
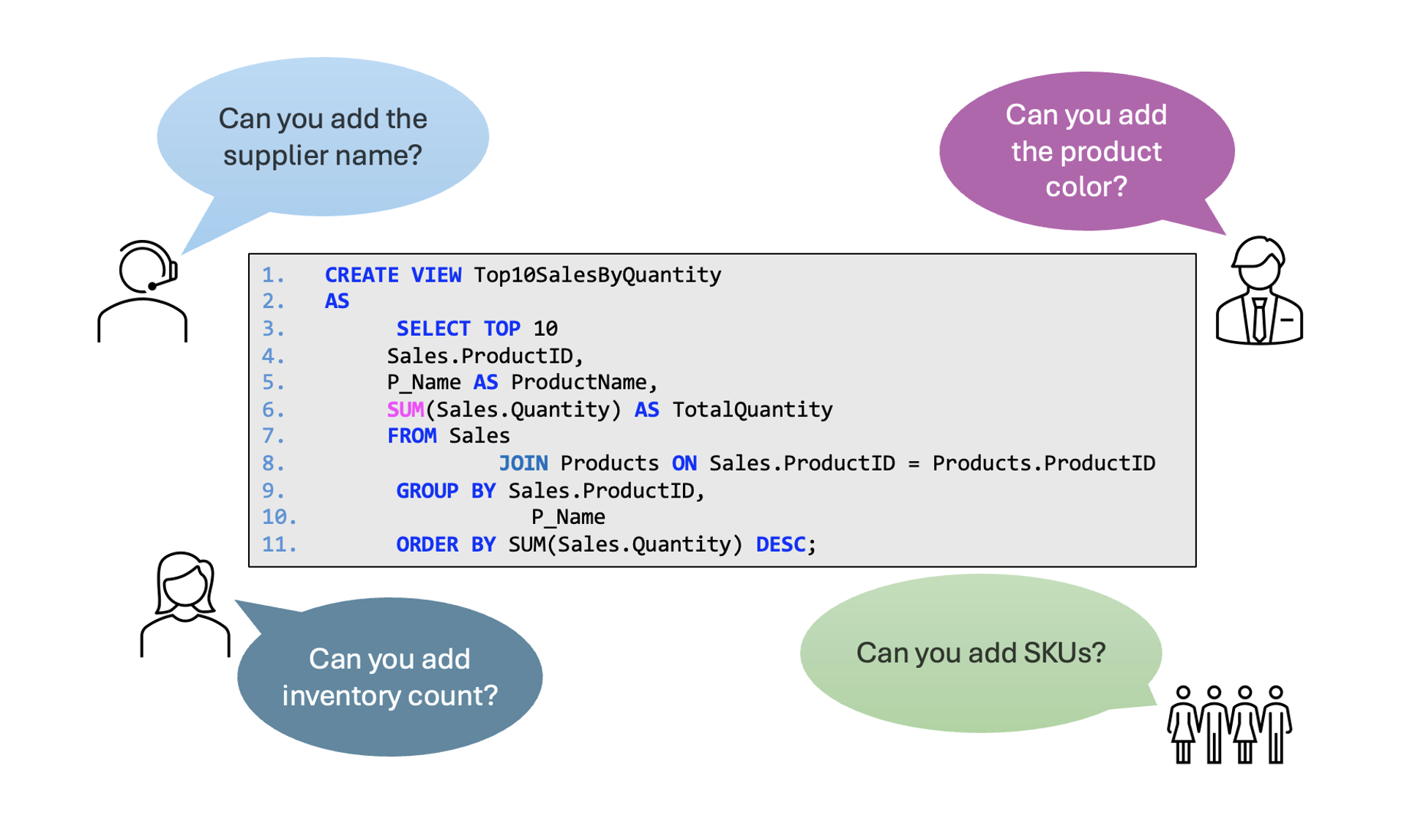
Aren’t you tired of creating Views over and over again?
How much time are you wasting managing Views?
Can you keep track of all the Views in your databases?
If any of the above relates to you or if you have concerns about the scalability of this approach, this blog is for you.
To begin with, let’s state the obvious—creating a database View and sharing it with your users is probably your default way to go. If the View is not complex, the tables are well documented, and it provides the data your users want, it shouldn’t take long. It’s easy to create and probably easy to update in case of user requests.
But what happens when the tables are not well documented? How much time does that add to the process? Or what if the View requires complex JOINs and business logic? How much effort will that require? And how many Views can you manage this way? Tens? Hundreds? Thousands? And we’re not even scratching the surface of the problems organizations face when they want to change a database or include another tool and monitor it all. The solution to mitigate all these issues is to use a Semantic Layer, more specifically, Relationships in a Semantic Layer.
Semantic Layers provide a flexible, decoupled layer that allows for easier changes and adaptations. They abstract the physical data model from the business logic, enabling rapid adjustments without affecting the underlying data. They allow you to centralize business definitions and rules, ensuring consistent usage. They provide a governed layer where access and changes are controlled, documented, and easily audited.
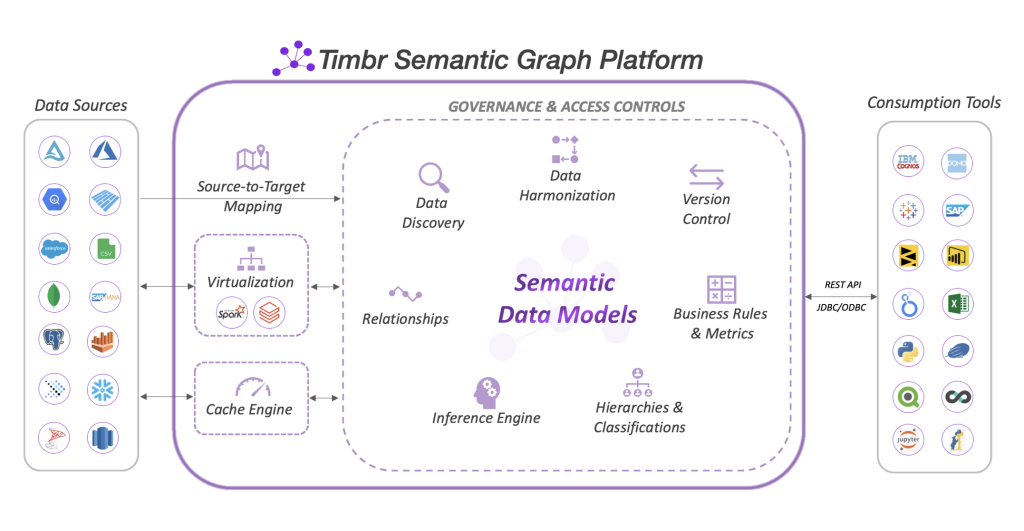
At the core of Timbr’s semantic layer lays the foundational concept of Relationships.
In this blog, we will outline the benefits of Relationships and how they relate to almost every data activity across the organization, from data engineering, discovery, exploration, to consumption. So, let’s dive in.
In a nutshell, Relationships in Timbr are semantic connections between tables that form an interconnected data model. Just like in real life, Relationships define the type of connection between two objects and formally contextualize it. You can think of the difference between calling two individuals “friends” or “married.” These two definitions provide context to their relationship and determine additional facts that would help us better engage with those individuals.
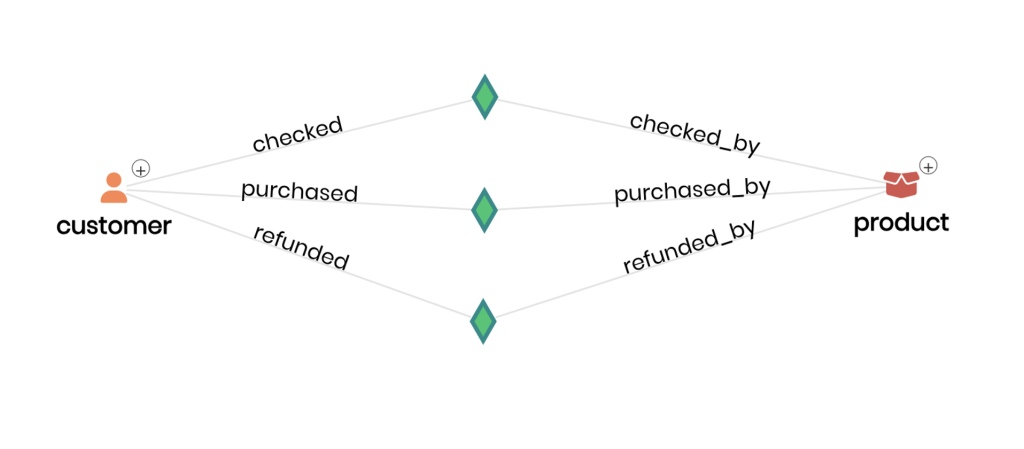
The same goes for Relationships in Timbr. They provide the contextual definition between tables, but it doesn’t stop there. Relationships also indicate to Timbr how to efficiently JOIN these tables without requiring users to explicitly write the JOIN condition.
A good example would be a comparison between explicitly writing JOIN conditions in a query to combine data from 5 different tables vs. using the Relationships to automatically generate those JOIN conditions where the semantic context is the condition on which each JOIN will be executed. This is the impact – when you have relationships in a data model, users can independently use every path available across the model to combine data from the tables, thus enabling all the possible data connections dynamically. So, is it clear by now?
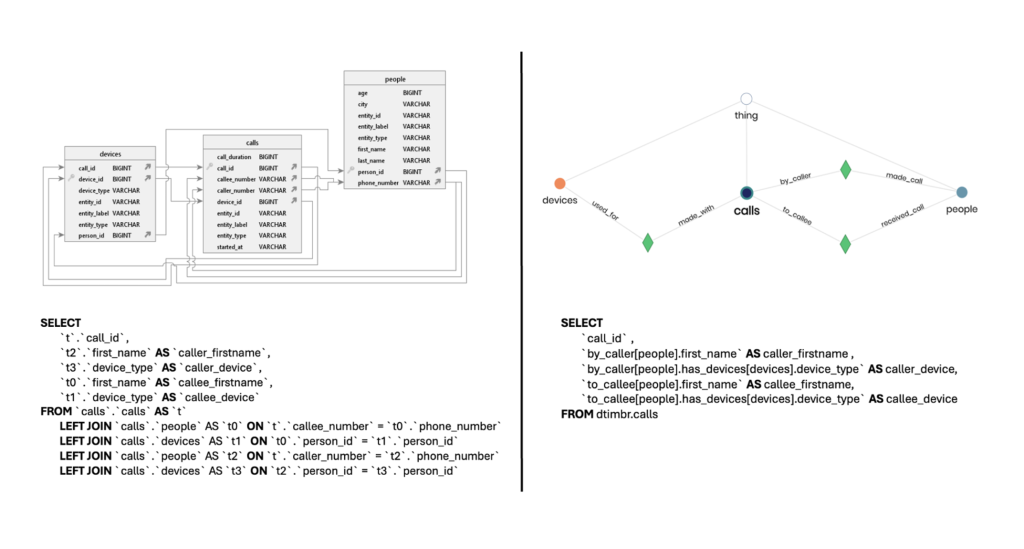
Let’s go over a few scenarios where Relationships help your day-to-day activities:
1. Relationships instead of Views
Imagine a table with endless metadata, that includes all the possible dataset connections in your database. The value is clear – instead of creating views, create relationships. Your users will be able to use and reuse any relationship according to their business context, add, change, or remove columns as they wish, without depending on another team to create a dedicated view for each use case.
Now imagine combining this capability with a virtualization (federation) engine. You can create a data model with relationships across datasets from different databases, multiplying the value users get. The more data you have, the more value you get.
2. Optimized Query Performance
Now, let’s add to the first point the fact that, by default, it’s all virtual. Timbr only pushes the JOINs down to the database according to the Relationships used in the query. From a performance standpoint, you don’t execute all existing JOINs like when using Views. Since the schemas and tables are virtual, Timbr will only push down the selected Relationships as JOINs to the database according to what the user specified in the query.
3. Management & Governance
If Views are your go-to method to expose data, you may want to set global standards for documenting what each view includes and for which project it was created, right? That’s an approach that is prone to fail. Either it already has failed, or it’s going to, because eventually, it’s impossible to enforce these rules across an organization in a standardized fashion. On the other hand, Timbr comes with management and governance features. From built-in Data Lineage to automated Version Control, all semantic data models are fully equipped for easy management, while enabling a centralized access control approach to keep track on who is using what, when, and how much.
4. One Change vs Changing One-by-One
Adding a new dataset? Instead of updating an endless amount of Views to include the new data in your dashboards or applications, a one-time action of creating a Relationship to the new dataset allows all users to independently update their metadata and use the new data when relevant. Again, the more data you have, the more value you get.
5. Self-service Kingdom
By combining all the benefits above, users in your organization are not dependent on the availability, pipeline, timelines, or kindness of data teams. When using a semantic data model, which explicitly includes the business context together with Relationships, every user who gets access to the model has all the building blocks he needs to work independently and fast-track use cases without relying on anyone else.
So, I guess by now, you understand the enormous value of Relationships in your data models. To conclude, Timbr offers a new paradigm for connecting and querying data. Leveraging the famous graph traversals from the graph domain, the unique patent of Timbr enables these traversals in standard SQL, accessible to every user who knows SQL and every tool with JDBC/ODBC or Spark connectors. The overall efficiency you get, combined with the cost reduction in compute and go-to-market times, takes organizations to a new era of data management, facilitating data consumption throughout the organization.
Semantics make your data easier to understand, Timbr makes your data easier to use.
How do you make your data smart?
Timbr virtually transforms existing databases into semantic SQL knowledge graphs with inference and graph capabilities, so data consumers can deliver fast answers and unique insights with minimum effort.
