic, question-answering powerhouse – ushering in more informed decisions and intelligent automation, all grounded in your enterprise’s knowledge.
New to Timbr?
Start with a free trial and explore the GraphRAG SDK to experience how semantic retrieval delivers deeper, more accurate answers from your enterprise data.
