

There is a built-in discrepancy between how businesses conceptualize their business domain, and how this conceptualization gets translated into concrete data models.
Virtual SQL Ontologies resolve this discrepancy by delivering key capabilities to relational databases that data modeling can’t deliver, such as defining abstract concepts, business rules, context and relationships that enrich data.
Data modeling
Data modeling was conceived forty-five years ago to help with the design of relational databases and defining a formal vocabulary for the organization. The ANSI definition differentiated between three data models – conceptual, logical and physical.
Data modeling quickly established itself as the process used to define and analyze data requirements, needed to support the business processes within the scope of information systems in organizations. This process involves close engagement between professional data modelers and business stakeholders, as well as potential users of the information system.
Data models
The term data model can refer to two distinct but closely related concepts. Sometimes it refers to an abstract formalization of the objects and relationships found in a particular application domain, for example: the customers, products, and orders found in a manufacturing organization. At other times it refers to the set of concepts used in defining such formalizations, for example: concepts such as entities, attributes, relations, or tables. So, the “data model” of a banking application may be defined using the entity-relationship “data model”.
A data model explicitly determines the structure of data. Data models are typically specified by a data specialist, data librarian, or a digital humanities scholar in a data modeling notation. There are three different types of data models produced while progressing from the requirements phase to the actual creation of the database to be used for the information system.
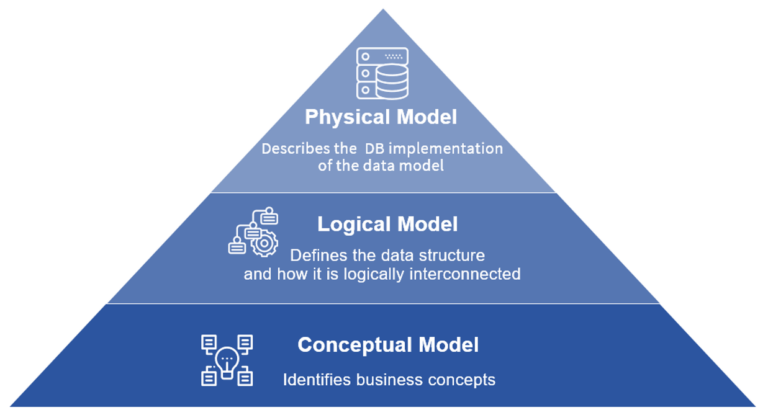
Conceptual data model
In the initial phase, the data requirements are recorded as a conceptual data model. This is essentially an organized view of concepts and their relationships described as a set of technology-independent specifications about the data. It is used to discuss initial requirements with the business stakeholders. The conceptual model is then translated into a logical data model.
Logical data model
The Logical Data Model is used to define the structure of data elements and to set relationships between them. The logical data model documents structures of the data that can be implemented in databases independently of physical considerations. Implementation of one conceptual data model may require multiple logical data models.
Physical data model
The final step in data modeling is transforming the logical data model into a physical data model. The physical data model organizes the data into tables, accounts for access, performance and storage information.
The information left behind from the conceptual model: business rules, relationships and context
When modeling is done to create a relational database, the conceptual model must be different from a logical model because there is no place in a relational database structure to capture, for example, business rules, describe relationships, provide context and record other key aspects of a conceptual model.
This semantic information collected and documented as part of the initial modeling is left behind when modelers and designers move on to define a logical data model. The “left behind” parts are used by software developers as they encode business semantics directly into custom programs, so it’s quite impossible to re-use this work elsewhere in the organization.
Similarly, the logical data model, being a subset of the conceptual model expressed using a particular technology, leaves behind some of its elements as it gets translated into a physical data model before it can be implemented in a relational database.
Ontologies:
Data modeling with no left behind parts
An Ontology (within information sciences) is a model of a domain described by a set of abstract concepts and their relationships, as well as individuals thereof. Therefore, all three types of data models can be thought of as ontologies. They range from the most expressive one that describes business concepts and processes (the conceptual model) to less expressive ontologies. They progressively shift from describing business semantics to describing the data’s physical structures of the data as it is stored in databases (the logical and physical data model).
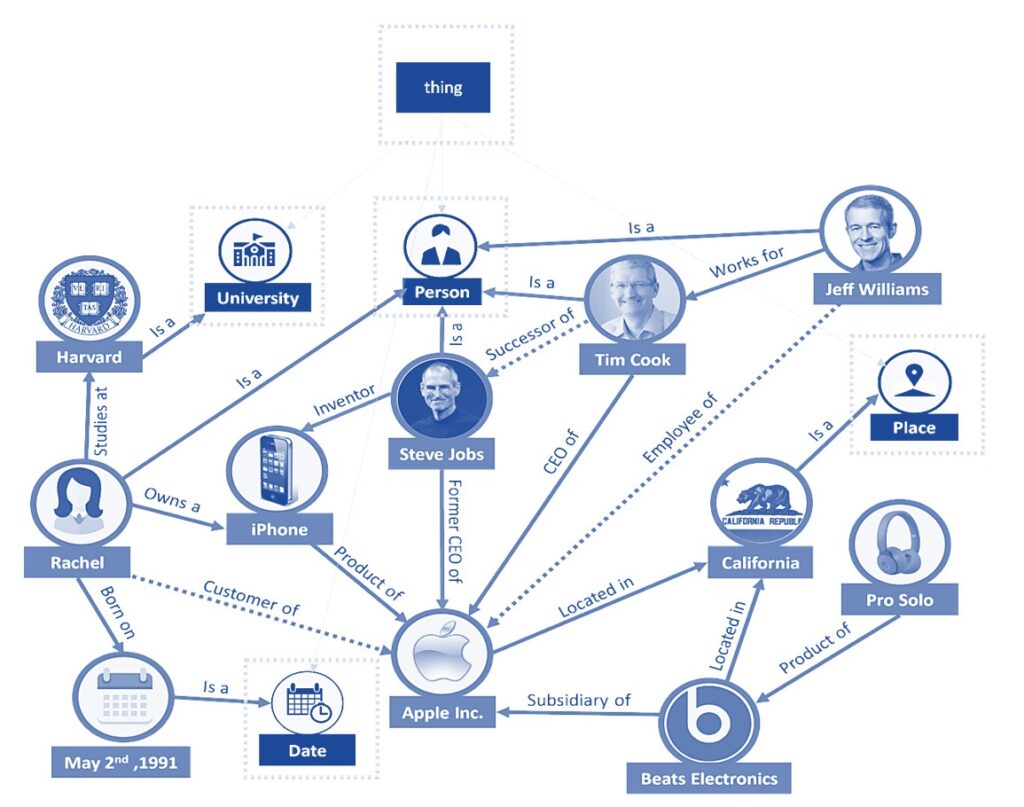
Ontologies represent knowledge as concepts organized as a network of nodes. As such, ontologies have hierarchical, inheritance, and inference capabilities that bear a similarity to object-oriented classes. An ontology is built from entities that are linked via relationships to form a hierarchical directed graph. The structure of the ontology can subsequently be mined to infer knowledge, for example, from an inheritance hierarchy defined for two entities, or a graph connectivity reflecting a relationship between two entities.
Semantic Web Ontologies (OWL Ontologies)
The Semantic Web standards developed by W3C make it possible to implement conceptual models directly, in the form of OWL ontologies, thanks to the layered architecture of the Semantic Web technology stack.
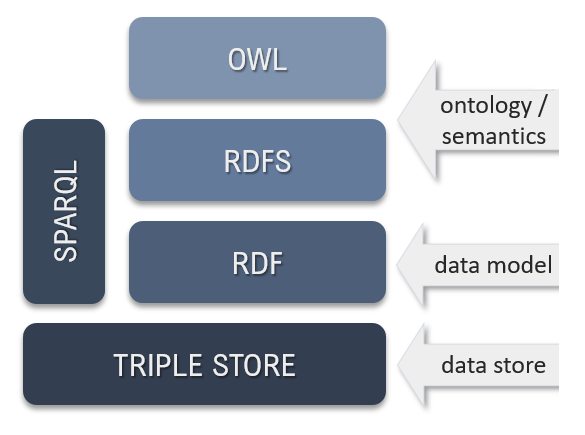
This paradigm works well, assuming the databases are built from ground zero. The problem is that some 80% of the world’s information is stored in relational databases and as such, to benefit from key capabilities such as business rules, context and relationships, organizations are required to recreate, maintain and manage their databases according to the Semantic Web standards. This entails challenges that include installing and maintaining separate database infrastructures, apply continuous ETL processes to transform data into RDF triples, modeling ontologies in complex OWL and training IT personnel new skills such as querying in SPARQL. It also entails letting go of business intelligence tools that natively work in SQL.
Virtual SQL Ontologies:
The straightforward solution to left behind information
Virtual SQL Ontologies (“SQL-O”) employ standard SQL to implement the key capabilities of Semantic Web ontologies and thus eliminate the challenges associated with their adoption and enterprise use: no need to add database infrastructure, no need to move data, no ETL operations, no retraining of IT personnel, no need to learn new programming languages and no need to modify or change BI tools.
SQL-Os make sure that the key information left behind by data modeling is kept by enabling the definition of abstract concepts that give common meaning to data and are enriched with business rules, relationships, context and logic. These concepts are mapped to existing databases to enable querying of the underlying data in standard SQL and connect to the popular business intelligence tools and data science notebooks in use by enterprises.
Among the many advantages of using virtual SQL ontologies mapped to the data, querying the context-enriched concepts instead of querying the data delivers an immediate and powerful benefit: SQL queries are reduced in size by up to 90%.
In the case of the modern data lakes solutions where no actual data modeling is done, SQL-Os enable organizations to use concepts to maintain an accurate, business-meaningful glossary or taxonomy of the terms that describe all the artifacts in a data lake, besides providing semantic and relationship enablement. This empowers users to search, discover, understand and query the appropriate elements of the data lake with little or no need for interaction with the IT organization maintaining the data lake.
SQL-Os introduce a new paradigm that leverage the huge SQL ecosystem, modernizing databases without adding to, or changing the organization’s IT infrastructure and delivering a universal solution for linking heterogeneous data sources and enabling smart data.
Contact us for a test drive of the timbr SQL Knowledge Graph platform to experience the benefits of virtual SQL Ontologies.
Notes:
[1] Some of the explanations used in this article to describe data models, data modeling and ontologies are taken from the corresponding pages in Wikipedia.
Are you using your data strategically?
timbr virtually transforms existing databases into semantic SQL knowledge graphs with inference and graph capabilities, so data consumers can deliver fast answers and unique insights with less effort.
With timbr, your organization can join the knowledge revolution.
