Semantic Representation
of Data
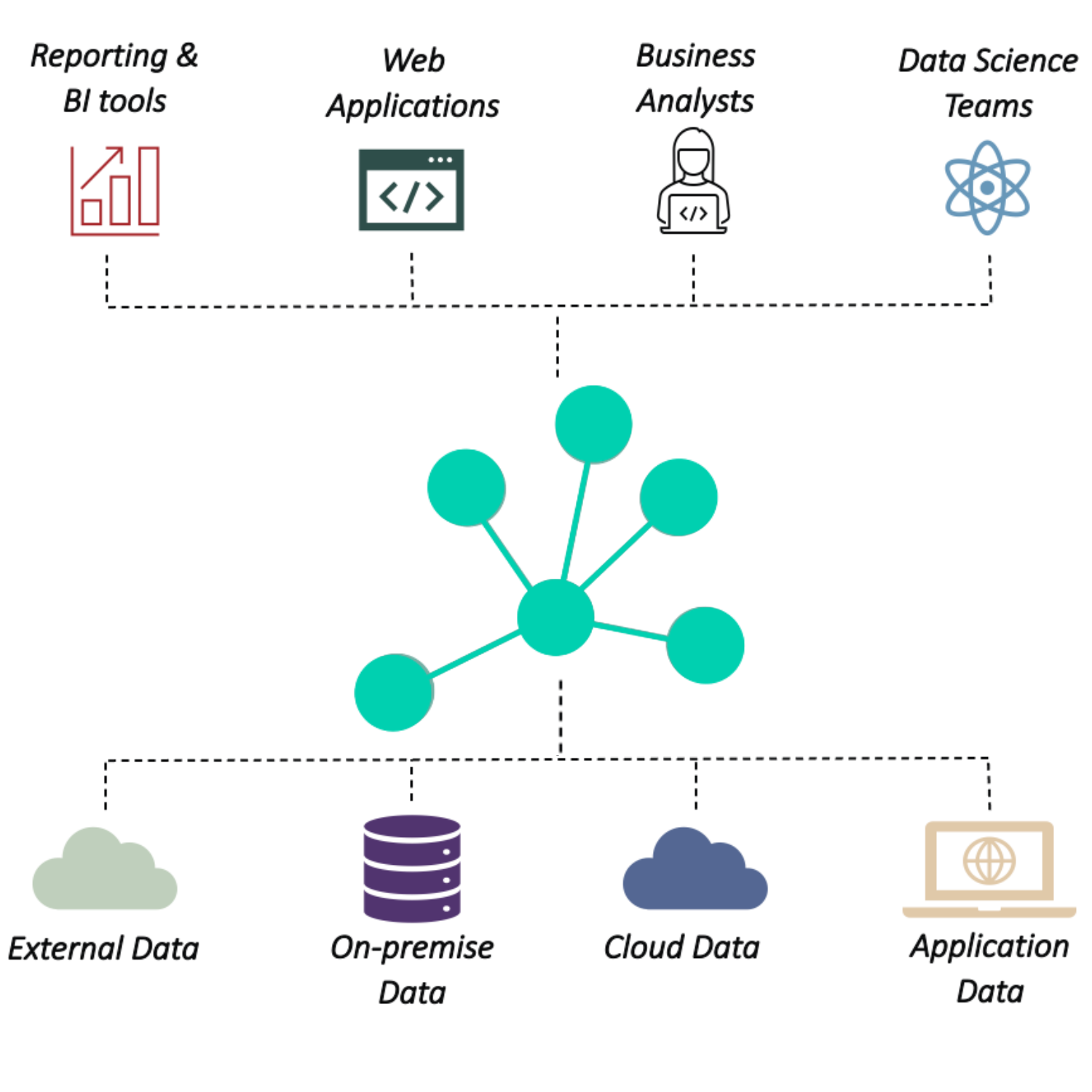
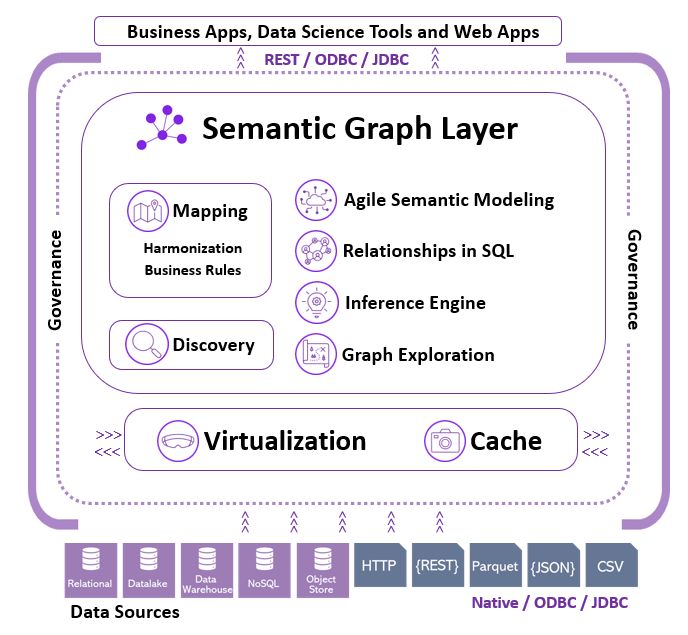
Model and integrate data using common concepts to unify meaning and align business metrics across data products
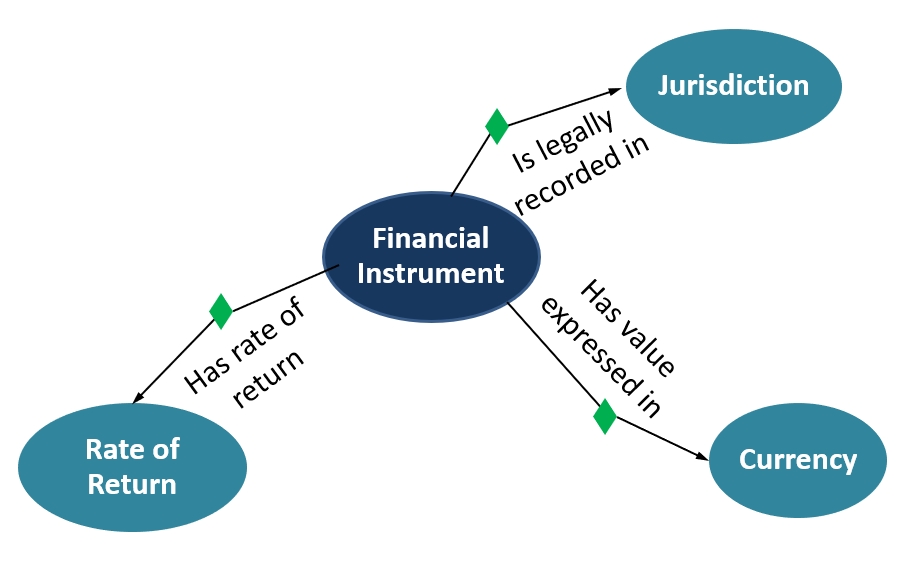
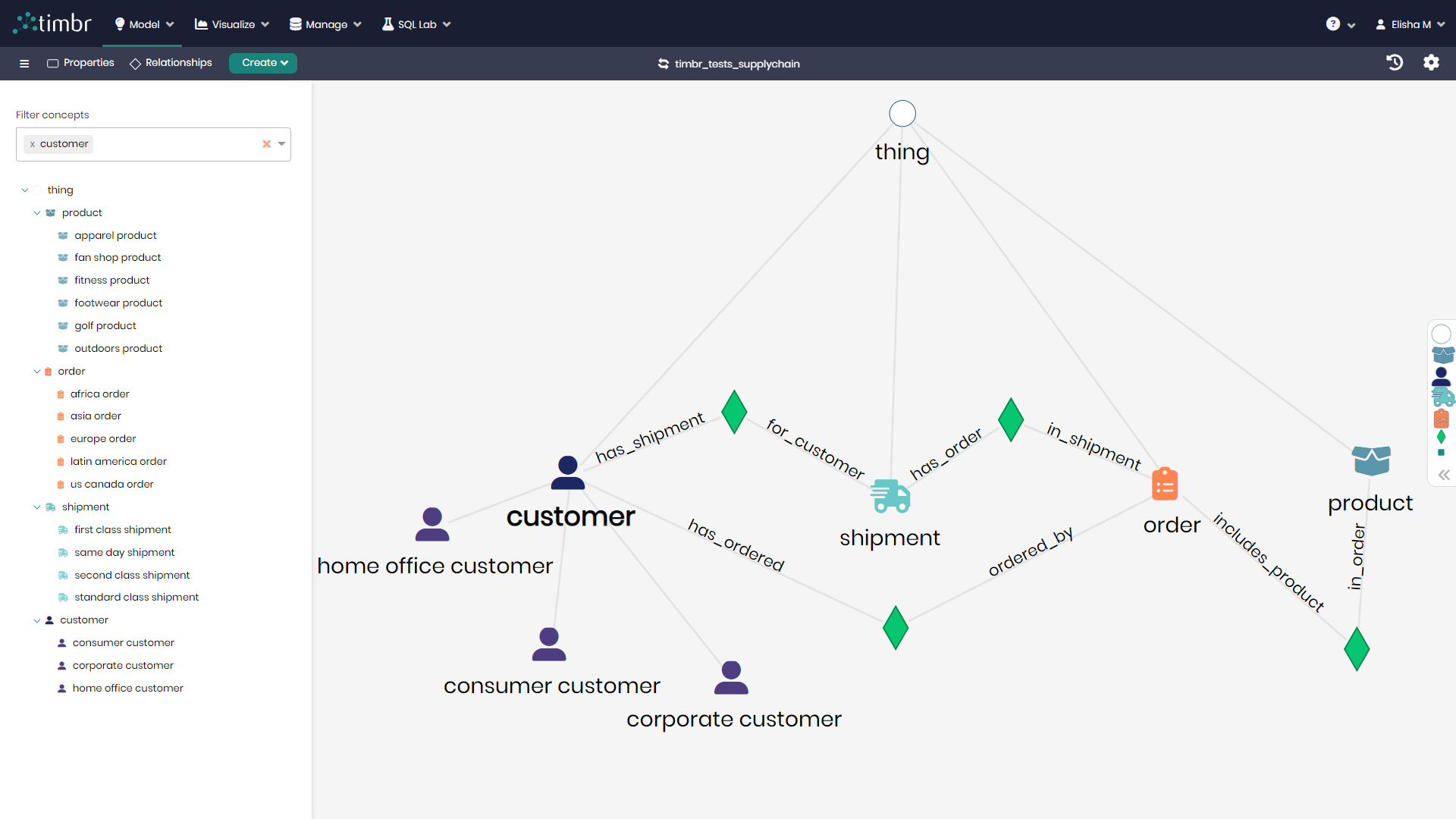
Semantic Relationships
Define relationships that substitute complex JOIN and UNION statements so queries become much simpler and shorter
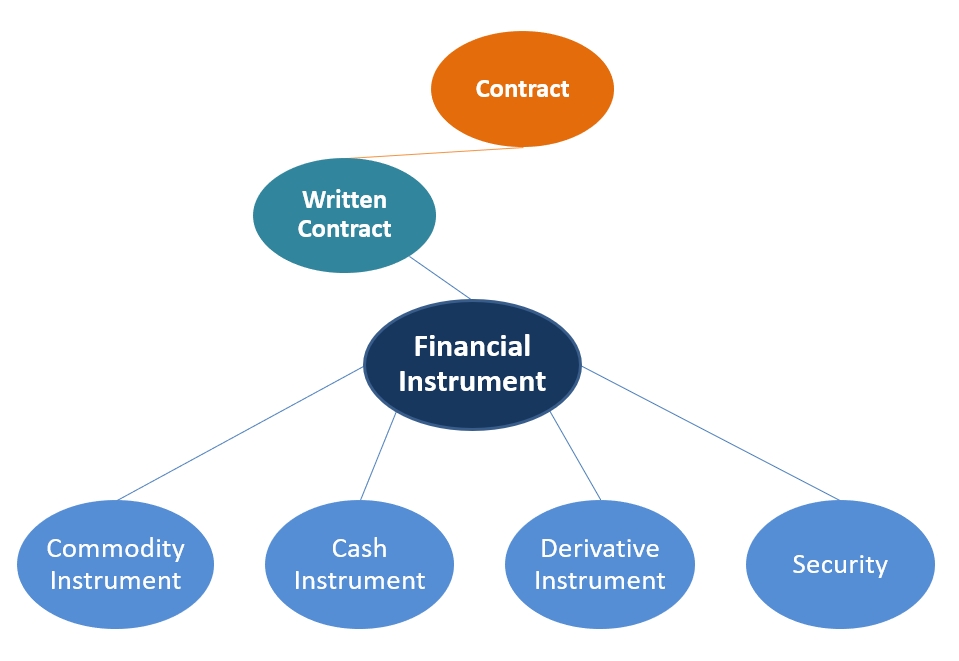
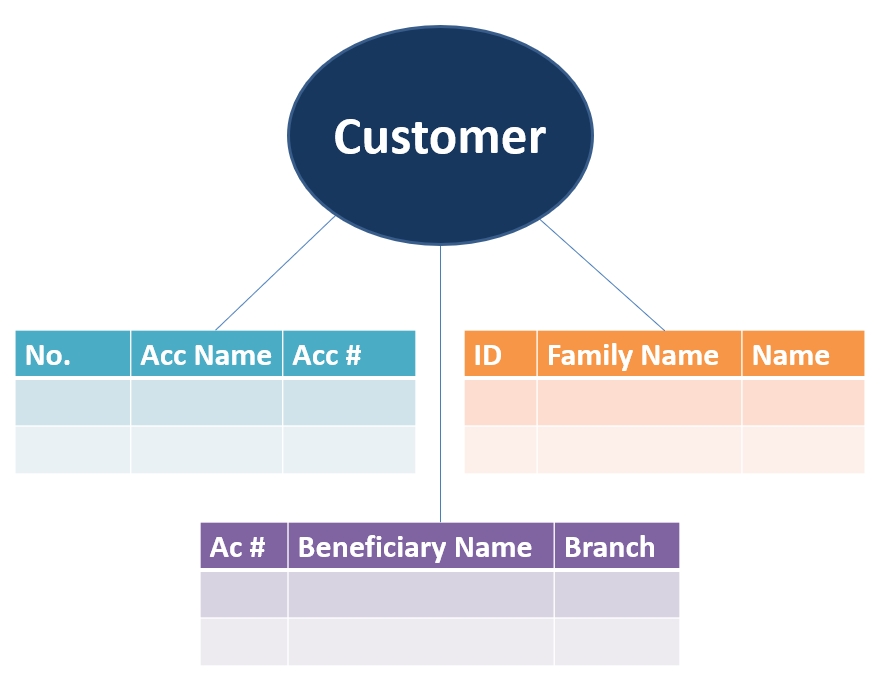
Hierarchies and Classifications
Organize concepts using hierarchies and classifications that provide better understanding of the data
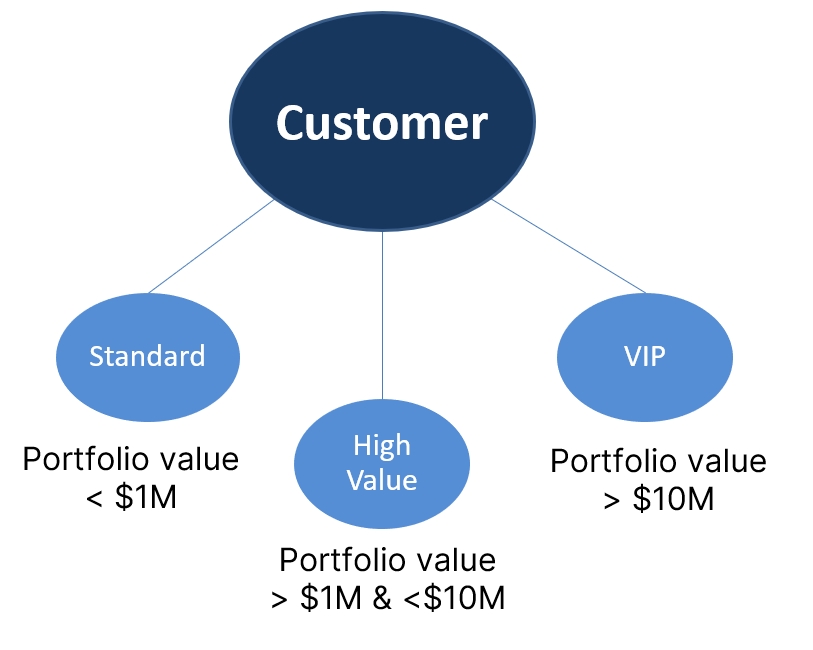
Logic
Use SQL logic and math operators to filter the mapped data to a concept to facilitate and accelerate consumption
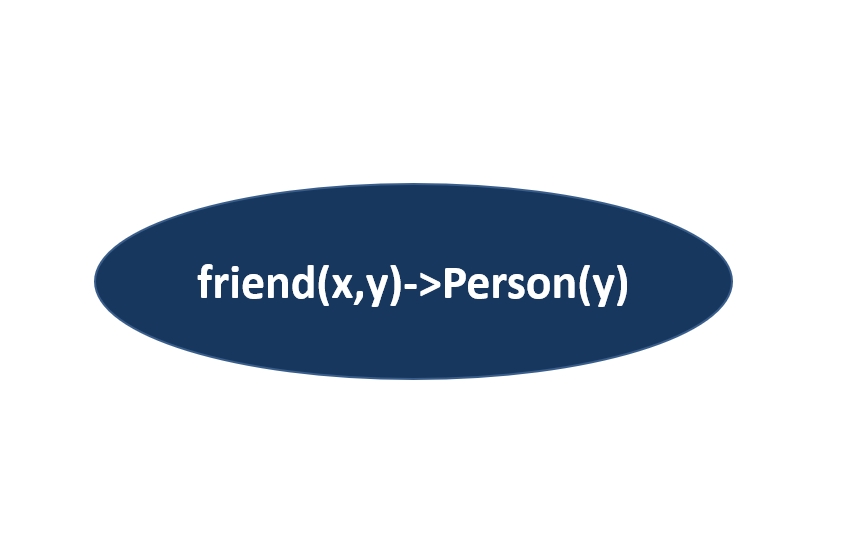
Inference
Derive new knowledge from existing knowledge based on relationships and a formal set of inference rules