
Introduction
Enterprises need flexible, scalable, and efficient ways to manage their ever-growing datasets. Traditional data architectures, such as centralized data lakes or warehouses, often struggle to meet the demands of modern organizations, particularly in terms of flexibility, governance, and real-time accessibility.
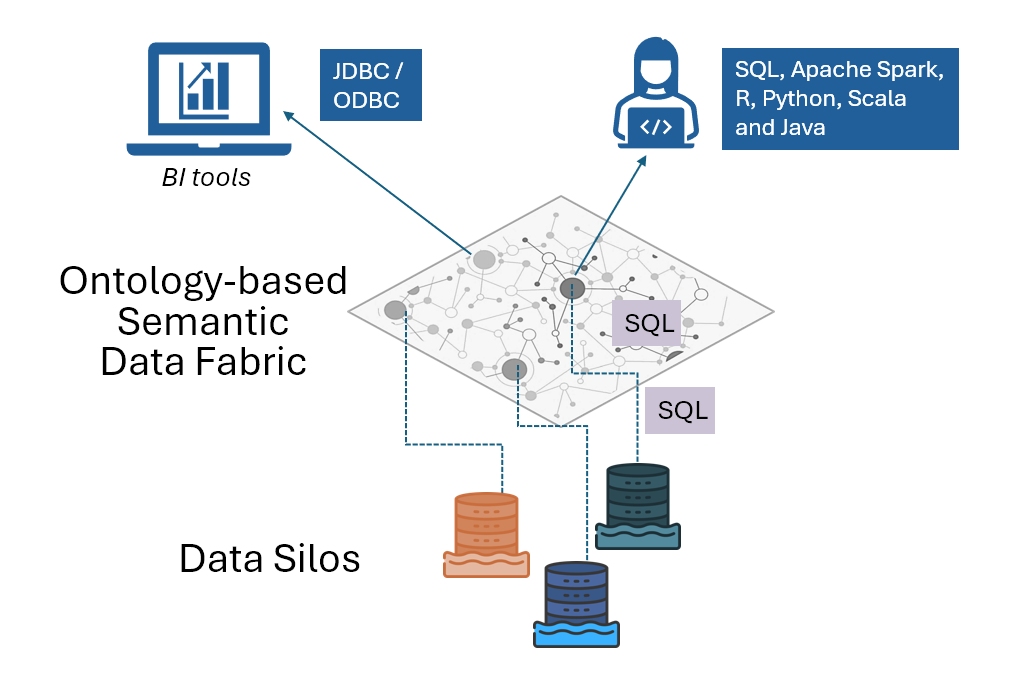
Timbr intelligent semantic layer enables the Semantic Data Fabric aimed to address these challenges by connecting diverse, distributed data sources by means of a virtual, unified semantic data model mapped to federated data, without the need for data duplication or complex ETL (Extract, Transform, Load) processes.
What is a Data Fabric?
A Data Fabric is a data management architecture that enables the integration of data across multiple environments, whether on-premise, in the cloud, or hybrid systems. This architecture is designed to unify disparate data sources and provide seamless access to data without the need for physical movement or consolidation.Data Fabrics facilitate intelligent data discovery, access, and governance, ensuring that the right data is available to the right users at the right time.
In a Semantic Data Fabric, metadata is further enriched with semantic relationships, allowing for advanced data integration, discovery and querying. This concept builds upon traditional data virtualization but adds an extra layer of semantic ontology meaning, which is critical for complex business queries, data lineage tracking, and governance.
Timbr: The Foundation of the Semantic Data Fabric
Timbr Intelligent Semantic Layer powers the Ontology-based Semantic Data Fabric by providing a unified framework for accessing and governing data across multiple domains. Timbr’s foundation in SQL-based knowledge graph technology makes it particularly well-suited for the requirements of a Semantic Data Fabric. It allows enterprises to treat data as a product while ensuring robust governance across distributed data sources.
Key Features of Timbr Semantic Data Fabric
- Data Virtualization Without Duplication: Traditional data architectures often require the physical movement or duplication of data, leading to inefficiencies, delays, and increased storage costs. Timbr’s data virtualization and integrated cache management allow users to query distributed data sources without the need for ETL processes or data duplication. The platform connects to a wide array of data sources, including relational databases, data lakes, and cloud storage systems like Google Cloud Storage, Amazon S3, and Azure Data Lake Storage. This eliminates bottlenecks and provides real-time access to data while minimizing operational overhead.
- Ontology-Based Data Integration: Timbr goes beyond simple data virtualization by enabling the creation of SQL ontologies—semantic models that define relationships, logic and inference between data elements. These ontologies allow for advanced data integration and querying, helping organizations break down data silos and achieve a holistic view of their information landscape. In a Semantic Data Fabric, Timbr’s SQL ontologies make it easy to integrate data from disparate sources by mapping out the relationships between different datasets and domains, thus reducing the complexity of queries and enhancing overall data discoverability.
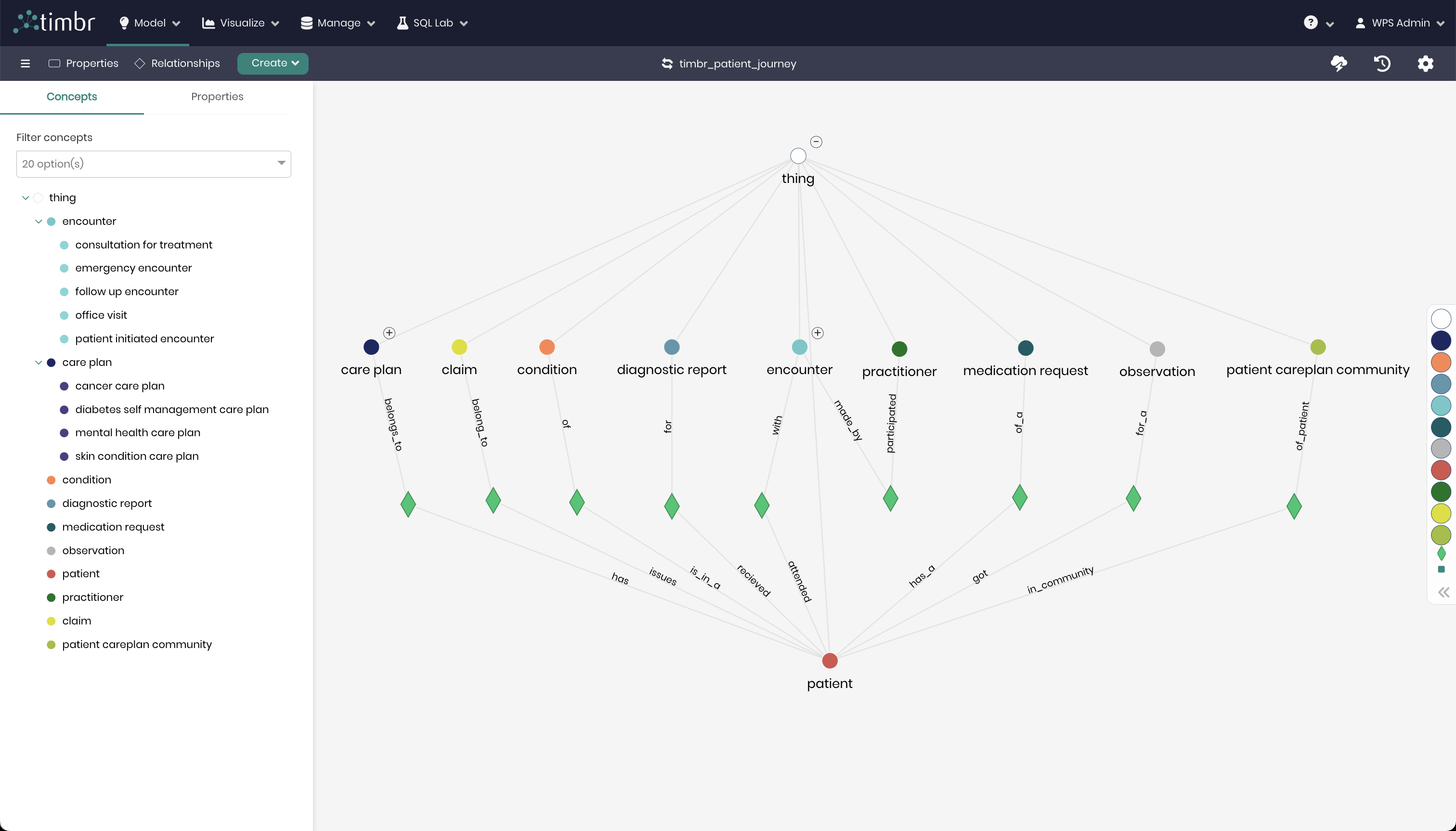
- Visual Exploration of the Data Model: Timbr ontology exploration allows users to visually explore the semantic model by displaying concepts, hierarchies, and classifications as connected nodes within a unified graph. Each node represents a concept linked to data from various sources. By selecting a concept, users can view its associated properties and relationships. Additionally, with a single click, the tool queries sample data, making it easier to understand the underlying information and accelerating the development of data products. This streamlined access to data facilitates faster delivery and enhances data comprehension.
- Visual Exploration of Data as a Network of Relationships: Users can visually explore the data itself as a network of relationships, to gain better understanding, discover hidden value, visually find answers and expose the data without need of extracting tables or views before running a query.
- Data as a Product: Timbr-powered Semantic Data Fabric accelerates delivery of data products. Timbr makes it easy to categorize and manage data as a product, since ontologies define domain-specific data models enriched with metadata, business rules, and governance policies. This helps ensure that data is accessible, relevant, and usable for various business functions, whether it’s analytics, reporting, or application development.
- Self-Service Data Access: Timbr empowers users to access and query data by its meaning using explicit relationships that eliminate the need of JOINs making SQL queries up to 90% shorter. This feature, coupled with Timbr’s data virtualization capabilities, enables self-serve data access for analysts, data scientists, and developers. This democratizes data access across the organization, reducing bottlenecks and improving agility in responding to business needs.
- Governance and Security: A key challenge in modern data architectures is ensuring robust governance and security, particularly in decentralized systems. Timbr addresses this issue by providing comprehensive governance features, including row-level security, compartmentalized access controls, and detailed user rights management. This ensures control data products while adhering to organization-wide governance standards.
- Universal Data Consumption with ODBC/JDBC: Timbr is fully JDBC/ODBC compliant, meaning it can easily integrate with existing BI tools, such as Tableau, PowerBI, and Qlik. This is a crucial feature for organizations that rely on these tools for analytics, as it ensures seamless access to the virtualized data within the Semantic Data Fabric without requiring significant reconfiguration or retraining of personnel.
- Powering Smart Data Apps: Timbr REST API blends the best features of REST and GraphQL, providing real-time access for modern data applications, especially those that rely on up-to-date information for analytics or operational decision-making. The REST API provides an intuitive way to interact with the Semantic Data Fabric, allowing applications to fetch specific fields, manage nested data structures, and reduce over-fetching or under-fetching. By minimizing round trips and optimizing response sizes, Timbr ensures that applications remain responsive and efficient, even when handling large volumes of data or complex queries.
- Support for Machine Learning: Timbr supports programmatic languages such as Python, Java, Scala, and R so data scientists can easily integrate virtualized data Timbr into their existing workflows, regardless of their programming environment. This flexibility makes it easier to build powerful, data-driven applications without the need to adopt new tools or frameworks.
Conclusion
As organizations continue to evolve and scale, the need for flexible, scalable data architectures will only grow. The Semantic Data Fabric, powered by Timbr’s SQL-based knowledge graph technology, offers a path forward for organizations looking to overcome the limitations of traditional data architectures. By enabling seamless access to data across distributed environments, enhancing governance, and facilitating data discovery through semantic relationships, Timbr delivers a critical component of the modern data stack.
How do you make your data smart?
Timbr virtually transforms existing databases into semantic SQL knowledge graphs with inference and graph capabilities, so data consumers can deliver fast answers and unique insights with minimum effort.
