

- Developers of data applications often face challenges like complex queries, integrating multiple data sources, and ensuring high performance and real-time access while maintaining security and scalability.
- Timbr simplifies querying by replacing complex SQL JOINs with semantic relationships, enabling more efficient data access, integration across multiple sources without replication, and real-time querying via its REST API.
- Timbr’s robust role-based security, dynamic scalability, and flexible integration with modern and legacy systems empower organizations to build secure, scalable, and high-performance data applications that can easily adapt to changing business requirements.
Introduction
Developing data applications today comes with several challenges: managing vast datasets, ensuring high performance, maintaining robust security, and integrating data from multiple sources. Traditional approaches, often reliant on time-consuming discovery of data, complex SQL queries, slow data pipelines, and redundant infrastructure, can slow down development and make applications difficult to scale and maintain.
This blog explores how Timbr’s semantic layer simplifies these processes by transforming data access, accelerating data discoverability, optimizing query efficiency, and seamlessly integrating various data sources.
Challenges in Data Application Development and how Timbr Solves Them
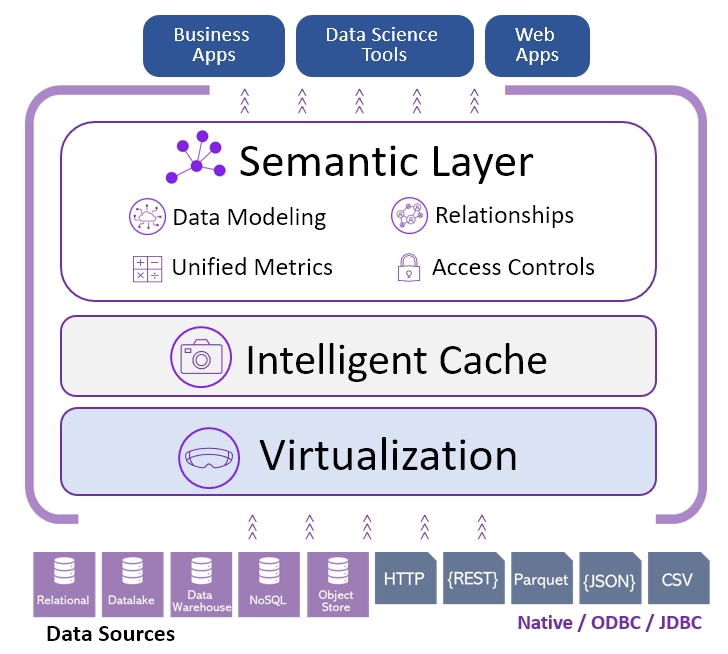
Building data applications presents numerous obstacles for developers, from navigating complex datasets to ensuring real-time data access and maintaining performance across large, interconnected data sources.
Traditional methods of managing data—relying on SQL JOINs, data replication, and rigid pipelines—often result in slow development cycles, errors, and performance bottlenecks.
Timbr intelligent semantic layer addresses these challenges with simplified data discovery, streamlined querying, optimized performance, and enhanced security:
Fast Discovery of Data
Development of data applications is hindered by the difficulty of locating relevant data across many tables in multiple datasets that are often stored in disparate systems. Developers must navigate complex schemas and relationships, which can slow down access to the data needed for building efficient applications. Timbr speeds up data discoverability by organizing data in a business-friendly manner. Users can easily locate and access relevant data by querying based on business concepts rather than needing deep technical knowledge of the data schema.Simplified Querying
In traditional data applications, complex SQL queries with multiple JOINs are prone to errors and performance bottlenecks, particularly when dealing with interconnected datasets. Timbr solves this by replacing SQL JOINs with intuitive relationships defined in an ontology-driven semantic layer. This approach reduces development effort and results in faster, more efficient queries.Performance Optimization
Managing performance, especially for large datasets or many-to-many relationships, is a persistent challenge. Timbr improves performance by optimizing query execution through intelligent query routing, caching, and minimizing the need for repeated data movement. This ensures that even under heavy loads, data applications can handle complex queries without performance degradation.Seamless Data Integration
Data applications often require pulling information from disparate sources like databases, data lakes, or cloud storage. Traditionally, this involves data replication or building complex ETL pipelines. Timbr’s data virtualization eliminates this overhead by allowing seamless access to multiple sources without moving or duplicating data. Applications can retrieve real-time information from various systems, ensuring that developers work with the most current data without the need for replication.Real-Time Data Access
In many modern applications, real-time access to data is essential for analytics and operational decision-making. Timbr’s virtualized data access, combined with its REST API, ensures that applications can fetch real-time data directly from the source. By eliminating delays typically introduced by traditional ETL processes, Timbr empowers developers to build dynamic, data-driven applications that respond instantly to the latest information.Data Security and Governance
Security is critical when dealing with sensitive data, especially in regulated industries. Timbr provides built-in role-based access control (RBAC) and row-level security, ensuring that users only access the data they are authorized to see. Additionally, Timbr’s auditing and data lineage capabilities provide full transparency, making it easy to track data access and modifications for compliance with regulations like GDPR and HIPAA.
Timbr Key Features for Data Apps
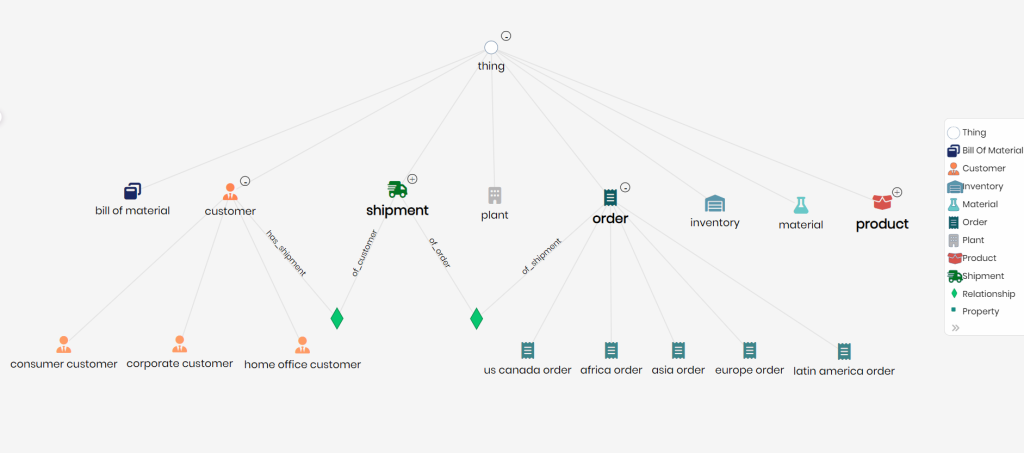
Visual Exploration for Data Discovery
Timbr ontology exploration allows users to visually explore the semantic model by displaying concepts, hierarchies, and classifications as connected nodes within a unified graph. Each node represents a concept linked to data from various sources. By selecting a concept, users can view its associated properties and relationships. Additionally, with a single click, the tool queries sample data, making it easier to understand the underlying information and accelerating the development of data products. This streamlined access to data facilitates faster delivery and enhances data comprehension.
In addition, users can visually explore the data itself as a network of relationships, to gain better understanding, discover hidden value, visually find answers and expose the data without need of extracting tables or views before running a query.
Simplified Querying and Performance Boosts
A major pain point for developers is writing and optimizing complex SQL queries. Traditional approaches rely on multiple JOINs across different tables, which can be difficult to manage and prone to performance issues as data grows.
Timbr’s semantic layer transforms this process by introducing intuitive, named relationships that allow developers to query interconnected datasets without complex JOIN operations. These relationships, defined in Timbr’s ontology, simplify query structures, reduce errors, and result in faster query execution. By abstracting the complexity of data connections, Timbr allows developers to focus on building the application logic rather than worrying about the underlying query mechanics.
Moreover, Timbr’s intelligent query routing ensures that queries are directed efficiently, reducing execution time. Combined with caching mechanisms and optimized data retrieval, Timbr boosts application performance even when handling large datasets with complex relationships.
Data Virtualization for Seamless Integration
Integrating data from multiple sources is often a complex task that requires moving and replicating data, creating additional overhead. Timbr solves this by enabling data virtualization, which allows applications to access data from disparate sources—whether it’s a relational database, data lake, or cloud storage—without the need to move or duplicate data.
This virtualization not only simplifies data integration but also reduces infrastructure costs by eliminating redundant storage and ETL processes. Applications can directly query real-time data from various sources, ensuring that they are always working with the most current and relevant information. This approach also streamlines the development process, as developers no longer need to build complex data pipelines or manage data replication tasks.
REST API That Blends the Best Features of REST and GraphQL
Real-time access is crucial for modern data applications, especially those that rely on up-to-date information for analytics or operational decision-making. Timbr’s REST API allows developers to access data in real time, pulling from various sources without delay.
The REST API provides an intuitive way to interact with Timbr’s semantic layer, allowing applications to fetch specific fields, manage nested data structures, and reduce over-fetching or under-fetching. By minimizing round trips and optimizing response sizes, Timbr ensures that applications remain responsive and efficient, even when handling large volumes of data or complex queries.
Support for programmatic languages such as Python, Java, Scala, and R means that developers can integrate Timbr into their existing workflows, regardless of their programming environment. This flexibility makes it easier to build powerful, data-driven applications without the need to adopt new tools or frameworks.
Universal Data Consumption with ODBC/JDBC
Many organizations still rely on legacy systems or existing tools that interface with data through ODBC/JDBC drivers. Timbr supports both ODBC and JDBC, enabling seamless integration with a wide range of tools and applications.
By supporting these standardized drivers, Timbr allows developers to connect their data applications with legacy systems or modern platforms using familiar SQL-based interfaces. This ensures backward compatibility and reduces the need for major system overhauls, allowing teams to integrate Timbr’s semantic layer without disrupting their existing workflows.
Non-Disruptive Addition of Data Sources
One of Timbr’s core strengths is its flexibility. As business requirements evolve, so do data needs. With Timbr, developers can dynamically add new data sources, modify relationships, and scale applications without need to modify data querying, since queries are directed to the concepts that map to the data.
Enterprise-Grade Data Security and Governance
Data security and governance are critical, especially in environments where data access needs to be tightly controlled. Timbr provides robust security measures, including role-based access controls (RBAC) and row-level security, which ensure that users only access data they are authorized to see.
Additionally, Timbr offers full data lineage and auditing capabilities, giving organizations complete transparency into how data is accessed and modified. This is especially important for compliance with regulations like GDPR and HIPAA, where maintaining accountability for data usage is crucial.
Reducing Costs and Increasing Efficiency
By eliminating the need for data movement, replication, and complex ETL processes, Timbr helps organizations reduce infrastructure costs and operational overhead.
Applications built on Timbr require fewer resources to manage data integration and access, resulting in significant cost savings. Moreover, Timbr’s ability to streamline querying and optimize performance reduces development cycles, allowing businesses to bring new applications to market faster.
The flexibility offered by Timbr’s REST API, ODBC/JDBC support, and semantic layer means that data applications can scale efficiently, ensuring long-term cost savings and improved performance.
Conclusion
Timbr’s semantic layer redefines how data applications handle querying, real-time access, and data integration. With features like data virtualization, REST API, ODBC/JDBC support, and ontology-driven querying, Timbr empowers organizations to build flexible, secure, and scalable applications.
By simplifying data access and optimizing performance, Timbr enables businesses to overcome the traditional challenges of data application development, resulting in more powerful solutions and reduced operational overhead.
How do you make your data smart?
Timbr virtually transforms existing databases into semantic SQL knowledge graphs with inference and graph capabilities, so data consumers can deliver fast answers and unique insights with minimum effort.
