
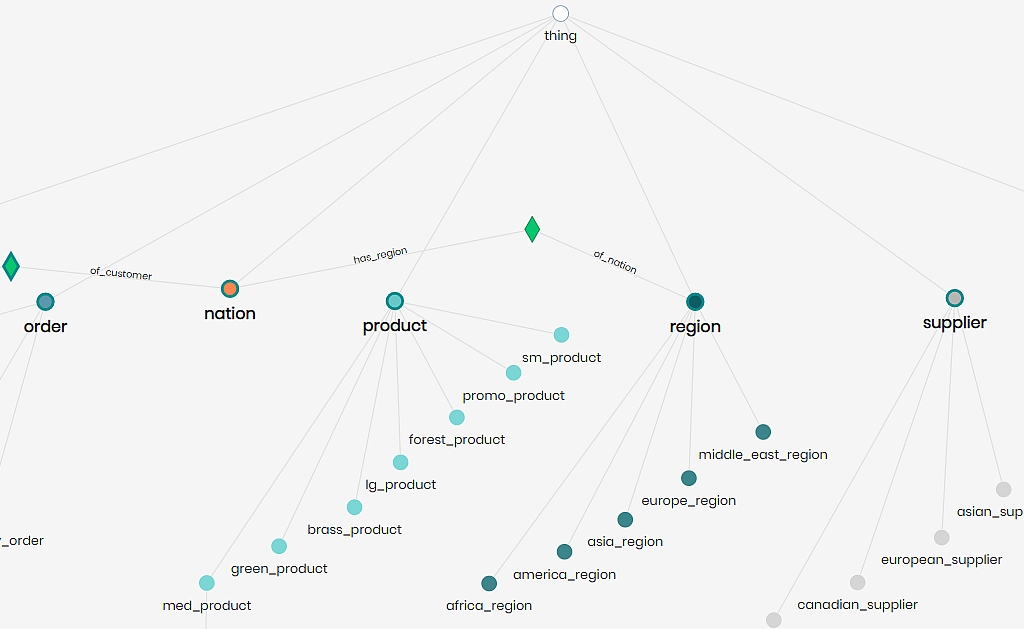
- SQL ontologies provide a practical, flexible way to model data, replacing traditional ERD structures with semantic models that simplify querying relationships across data sources, all within a familiar SQL environment.
- Relationships are first-class entities, allowing for search, reuse, and exploration based on their structure. These relationships carry semantic meaning, with the direction of the relationship being significant.
- Inheritance and transitive reasoning in SQL ontologies help reduce redundancy by automatically applying shared properties and relationships across concepts.
Introduction
Data modeling is a critical part of any data-driven organization. Traditionally, Entity-Relationship Diagrams (ERDs) have been the go-to method for representing data structure. But as organizations grow and their data landscapes become more complex, traditional ERDs and relational database models start showing their limitations. That’s where SQL ontologies step in, as implemented in Timbr intelligent semantic layer.
In this blog post, we’ll explore what SQL ontologies are, how they differ from traditional data models like ERDs, and how Timbr leads the way with intelligent semantic models that let data practitioners work smarter to deliver faster. If you’re a data professional already familiar with SQL and ERDs, this blog will show you how SQL ontologies offer a powerful and more dynamic way to model and query data.
Understanding SQL Ontologies: An Intelligent Approach to Data Modeling
At its core, an ontology defines the relationships between different data entities in a domain, in a way that’s more meaningful and logical than simply creating tables and columns. In Timbr, SQL ontologies are used to represent real-world objects and their relationships in a way that is semantic – meaning the system understands and infers connections between the data.
For instance, let’s say you’re modeling a customer database. In traditional ERD modeling, you would create a table for “Products”, a table for “Orders” and a table for “Customers” then manually define how they relate to each other using foreign keys and JOIN statements. This method requires expertise and a lot of manual effort when querying complex relationships.
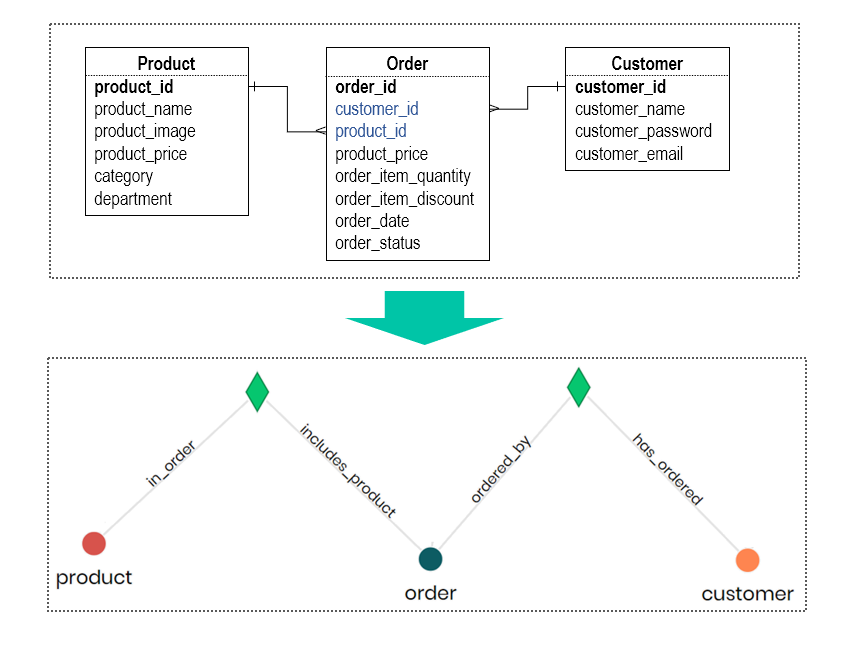
In contrast, Timbr’s SQL ontologies treat these entities as concepts with built-in relationships. Instead of manually creating JOINs, the system inherently knows how “Products” relate to “Orders” or “Customers” based on the logical links defined in the ontology. This semantic layer allows you to write simpler, more intuitive SQL queries that mimic natural language and directly reference the relationships between concepts.
For example, querying which customers made orders becomes a much simpler task because the relationship between “Customer” and “Order” is already defined in the ontology, and Timbr’s intelligent model does the heavy lifting.
What Makes SQL Ontologies Different from ERDs?
While ERDs do a good job of visually representing the structure of your data, their implementation in the physical relational model present several important limitations. Here’s a breakdown of how SQL ontologies differ:
- Intelligence: In Timbr, SQL ontologies are intelligent models. This means that not only can you map out the relationships between different data entities (like you would in an ERD), but Timbr also allows you to perform reasoning over your data. For example, if you know that a “VIP Customer” is a type of “Customer,” you don’t need to manually replicate the “Customer” properties (like name, age, etc.) for the VIP Customer. The model automatically inherits them.
- Semantic Relationships: Unlike ERDs, where relationships are manually defined with foreign keys and each query requires writing complex JOINs, SQL Ontologies introduce named relationships like “owns,” “belongs to,” or “is related to.” These relationships are first-class entities that support the exploration, reuse, and search of relationships based on their structure, with the direction of the relationship carrying meaning. Additionally, SQL Ontologies simplify querying, enabling more natural and intuitive SQL queries without the need for manual JOINs.
- Inference: One of the most powerful features of Timbr’s SQL ontologies is transitive reasoning. If you know that a “Person” IS-A “Customer” and that a “Customer” owns a “Car,” Timbr’s SQL ontology will automatically infer that the “Person” owns a “Car.” This type of reasoning greatly simplifies querying complex data relationships.
- Flexibility Across Systems: Timbr enables SQL ontologies to map data across multiple systems. You can integrate relational databases, data lakes, or even big data engines into one coherent model that lets you query as though it’s all part of a single data set.
SQL Ontologies: Built for Modern Data Challenges
With growing data volumes and increasingly complex data relationships, traditional data models can become cumbersome. Here are some real-world challenges where SQL ontologies make all the difference:
1. Dealing with Complex Relationships
In a traditional relational database, complex relationships require intricate JOINs, subqueries, and unions. As the complexity increases, so does the likelihood of query errors and performance issues. With SQL ontologies in Timbr, the relationships between data entities are modeled semantically, meaning that you can simply ask for data based on how it’s related, rather than manually constructing convoluted queries.
Using as example question Q2 of the TPC-H benchmark, “The Minimum Cost Supplier Query” finds, in a given region, for each part of a certain type and size, the supplier who can supply it at minimum cost. If several suppliers in that region offer the desired part type and size at the same (minimum) cost, the query lists the parts from suppliers with the highest account balances. For each supplier, the query lists the supplier’s account balance, name and nation; the part’s number and manufacturer; the supplier’s address, phone number and comment information. This query requires 7 JOINs.
SELECT s_acctbal,
s_name,
n_name,
p_partkey,
p_mfgr,
s_address,
s_phone,
s_comment
FROM tpc.part
INNER JOIN tpc.partsupp ON p_partkey = ps_partkey
INNER JOIN tpc.supplier ON s_suppkey = ps_suppkey
INNER JOIN tpc.nation ON s_nationkey = n_nationkey
INNER JOIN tpc.region ON n_regionkey = r_regionkey
WHERE p_size = 15
AND p_type like '%BRASS'
AND r_name = 'EUROPE'
AND ps_supplycost = (
SELECT min(ps_supplycost)
FROM tpc.partsupp
INNER JOIN tpc.supplier ON s_suppkey = ps_suppkey
INNER JOIN tpc.nation ON s_nationkey = n_nationkey
INNER JOIN tpc.region ON n_regionkey = r_regionkey
WHERE p_partkey = ps_partkey
AND r_name = 'EUROPE'
)
ORDER BY s_acctbal DESC, n_name, s_name, p_partkey
With a SQL ontology, the relationships between “Supplier”, “Product” and “Region” are already modeled, allowing you to ask for the data with a much simpler query, easier to understand and without JOINs:
SELECT DISTINCT `supplier_account_balance`,
`supplier_name`,
`has_nation[nation].nation_name` AS nation_name,
`from_supplier[brass_product].part_key` AS part_key,
`from_supplier[brass_product].manufacturer` AS manufacturer,
`supplier_address`,
`supplier_phone`,
`supplier_comment`
FROM `dtimbr`.`european_supplier`
WHERE `from_supplier[brass_product].size` = 15
AND ps_supplycost = `from_supplier[brass_product].min_supplycost_europe`
ORDER BY `supplier_account_balance` DESC, `nation_name`, `supplier_name`, `part_key`
2. Handling Inheritance and Transitivity of Properties
In SQL, the concepts of inheritance and transitivity represent unique challenges that are distinct but occasionally intersect, especially in complex database modeling scenarios. Both inheritance and transitivity are important in representing relationships between entities, yet each possesses its own set of difficulties when working within the relational model of SQL databases.
Challenges of Inheritance in SQL
Inheritance in SQL is a way to represent hierarchies between entities where a child table inherits the structure and constraints of a parent table. While this feature is available in some advanced database systems like PostgreSQL, most traditional relational databases don’t natively support inheritance. This creates a significant challenge for database designers who need to model hierarchies, as they are forced to rely on workarounds such as table joins or redundant data storage.
For example, consider an e-commerce system with a Person table that contains basic information like name and address, and two specialized tables Customer and Employee that inherit from Person. In a system without native inheritance support, managing shared data across these tables becomes cumbersome. Designers may need to replicate data in both tables or use multiple foreign keys and joins to achieve similar functionality, which introduces data integrity issues and complicates queries.
Additionally, the lack of inheritance support in SQL limits the expressiveness of the schema, making it harder to manage polymorphic behaviors. Implementing inheritance using views or joins may cause performance degradation, especially in large datasets. This lack of flexibility can be a bottleneck when designing normalized schemas that need to balance both shared and unique attributes across entities.
SQL Ontologies: Simplified Inheritance Modeling
SQL ontologies provide a schema-based representation of hierarchies, where the relationships between entities are defined as part of the ontology itself. This eliminates the need for table duplication or complicated joins to simulate inheritance. Ontologies allow the creation of abstract, reusable entity types that inherit properties and relationships from parent types, much like in object-oriented programming.
For example, if “Artist” is a child-concept of “Person,” it automatically inherits all the properties of “Person” (like “Name,” “Age,” etc.) while allowing you to add artist-specific properties (like “Artworks” or “Exhibitions”). This ensures that shared attributes can be centrally managed and easily extended in derived types, simplifying schema maintenance and reducing redundancy.
Challenges of Transitivity in SQL
Transitivity, on the other hand, deals with relationships that are inferred rather than explicitly defined. A transitive relationship occurs when if A is related to B and B is related to C, it implies that A is related to C. While this is a common logical construct, modeling it in SQL can be difficult due to the relational nature of databases, which traditionally favor explicit relationships through foreign keys.
In SQL, transitive relationships often need to be modeled using recursive queries (e.g., Common Table Expressions (CTEs) or hierarchical queries) or by writing complex joins. These approaches can quickly become inefficient as the dataset grows in size. Transitivity also presents challenges in maintaining data integrity because the inferred relationship may not always be correctly enforced by foreign key constraints, leaving room for inconsistency.
For example, in a company hierarchy, if an employee reports to a manager, and that manager reports to a director, transitivity would imply that the employee indirectly reports to the director. Writing efficient queries to capture such multi-level relationships can require recursive logic, which can be computationally expensive in SQL, particularly when the hierarchy is deep.
SQL Ontologies Enable Transitivity in SQL
Ontologies handle transitive relationships natively by defining relationships between entities that can be inferred through logical rules. This reduces the reliance on complex recursive SQL queries or multi-level joins to model transitive dependencies. By formalizing these relationships within the ontology, SQL ontologies allow for automatic inference of indirect connections, leading to more efficient querying. For example, querying a multi-level hierarchy can be streamlined by the ontology’s built-in rules for transitivity, avoiding deep recursive queries.
3. Merge ERDs? Better Harmonize Distributed Data Sources
One of the major limitations of traditional relational databases is their siloed nature. Data from different sources—whether in relational databases, NoSQL, or data lakes—are difficult to harmonize into a single coherent model. With SQL ontologies, users harmonize data from these distributed sources without needing to move or merge it. They create a unified view by mapping attributes from both systems into one virtual concept, like “Customer,” allowing the query of customer details and order history together, even though they are stored separately. This makes it easier and faster to analyze data.
Why Choose Timbr SQL Ontologies?
Timbr’s implementation of ontologies is different from other semantic modeling solutions for one main reason: It’s entirely based on SQL. You don’t need to learn specialized modeling and query languages to use Timbr. Instead, Timbr enhances the SQL you already know by incorporating the power of knowledge graphs. This means you can leverage the entire SQL ecosystem of data sources, business intelligence solutions, machine learning and data science tools. In addition, users benefit from:
- Modeling directly fromo Databricks notebooks
- Modeling visually or in SQL.
- Querying the ontology in SQL, Apache Spark, R, Python, Scala and Java.
- Enabling accurate LLM2SQL queries.
- Visual exploration of the ontology.
- Visual exploration of data as a graph of relationships.
Final Thoughts
SQL ontologies in Timbr bring a smarter, more intuitive way to model and query your data. By treating your data as a web of concepts and relationships rather than static tables, you unlock new possibilities for reasoning and analysis that traditional ERDs and relational models simply can’t match.
Adopting Timbr SQL ontologies for modeling data brings numerous advantages to data professionals. It simplifies the data modeling process, enabling developers to represent complex real-world relationships more naturally and accurately. This simplification leads to cleaner, more maintainable code and reduces the likelihood of errors.
Perhaps most importantly, Timbr intelligent semantic layer facilitates greater flexibility and interoperability, making it easier to adapt and extend data models as requirements evolve. These benefits collectively result in accelerated development cycles, reduced maintenance overhead, and enhanced analytical capabilities, making Timbr an invaluable tool for organizations looking to leverage complex analytics.
Start leveraging the power of SQL ontologies today with Timbr and see how it transforms your approach to data modeling and querying.
